Hi, I'm Ryan, CTO at airCloset.
In Part 1, I wrote about unifying 46 repositories of production code into a single knowledge graph via static analysis. The graph itself got built, but I closed the post with four open issues: no semantic search, node explosion, having to open the file to actually know what a function does, and the cost of writing a new parser every time a new boundary pattern showed up.
This Part 2 is about how I solved the first one — the entry-point problem (no semantic search). The other three are left exactly as Part 1 described them — I'll come back to them at the end, together with the new issues that surfaced once the entry-point problem was out of the way.
The reason to start with the entry-point problem is simple: if the graph exists but the only way to reach it is grep, the model ends up inferring anyway. The whole point — "give the model verified facts, not inference" — falls apart. So the entry-point problem had to be solved before the others.
The Hint Was in db-graph
Months earlier, I'd already solved the same structural problem in a different domain — the db-graph project.
Internally, we had a large number of DB tables spread across many services, and no single person had the full picture. Different people knew different pieces well, but the whole map didn't fit in anyone's head. So I built db-graph: extract schemas statically from ORM definitions, generate per-table descriptions with Gemini, embed them as 768-dimensional vectors in the graph, and make the whole thing semantically searchable in natural language.
At the time of that article it covered 991 tables. Today it spans 21 schemas / 1,133 tables / 10,815 columns, and finding data in natural language without knowing table names is just how people work now.
The pattern that proved out there:
Static-analysis graph + AI-generated context = natural-language semantic search works.
Bringing the Same Pattern to code-graph
If it worked for db-graph, it should work for code-graph. The moment that thought landed, I noticed something:
code-graph already contains "DB table nodes" as boundary nodes — they're one of the boundary node types I covered in Part 1.
So if I just join code-graph and db-graph, code-graph automatically inherits db-graph's semantic context. Without writing a single annotation, the existing assets alone make the graph meaningfully richer.
That's where the idea of "joining graphs" first came up — not treating each graph as its own island, but designing the joins between them.
But API / Event / Page Still Need Meaning — and Annotating Every Function Is Off the Table
Joining db-graph took care of DB context. But the remaining boundaries (API / Event) and the graph's entry-point type (Page) still need meaning attached. Static analysis alone can't pull intent out of those, so context has to come from somewhere else.
The choice was clear: write the intent directly into the code via annotations (the same approach used by cortex's internal knowledge graph, which I covered in AI Harness Series, Part 2).
The catch: you can't annotate all the functions across 46 repos. There must be tens of thousands of them. Asking established teams running an existing production codebase to retroactively annotate everything is just not realistic.
But here's the second realization:
What matters is just the boundary nodes. So if I only annotate around the boundaries, that's enough.
When an AI agent asks "what breaks if I change this code" or "what other repos call this API," what it needs isn't a per-function logic explanation. It needs boundary intent — what is this screen for, what does this API return, what milestone in the business does this Event mark.
= Minimum annotations, maximum meaning. That became the heart of the design.
Designing the annotation graph
Putting it together (internally we call this annotation graph service-product-graph, or SPG):
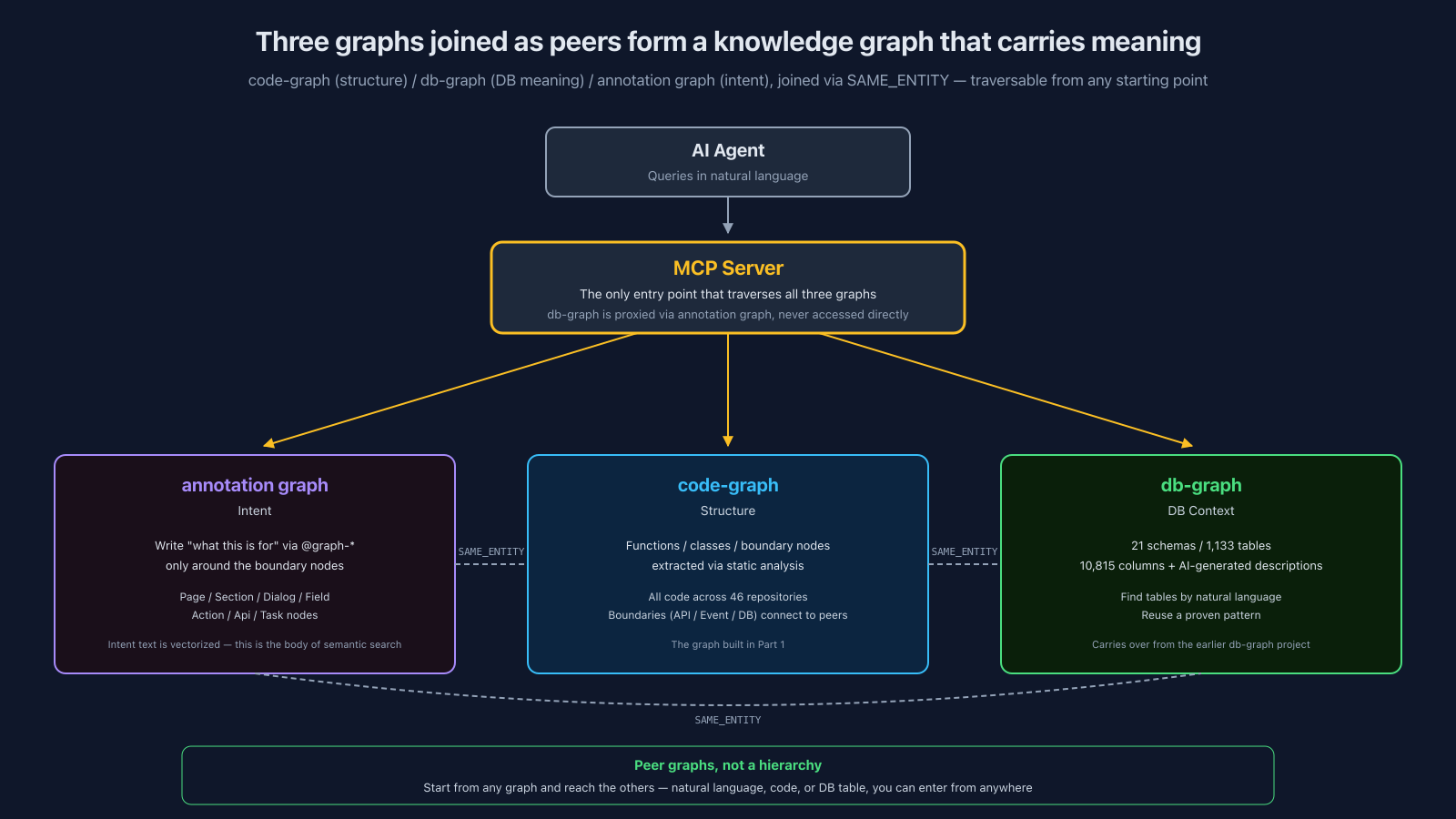
Three graphs sit as peers, joined by SAME_ENTITY edges. There's no hierarchy — you can start from any graph and reach the others.
- code-graph (structure) — functions / classes / boundary nodes from static analysis (46 repos)
- db-graph (DB context) — 1,133 tables, semantically described
- annotation graph (intent) —
@graph-*tags written only around boundaries
The entry point for AI agents is a single MCP server that traverses all three graphs. AI agents never hit db-graph directly — the annotation graph's MCP server proxies db-graph calls on their behalf.
The annotation graph has 7 node types: Page / Section / Dialog / Field / Action / Api / Task. The early version was screen-focused and called screen-graph, but once it grew to cover backend Api / Task, it was renamed to service-product-graph.
An Annotation Example
Here's what an annotation looks like (fictional, but close in shape to the real ones):
/**
* @graph-page /home
* @graph-business Main screen. Members can see what they're currently renting, buy items, and initiate returns.
* @graph-label Home Screen
* @graph-has-section banners, wearing-items, wearing-return, delivery-status
* @graph-has-dialog buying-modal, return-modal
* @graph-navigates-to /return-procedure, /checkout, /my-karte
* @graph-calls GET /api/v1/wearing
* @graph-reads admin_delivery_orders, admin_rental_items
* @graph-flow styling-loop
* @graph-status monthly-member
*/Two things matter here:
@graph-businesscarries the intent text (in our actual codebase it's written in Japanese). This is exactly what gets vectorized — it's the substance of semantic search.@graph-flow/@graph-statuscarry where this sits in the member lifecycle (free signup → monthly subscription → styling loop → cancellation, etc.) and which member segment it's for. They add a second dimension of meaning: "this screen shows up inside the styling loop for monthly members."
There's also @graph-case (the conditional pattern tag that test cases derive from), but that's for another time.
Running Annotations Without Interfering With the Day-to-Day Dev Workflow
This is where it gets practical.
Once I committed to building annotation graph, here were the constraints:
- Engineers run normal product dev with human code review
- AI review isn't wired up on every repo yet — cortex's fully automated review (covered in AI Harness Series, Part 6) only works inside the cortex monorepo
- Asking humans to review annotations on top of their normal review load is a non-starter
- Even a split like "humans review the code, the AI reviews the annotations" inside the same PR mixes two review streams together and just confuses everyone
In other words: don't mix humans and AI inside the same PR.
The solution was to physically separate annotations onto their own branch.
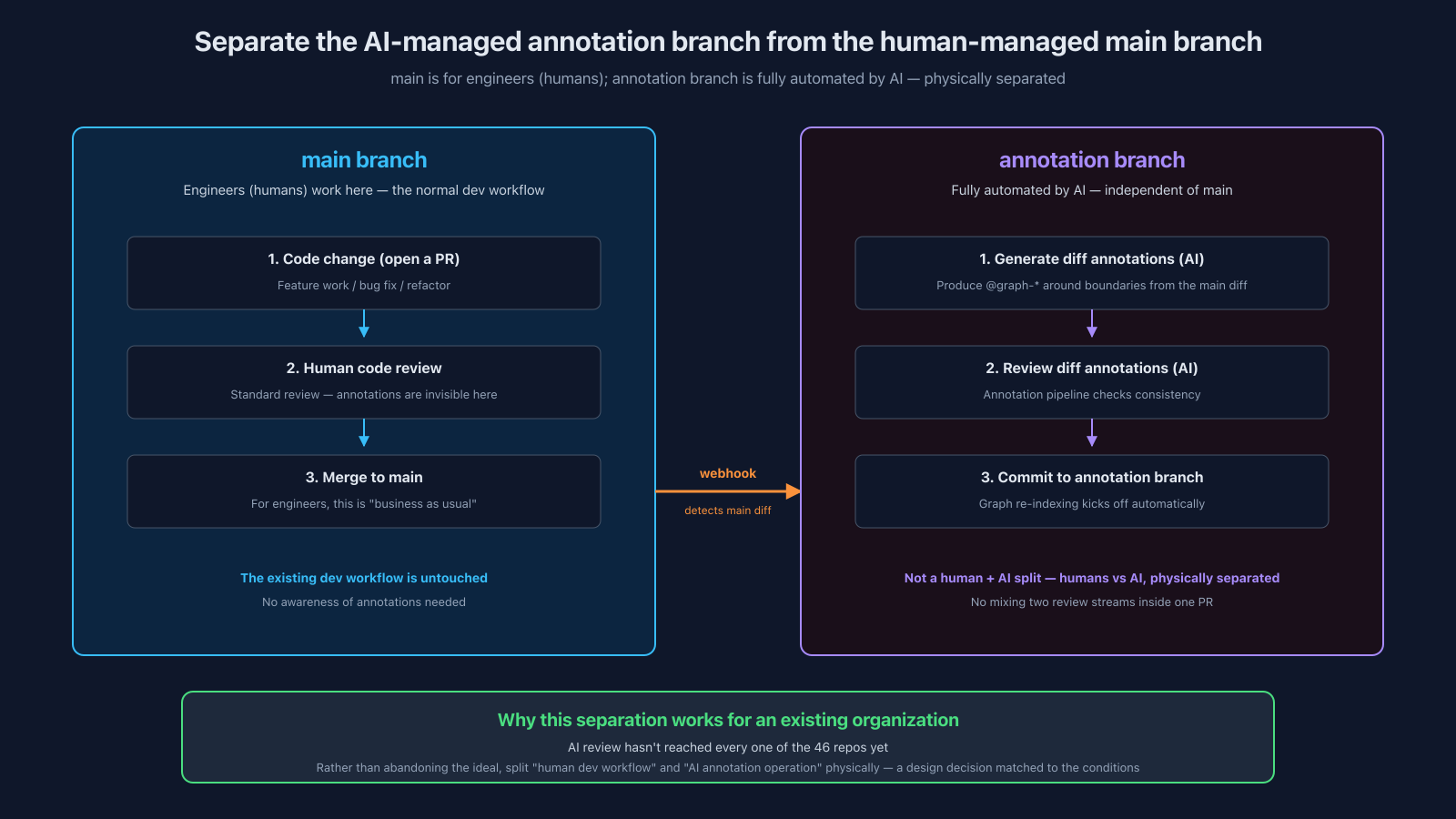
- Leave main untouched; engineers' normal flow stays exactly as it was
- Stand up a separate annotation branch that's the AI's exclusive territory
- When main changes, a webhook fires
- The annotation branch handles generating the diff annotations and reviewing them — the AI does both, end-to-end
- From the engineer's side, they only touch main and don't even need to know annotations exist
This is the "every line of code passes through an AI gate" ideal from AI Harness Series, Part 6, adapted to the constraints of an existing organization. cortex (the internal AI platform) is a monorepo I assemble from scratch, so "every commit passes the AI gate" actually holds there. For the 46-repo production system, that precondition doesn't hold. So instead of giving up on the ideal, I split it: engineers' workflow on one branch, AI's annotation workflow on another, both running in parallel.
Protecting Cross-Graph Consistency With an SLO
Just running the annotation pipeline doesn't guarantee the quality of the joins between the three graphs (code-graph / db-graph / annotation graph). So there's a set of SLOs that automatically check the consistency across the entire graph.
The main rules:
- API chain connectivity — at least 95% of
HANDLES_APIhandlers must have downstream function calls (= no handlers that receive an API and then do nothing) - DB access completeness — at least 80% of DB read/write edges must be joined to db-graph column nodes (= code-graph's DB boundaries are connected to db-graph's meaning)
- Event field resolution — at least 70% of Event edges must carry field-level information
- No ambiguous edges — name-resolution-ambiguous edges must be 0 (severity: error)
These are really just a naive question — "shouldn't the boundaries connect to each other?" — turned into an SLO. If anything drops below threshold, an alert fires, and the trustworthiness of the whole graph gets defended every day.
The daily boundary-analysis cron from Part 1 (5% connection-rate drop = alert) was code-graph-only. This is a cross-graph SLO — it guards the joins between graphs themselves. Add a parser to one repo, write a new annotation, change a schema — whatever happens, by the next morning a quality drop in any join becomes visible.
Joining the Static Graph and the Annotation Graph via SAME_ENTITY Bridges
I've been writing "join" casually, but the actual joining wasn't that straightforward.
Static-analysis API / Page / Task nodes and annotation graph API / Page / Task nodes are created as separate nodes. They mean the same thing, but their names / paths / identifiers don't match by themselves — there's nothing automatic about lining them up.
To connect them, we generate a separate edge type called SAME_ENTITY. There are three bridges:
- API bridge — API path normalization with a 4-stage fallback
- Per-repo prefix conversion (e.g., normalize console-side
/console/api/to/api/) - Version stripping (
/v1.x/→/) - Parameter normalization (unify
/:id,/{id}to/:dynamic) - Exact match → tolerate trailing
?→ strip trailing:dynamic?→ finally fall back to a dynamic-dispatch boundary:dynamic, loosening progressively
- Per-repo prefix conversion (e.g., normalize console-side
- Page bridge — 6 strategies applied in priority order (URL direct match, component path match, itemId match, PascalCase normalization match, parent-directory linking, strip dynamic segments and match parent URL)
- Task bridge — 8 per-repo patterns
There was also one operational footgun. The first implementation used INSERT NOT EXISTS to avoid duplicates. But BigQuery's streaming-buffer visibility lag let duplicates slip in — in one repo the edges doubled from 106 to 214 overnight. We fixed it by rewriting to MERGE INTO to make the operation idempotent.
The Result: Entering the Graph from "the subscription-fee calculation"
With all of this in place, the entry-point problem from the end of Part 1 was finally solved:
"the subscription-fee calculation for members seems off"
Throw this natural-language query at annotation graph and vector search returns the related nodes (Page / Api / Function / DB table) as facts. From there, SAME_ENTITY takes you over to code-graph functions, including callers and callees in other repos. From the DB boundaries in code-graph, you can cross into db-graph and pull the relevant columns.
The entry point can be anywhere — "what calls this table?" starts from db-graph, "what's the blast radius of this function?" starts from code-graph, both walk the same connected network. From a single natural-language query, or from a specific node, you can now traverse all three graphs and get every relevant piece of code plus every relevant DB schema.
The Part 1 lament — "the graph is there but the entry point is missing" — could finally be put to bed.
Real Usage Numbers
From 2026-04-16 (first production deployment) to the time of writing — about 2.5 months — the annotation graph's MCP server has handled ~50,000 calls from ~73 users. The breakdown:
- Engineers (PI Division + QA + relevant engineering teams) — ~47,000 calls / 51 users
- Non-engineers (stylists / customer support / mall operations / executives / administration) — ~2,800 calls / 21 users
The interesting line is the second one. "Search the codebase in natural language" is usually an engineer's tool — but once the entry-point problem was solved, people outside engineering started using it too, asking things like "how does this feature actually work?" or "what's in this DB?" in their own words.
This is adjacent to the "non-engineers writing specs with AI" trend I covered in AI Harness Series, Part 5 — a graph that can be queried by meaning starts to matter org-wide. Call volume is overwhelmingly dominated by engineers, of course. The interesting thing is the range of job roles starting to pick it up. That's the real impact of solving the entry-point problem.
MCP as the Single Front Door
The MCP server is the cross-graph entry point. It exposes six tools — service search / service detail / API detail / data-flow tracing / impact-radius tracing / business-rule full-text search — and that's the only entry point AI agents ever touch.
One design choice worth calling out: AI agents never talk to db-graph directly. The annotation graph's MCP proxies db-graph calls. From the agent's side, the mental model stays simple: "ask one MCP and get everything back."
That makes the full chain — "Screen → API → Code → DB → Column" — traversable in a single MCP tool call.
April–May Timeline of Trial and Error
Same approach as Part 1 (pulling commits from Jan–Mar). For Part 2, the key commits are from April–May.
April: Expansion and the First Bridges
- 2026-04-14 ─
refactor(graph): rename screen-graph to service-product-graph— declaration that the scope expands from screen-only to whole-service - 2026-04-15 ─
feat(graph): add Api and Task node types to service-product-graph parser— Api / Task node types added - 2026-04-15 ─
feat(mcp): add cross-graph tools to service-product-graph MCP— cross-graph tools land (the single front door across all three graphs) - 2026-04-15 ─
feat(graph): add SAME_ENTITY bridge edges between service-product-graph and code-graph— first bridges - 2026-04-18 ─
feat(graph): resolve Redis keys to code-graph boundary nodes— boundary resolution through Redis - 2026-04-19 ─
feat(service-product-graph): add EventBridge EMITS_TO support + SAME_ENTITY bridge - 2026-04-20 ─
feat(code-graph, service-product-graph): improve SAME_ENTITY boundary bridge coverage— 4-stage fallback locked in - 2026-04-21 ─
feat(auto-review): SPG annotation auto-maintenance pipeline— AI auto-maintenance pipeline (= what Part 1 hinted at with "humans alone can't, but AI can") - 2026-04-22 ─
feat(service-product-graph): add Task SAME_ENTITY bridge to code-graph— all three bridges in place
May: Stabilizing and Expanding
- 2026-05-01 ─ Annotation generation moves from local execution to a Cloud Run Job; operation stabilizes
- 2026-05-05 ─
feat(spg): add mall repos to SPG indexing— mall repos indexed - 2026-05-06 ─
feat(spg): add Go-aware parser— Go support - 2026-05-06 to 08 ─ Page bridge strategies expanded to six, connection rate hits 100%
What This Timeline Says
April 15 was the day "expansion + cross-graph tools + bridges" landed in close succession. Over the next week, "Redis / EventBridge / Task bridges / annotation auto-maintenance" stacked up week over week.
In particular, the annotation auto-maintenance pipeline on April 21 is where the "humans alone can't do this, but AI can" promise from Part 1 got cashed in. From that point on, annotation shifted from "humans grind through writing them" to "design the whole operation assuming AI writes them."
What Still Isn't Solved
Solving the entry-point problem didn't make everything clean. A few issues remain.
1. Maintaining Annotation Coverage
The frontend side is annotated heavily. Backend / Go / batch are still thin. Some nodes will always be missing annotations — that's structural, and you can't drive it to zero. It's an ongoing operational issue.
2. Bridge Mis-Joins Aren't Fully Eliminated Structurally
The Page bridge in particular has cases where multiple annotation Pages map to the same boundary — that's structural and unavoidable. Adding more strategies got coverage to 100%, but guaranteeing "every join is correct" 100% is hard.
3. No Dynamic Analysis
The graph only carries the fact that "this edge exists statically." How often that edge actually gets used in production isn't recorded. Piping production execution counts back into the static graph and surfacing dead-code edges as a separate signal — that's still untouched.
4. Onboarding Cost When a New Repo Joins Production
Every time a new repo enters production, the bridge normalization rules and per-repo patterns need adjusting. This is the annotation-graph-side version of Part 1's fourth issue (the cost of adding a new parser for every new boundary pattern).
Closing: Not "Thrown Away," but "Evolved"
In Part 1's closing note, I touched on the fact that the cortex side (the internal AI platform) bailed out of the code-graph approach early and bet on an annotation-based knowledge graph instead. The bail-out was fast enough that calling it "thrown away" wouldn't be wrong — but looking back across this whole series, the more accurate word is "evolved."
What it evolved into, in the end, is three graphs joined as peers:
- code-graph (structure)
- db-graph (DB context)
- annotation graph (boundary intent)
Joined by SAME_ENTITY, served to the agent through MCP. The thing static analysis alone couldn't deliver — querying by meaning — became workable by reusing the db-graph success pattern and adding minimal annotations only at the boundaries.
And one more framing: paired with the AI Harness Series, Parts 1–6, this series sits as:
- AI Harness series — how to live with AI when you're assembling the system from scratch yourself
- code-graph-deep-dive series (Part 1 + Part 2) — how to live with AI inside an existing organization's running production system
= the same philosophy (design without trusting AI), implemented under two different sets of constraints.
Thanks for reading this far.
comments (0)
no comments yet.