Hi, I'm Ryan, CTO at airCloset.
Disclaimer: "cortex" in this article is the internal codename for an AI platform built in-house at airCloset. It is unrelated to existing commercial services like Snowflake Cortex or Palo Alto Networks Cortex.
Across the five posts of this series I've worked through how cortex's harness is put together, one piece at a time: the overall picture, the knowledge graph, Auto Review, Self-Healing + Recurrence Prevention, and non-engineer PRs. Having walked through all of them, I want to step one level down for the wrap-up. Why am I building this thing in the first place? That's what this post is about.
The five posts might look independent, but the root is one thing, and the series doesn't close cleanly without that one thing being put into words. Together with the philosophy, I want to look back at the failures that don't show up when you only write about what worked — what I threw away, where I tripped — as a reference point for anyone trying something similar.
Series Index
| # | Theme | Key scene | Article |
|---|---|---|---|
| 1 | Series intro: cortex's harness | PRs auto-merge / incidents self-heal before you notice | ai-harness-intro |
| 2 | Product Graph (cpg) | Code, docs, DB, infra unified into one graph | cortex-product-graph |
| 3 | AI PR review | webhook → AI review → auto-fix → squash merge | cortex-auto-review |
| 4 | Self-Healing + observability + auto-added guardrails | Alert → AI investigates → fix PR + new lint/type gate → auto redeploy | cortex-self-healing |
| 5 | Democratizing the maintenance phase | Domain experts open PRs to production; the harness owns the quality gate | cortex-non-engineer-prs |
| 6 | Series wrap-up | The underlying philosophy plus a retrospective on the failures and lessons | This post ← you are here |
Origin — What I Was Thinking About in 2025
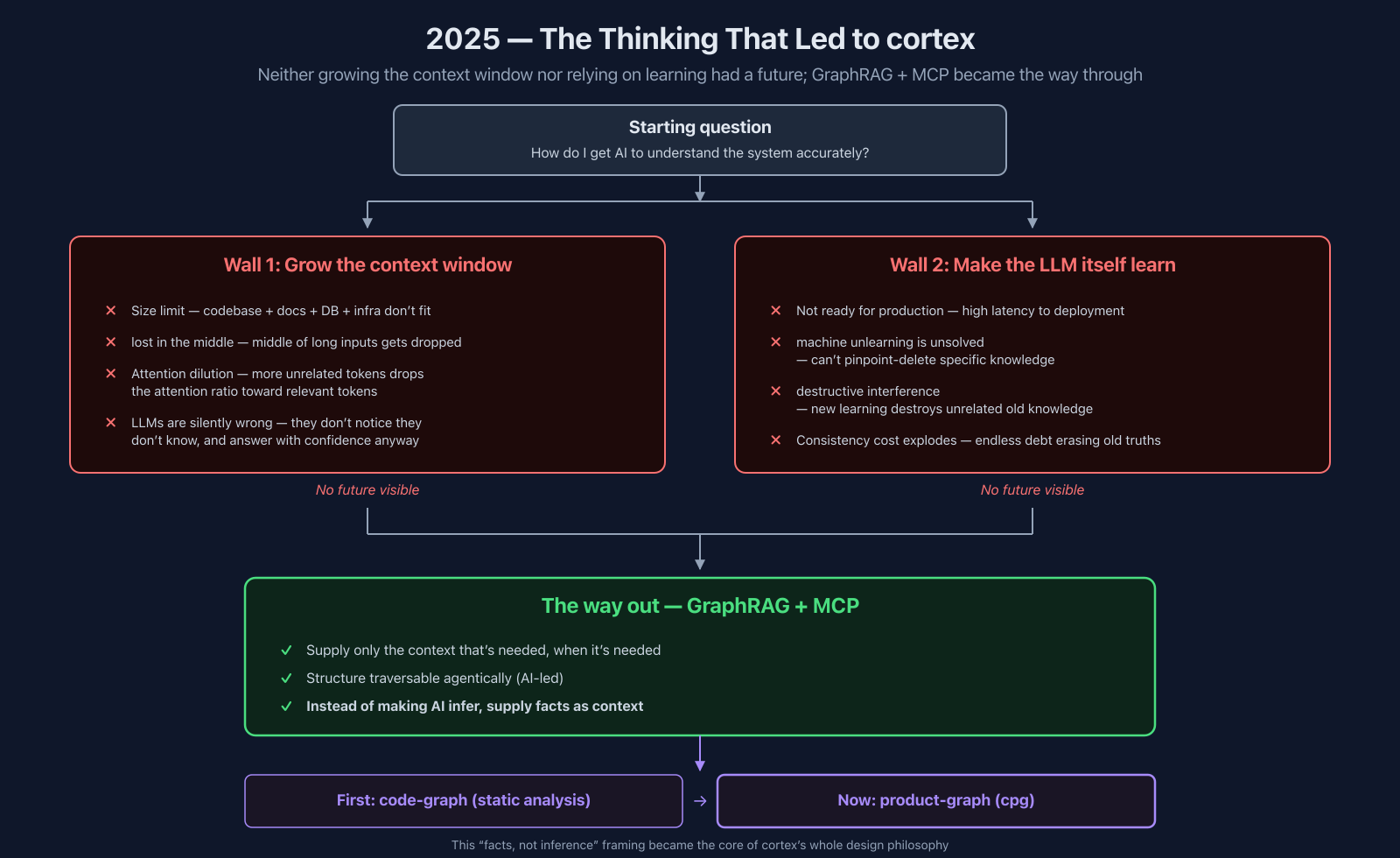
When I started building cortex, there was one question I wanted to answer:
How do I get AI to understand the system accurately?
If AI could understand the system accurately, then PR review, bug investigation, and fixes could all be delegated, and even non-engineers could open up their own development. Conversely, as long as I was stuck on "understand it accurately," everything downstream was sitting on unstable ground. So I spent a lot of time on the prerequisite layer before any of the individual mechanisms.
The two obvious approaches both hit walls.
Wall 1: The Context Window Limit
The first reflex is "just give it all the information it might need." Stuff the codebase, docs, DB schema, infra definitions all into the prompt, and AI gets the whole picture.
That fails on size. Codebase + docs + schemas + infra at our company doesn't come close to fitting into any realistic context window.
"Surely context windows will keep growing, and this'll work eventually?" — the more I thought about it, the less of a future I saw in that direction.
Even with a model whose context window is very large like Gemini, behavior gets unstable when you push it close to the limit. Middle information gets dropped, irrelevant tokens skew the conclusion sideways. This isn't a model-selection problem; it's a structural attention problem. The more unrelated tokens you mix in, the more the attention ratio toward relevant tokens drops mechanically. This is the documented "lost in the middle" phenomenon (information placed at the start and end of long inputs gets used; information placed in the middle is effectively ignored), and stuff the context window full and you routinely end up in a state where the information you thought you handed over isn't actually visible to the model.
"Lost in the middle" itself may get mitigated as long-context models improve, so I treat it as empirical supporting evidence rather than the core argument. The real wall is the recursive one beneath it: even if "size" is solved, you immediately need a higher-level context to judge which tokens are necessary and which aren't. That problem is recursive and can't be resolved by context window size, in principle. Information has to be structured, or AI doesn't make correct judgments. That's true of humans too — but humans are a notch better off, because LLMs don't notice they don't know, and they answer with confidence anyway. Silently wrong is worse than visibly stuck.
The keep-growing-context-windows path didn't have a real resolution in sight.
Wall 2: Don't Lean on Learning Either
The other obvious move is to make AI itself learn. Fine-tune per organization, teach it our codebase, our docs, our business. I considered it. Currently not doing it.
Two reasons. One: getting learning into actual production was still research-phase (in 2025 then; still in 2026 as I write this) and the road to real deployment is still long. The other is thornier: even if you could learn it, "forgetting" is extremely hard.
A business system has to reflect "the current truth." When the design changes, the DB schema changes, the business rules change, you want to actively erase old knowledge. But "delete just this piece of what's baked into the LLM weights" is unsolved at the research level — there's even a field name for it, machine unlearning, which tells you how hard it is. And on top of that, teaching the model new things also destroys unrelated existing knowledge (called destructive interference / catastrophic forgetting). Lean on learning and both hit at once: the cost of keeping things consistent explodes.
Rather than treating "doesn't learn" as a downside, I came around to: because it doesn't learn, swapping out the external knowledge is enough to reflect the current state, and the consistency story is much simpler. That was the call at the time.
The Way Out — GraphRAG + MCP
With no future in the context-window direction or the learning direction, I came across the GraphRAG concept.
GraphRAG itself is widely discussed elsewhere; for me, what it meant was the framing: "supply only the context that's needed, at the moment it's needed." Combined with MCP (Anthropic's protocol for connecting LLMs to external tools), AI can go fetch what it needs on its own.
What was decisive was that this structure lets AI traverse the graph agentically. Rather than "read everything and find related parts by inference," AI gets to the node it needs and pulls the fact out. Which leads to:
Instead of making AI infer, supply facts as context.
That one sentence became the core of cortex's entire design philosophy.
The first thing I built was a static-analysis-based code-graph, which I then threw away after trial and error, and arrived at the annotation-based product-graph (cpg) — details in the trial-and-error section.
I Don't Trust AI to Begin With
The origin section in one line:
I don't trust AI to fill in the blanks for me.
"Don't trust" here is not the same as "have no faith in." This isn't doubting Claude / GPT / Gemini's generation quality. What I mean is:
- It doesn't know context it wasn't handed.
- It doesn't, on its own and without being told, produce the ideal state.
The first one is a truth no amount of model progress will change. Architecturally, LLMs can't know things that weren't in the training data and aren't in this session's context. "Surely smarter models will pick up on it" — I don't think that future is coming. Smarter is a real direction; smart alone doesn't compensate for not knowing.
The second one is about responsibility, and humans owning it. AI can't decide on its own what "ideal" means. When it tries, it lands on a generic best-practice answer slightly off from the actual situation. Ideal depends on the business, the organization, the moment in time — none of which is visible to AI unless a human verbalizes it and hands it over.
So that conviction is not underestimating AI's capability; it's a design decision to not let AI auto-complete the prerequisites.
Mastering AI is not about giving it freedom — it's about confining its output to a predictable range.
The mechanism for confining it is the harness this series has been describing.
So I Build Harnesses to Hold AI to Determinism
Reading each post through the lens of "don't make AI infer; lean on determinism" surfaces that the five of them are all the same conviction showing up in different layers.
Part 2 — Knowledge Graph: Instead of making AI search the codebase, this mechanism tilts toward making the codebase legible. With @graph-* annotations, code / docs / DB / infra are unified into one graph, so AI doesn't have to grep + infer to find related parts. This is the direct implementation of "supply facts as context" from the origin section. → cortex-product-graph
Part 3 — Auto Review Dimensions: Nine review dimensions (responsibility / severity / type SSoT / etc.) are fixed in advance. When AI does the review, what to check isn't something it gets to infer. "Looking at the PR as a whole" gives AI too much room for inference, so dimensions are split and each is judged as its own question. Dimensions = locked by the harness, evaluation = AI's job. → cortex-auto-review
Part 4 — Self-Healing + Recurrence Prevention: Alert → investigation → fix PR → redeploy. The flow itself is fixed. AI doesn't get to think through "how should we respond to incidents" each time. And Recurrence Prevention — adding lint / CI gates so the same trap can't be stepped on twice — is mechanical refusal at the gate, not trust-AI-not-to-do-it-again. Or put differently: I don't expect AI never to repeat a mistake. → cortex-self-healing
Part 5 — Non-Engineer PRs: If the harness weren't holding quality, business-side folks opening PRs directly to production wouldn't survive a single day. Conversely, with the three mechanisms above stacked up (context locked, dimensions locked, traps locked out mechanically), the person closest to the requirements can ship the change directly. The translation layer and the engineering priority queue disappeared as a downstream consequence of the determinism push. → cortex-non-engineer-prs
So what's covered across the five posts is "don't make AI infer; lean on determinism" implemented at different layers. The root is one conviction.
What "Don't Make AI Infer, Lean on Determinism" Actually Means
Let me sharpen this phrase that's come up a few times.
"Lean on determinism" does not mean "give AI zero room to infer." Code generation, judging review findings, hypothesizing root causes from error logs — these are domains where AI not inferring is the same as no work getting done.
Where I want to lean on determinism is in domains where variance isn't allowed. Specifically:
- Which part of the codebase to look at — don't have AI guess by analogy; pull it deterministically from the knowledge graph
- Which review dimensions to apply — don't let AI pick "the important-looking dimensions"; lock the dimension list in advance
- How to respond to incidents — don't make AI think through the workflow each time; fix the alert → fix PR path
- Not stepping on the same trap twice — don't ask AI to "try to be careful"; let lint / CI mechanically refuse it
What implements this line — where inference is allowed vs. where it isn't — is the harness. To borrow the metaphor from Part 5, the harness lays down rails you can't fall off. On top of the rails, AI runs free (inference works as inference); but it can't fall off the rails sideways.
Put differently, this is equivalent to the framing in Part 2 (cortex-product-graph): "where hallucination gets confined." Saying "no inference allowed" isn't quite right — the harness isn't a thing that makes hallucination go to zero. It's a thing that confines hallucination to places where hallucination is OK (i.e., the inference-allowed zone). The structure and facts about the codebase are pulled deterministically, so the retrieval process itself has no opening for hallucination; hallucinations on the judgment side get filtered downstream by tests / lint / dimension-by-dimension reviews. The places where hallucination is allowed and the places where it isn't are physically split by the harness. That's the continuation of the Part 2 framing.
Step back one more level and what the harness is really doing is shifting when inference happens. The annotations and descriptions on the graph were also written by AI originally — there is inference baked into them. But that inference is write-time — happens once, reviewed, then frozen — not read-time (happens every query, unverified at the point of use). The graph is frozen, reviewed inference, which is exactly why the read side can treat it as fact. "Leaning on determinism" can be rephrased as not letting unverified inference run on every query.

This is also the underlying basis for Part 1 (Series Intro)'s claim "models commoditize; harnesses differentiate." Model-side quality is converging across Claude / GPT / Gemini, but the harness is codebase-specific and business-specific, so this is where org-level differentiation actually comes from.
Worth flagging: the position of this boundary moves with model capability. As agentic search and reasoning get stronger, today's "must be deterministic" zone might be tomorrow's "inference is good enough" zone — and in fact cortex itself depends on AI's ability to traverse the graph agentically. But the boundary itself never disappears. How information is structured, where the line gets drawn between fact and inference — whether you hold that line explicitly as a design decision is what differentiates organizations, across every model generation.
A note: this framing isn't confined to cortex's harness. The same stance shapes db-graph MCP, the natural-language interface over internal DB schemas, and Sandbox MCP, which lets non-engineers safely publish AI-built apps. It's the through-line in any platform we build that's based on AI doing meaningful work.
One level more abstract: the individual features aren't where the value is. The value sits in the conviction itself. cortex / db-graph / Sandbox MCP are all that one conviction translated into our own use cases.
The way I think about "design":
Design is translating an abstract principle into a concrete implementation that fits your own use cases.
It's not drawing class diagrams, and it's not laying out architecture diagrams — it's the translation work of "how does this principle take shape under our business / codebase / constraints?" That's where each organization's distinctiveness lives, and that's the value that can't be copied.
Said the other way: another organization copying cortex's surface doesn't reproduce the substance. What gets asked of every org is how it translates this principle into its own use cases.
Trial and Error That Got Me Here
Everything I've written about above is the form that ended up working. Getting to that form involved a lot of throwing away. Two representative examples worth keeping on record, plus one shorter one.
I Spent Two Months on Static-Analysis code-graph, Then Threw It Out
The first thing I built was static-analysis-based code-graph: extracting AST data — imports, call graphs, type dependencies — and putting that into a graph DB. At a glance, the obvious implementation of "make AI understand the codebase."
Why two months? code-graph wasn't just cortex; it spanned our consumer-facing services and internal-system repositories too — over 40 repos in total (cortex being one of them). The mechanically-extractable AST data (imports / call graphs / type dependencies) was usable as-is via tree-sitter, but each repo had its own API endpoints / DB schema / event definitions / Pub/Sub topology, and extracting those boundary nodes (where an app meets the outside) goes beyond mechanical AST analysis and had to be implemented per-repo-type — that's where the time went.
So I spent two months out of the first three on this, and got something that worked end-to-end.
And then I threw it away.
Why: static analysis is great at capturing structure, but it can't traverse on intent or business context. Concretely, three things broke:
- No semantic entry point for search — if I want to query the codebase with "show me the function calculating member subscription billing," I can't get there unless I already know the function name or file. A graph built only from static analysis has no semantic-tag entry pointing to "what is this code for?"
- The graph contains only code — internal helpers / utilities / types / arguments all become nodes, so traversal from any function blows up within a few hops, dragging in helpers and primitives. There's no axis to filter on semantic relatedness
- What I actually wanted was code + DB schema + docs + infra on one graph — given a function, I want to pull, in one query, the DB tables it touches, the docs where the design lives, and the linked business requirement. A code-only graph just can't do that
→ I switched to the annotation-based approach (@graph-* JSDoc tags write the business intent into the code, and that gets unified with DB schema / docs / infra into one graph). Searchable semantically, and when you traverse, only related stuff comes back. That's the current product-graph (cpg). Don't drag sunk cost forward and you'll get to the final form — discarding two months of investment instead of trying to recoup it was the foundation for everything that came after.
Setting Coverage 90% as a Solo Target Broke the Implementations
Test coverage is still gated at 90%+ (as covered in Part 3). That part hasn't changed. But there was a period when Coverage was treated as a standalone target, and during that period the implementation visibly got worse.
Specifically:
- Heavy default-value use that hides branches:
function(input = {})style writes the missing-input branch out of the test path. Coverage goes up, protection against unexpected input is gone - Catch-and-swallow over throw: try / catch returning
null. Don't throw → no need to test "doesn't throw," and Coverage is satisfied. Invalid state silently propagates - Early returns that flatten too much: dump complex conditions through an "early return" escape. Tests pass; what should have been validation just isn't there anymore
Result: Coverage 90%, quality lower than before. When you look at Coverage alone, the shortest path to "satisfy it" is a weaker implementation that passes the tests.
Two lessons:
- Set a number as a target, and the number becomes the goal. Coverage is a "minimum floor" — not "a goal to hit"
- Don't evaluate any metric alone. Coverage has to be evaluated alongside responsibility separation / exception design / boundary value coverage / etc.
Then, as the follow-up: I added linting that mechanically closes off the routes that let you weaken implementations to satisfy Coverage. Two specific examples:
no-silent-catch: AST-level ban on empty catch and silent-handler patterns like.catch(() => null). Catch bodies have to have a function call (logger included) / re-throw / new / await — otherwise it's an error. Catches the "weaken throws to satisfy Coverage but lose observability in production" pattern structurally. The violation message routes you to@cortex/otel/loggerfor structured logging, so the chain through Cloud Run OTel → Loki / Grafana stays intactvitest-strong-matchers: bans weak matchers liketoBeTruthy/toBeDefined/toContain/toBe(true|false)/expect.any/expect.objectContaining. Catches "any assertion that passes" patterns at the AST level, and points you instead towardtoStrictEqual/toMatchInlineSnapshotthat pin down the full output. This is one notch above Coverage — a test quality concern — but it lines up because the same reflection applies: don't let a number become the goal
On top of that, cortex's testing guideline opens with "Coverage is not the goal, just a supporting indicator," and threshold-lowering / istanbul ignore workarounds get bounced as Critical in Auto Review. So even when Coverage is satisfied, "this is intentionally deleting a branch" / "this is swallowing the exception" comes back as a Major finding.
From the lesson "a single metric warps implementation," we descended through guideline that states the principle → lint that mechanically rejects → Auto Review that evaluates as a dimension before Coverage 90% finally functioned as the "minimum floor" it should have been all along. This too sits in the lineage of the Recurrence Prevention mechanism from Part 4 (so the same trap can't be stepped on twice).
Parallel Sub-Agent → Sequential Evaluation
Third: an internal-structure call about Auto Review. Distribute the 9 dimensions to parallel sub-agents and evaluate concurrently — the plausible-looking design ("parallel = faster, parallel should also hold quality") I tried first and ended up throwing out.
What actually happened: time, cost, and accuracy all got worse.
- Time got worse: each sub-agent has its own startup, its own context load, its own result aggregation overhead. "9-way parallel = 9x faster" didn't hold; there were even cases where sequential evaluation in one session ended up faster
- Cost got worse: each sub-agent loads PR diff + guidelines + related code independently — common context loads ran 9 times. Token consumption measured at just under 4x — not the naive 9x (the context other than diff is shared across many dimensions, which is what kept it from blowing up to a full 9x)
- Accuracy didn't hold: parallel sub-agents don't see each other's verdicts, so the same problem comes back as "APPROVE" from one and "REQUEST_CHANGES" from another. Duplicate findings show up too. Without a "what kind of PR is this as a whole?" pass to anchor on, dimensional findings drift toward local optima and the overall picture gets worse
Switching to sequential evaluation: same session goes through 9 dimensions in sequence, so context loads once, and each dimension's call has the previous dimension's verdict in front of it. All three — time, cost, accuracy — improve simultaneously.
Of course, sequential evaluation introduces order dependence between dimensions — earlier verdicts can shape later ones. That's a real trade-off, and I accepted it knowingly. Inter-dimension consistency at the cost of some order sensitivity is more useful as a 9-dimension review than fully independent dimensions that contradict each other.
The takeaway: the distributed-systems intuition that "parallel = faster, parallel = quality holds" breaks its own assumptions in an AI harness. Unlike parallelizing across CPU cores on your machine, with AI the context isn't shared memory; it's per-process state. Sequential evaluation in one session ends up better on speed, token efficiency, and inter-dimension consistency at the same time — a structural property that's easy to miss at design time.
What This Section Is Really Saying
The form I've described across the series is the result of a lot of trial and error. Not starting with the right answer and laying it out from there. The decisions of throwing things away with sunk costs included, the trap of letting a metric I chose turn into the goal, the distributed setup that looked natural but worked against me — those are the things I walked through before landing at the current shape.
Not easy. I don't pretend it was. But if you do walk through it, real results follow — that's the honest read on it now.
Closing the Series
What I most wanted to communicate across these six posts comes down to one thing:
AI coding is not about "how to use AI" — it's about designing the environment AI runs in.
Or, put another way:
AI isn't something to trust. It's something to design.
Assuming a large codebase: prompt engineering / model selection / tool selection — each matters individually, but polishing them alone doesn't get you to auto-merging PRs, auto-healing incidents, or non-engineer development. Getting there requires building a codebase / business flow / observability / repair cycle where AI doesn't need to infer. That's not an individual AI skill — that's an environment-design problem (conversely, for a small project of a few dozen files, today's AI models work fine standalone. Harnesses become essential when scale exceeds what one person can hold in their head.).
And the conviction at the root of environment design is, repeating myself, "I don't trust AI to fill in the blanks for me" — looking the reality in the face that context that wasn't handed over isn't known, and the ideal state doesn't happen without being told. Once you accept that premise, what to build clarifies naturally.
Looking back, four decisions ended up being the ones that mattered:
- Locked the conviction first: putting words to the root ("AI isn't something to trust") gave priority order to every mechanism. If I'd started from technique, I don't think I'd have made it to the current form
- Invested with throwing-out as the default: like I did with code-graph at the two-month mark, I went into things with "throwing this out is OK." Drag sunk cost forward and you can't move forward
- Refused standalone numerical targets: the moment a metric like Coverage 90% becomes the goal on its own, implementations warp. Designed the system so it gets evaluated alongside other dimensions
- Designed for "no inference," not around AI's capability: I prioritized building structure where AI doesn't have to infer, instead of relying on what AI can do. That's what made the system stable end-to-end, I think
If even one of these is useful to someone starting on something similar, that would be great.
Afterword — Where Engineering Careers Are Heading
Slipping off the wrap-up topic — this is something I've been turning over recently, written here in a "loosely held thought" tone, so feel free to skim.
As harnesses mature, I think engineering work splits along two directions.
One direction is value creation from problem identification and business design. In the world of Part 5 — where non-engineer PRs work — "writing code" stops being scarce, and the actual scarce thing becomes the ability to define what to build. The person closest to the requirements (a PMO, a business manager, a domain-deep engineer) ends up driving Claude Code through to the merged PR themselves. This direction looks less like "engineer" and more like a business designer who moves between domain and implementation.
The other direction is building the foundation that lets all of that happen safely and quickly. Non-engineers can open PRs to the production repo only because the harness underneath holds quality — knowledge graph, Auto Review, Self-Healing, Recurrence Prevention, lint, CI, tests, observability stack, all interlocked. Designing / maintaining / evolving that gets harder, not easier. As the house-builder side, rail-layer side, this demands deep infra understanding / security instinct / observability design / a feel for AI's architectural quirks.
I'm building cortex, so I'm spending more time on the latter; building "a foundation where the business can run its own changes" is genuinely fun for me. That said, I'm not the type who fully commits to one side — I move between listening to business questions and assembling the foundation, and the satisfaction from each is its own kind. This isn't a "which is more important?" question — the harness exists precisely so the former is possible, and the former being alive is what gives the latter meaning. They're mutually dependent.
Maybe the era of polishing just "coding ability" is shifting slightly. Where to put your value — or whether to move between both directions — becomes a question more engineers will need to choose into intentionally.
Six posts in, thanks for sticking with me to the end.
| # | Theme | Key scene | Article |
|---|---|---|---|
| 1 | Series intro: cortex's harness | PRs auto-merge / incidents self-heal before you notice | ai-harness-intro |
| 2 | Product Graph (cpg) | Code, docs, DB, infra unified into one graph | cortex-product-graph |
| 3 | AI PR review | webhook → AI review → auto-fix → squash merge | cortex-auto-review |
| 4 | Self-Healing + observability + auto-added guardrails | Alert → AI investigates → fix PR + new lint/type gate → auto redeploy | cortex-self-healing |
| 5 | Democratizing the maintenance phase | Domain experts open PRs to production; the harness owns the quality gate | cortex-non-engineer-prs |
| 6 | Series Final | The underlying philosophy plus a retrospective on the failures and lessons | This post |
comments (15)
The write-time vs read-time inference distinction maps cleanly onto something I keep running into on the content side of AI too. When AI generates a draft, that's write-time inference — it happens once, a human reviews it, corrections get made, it gets frozen into reviewed content. That process is fine and powerful. But then the challenge is the distribution step: getting that content to 15 platforms, in multiple languages, with the right metadata per-platform. If you let AI infer those steps on every publish ("guess what format this platform expects"), you get exactly the problem you describe — unverified inference running on every query. The determinism fix applies there too: structure the platform requirements as explicit facts (not inferred from the platform's vibes), let AI operate over that structured knowledge at publish-time. The harness confines hallucination to where it's acceptable. "Mastering AI is not about giving it freedom — it's about confining its output to a predictable range" — this is going on my wall. The word 'confining' is doing more work than 'prompting' or 'fine-tuning' ever will. The sunk-cost point in the trial section is also underrated. Code-graph was 2 months in and working. Throwing it out anyway because the architectural truth pointed the other direction is the kind of decision that separates harness architects from prompt engineers.
The content-distribution mapping caught my eye—it's the exact same failure mode playing out in a completely different domain. The "harness architects vs prompt engineers" distinction is sharper than what I had in the post: the real line isn't about optimizing a prompt; it's about changing what we allow the model to handle in the first place. The decision to scrap the code-graph wasn't about tweaking the prompts to be smarter. It was facing the reality that we were asking the model to infer something that should have been managed by a deterministic architecture. Overcoming that sunk-cost fallacy is painful, but it's what forces you to look at the system, not the prompt. Glad "confining" landed. That word does the heavy lifting precisely because prompting and fine-tuning only try to influence the model's behavior, whereas a harness actually shapes the boundaries around it.
"Shapes the boundaries around it" vs "influences the behavior inside it" — that's a genuinely useful distinction for explaining to non-engineers why prompt engineering has a ceiling. The harness argument becomes: some failure modes need architectural answers, not better wording. The content-distribution parallel actually runs deeper than I initially framed it — every platform API has its own schema, rate limits, metadata requirements. If you let the system infer those at publish-time, you get exactly the silent variance you described: it works until it doesn't, and the failure is invisible until the content is already gone to the wrong place. The harness answer is the same: structure what can be structured, let inference operate only inside that. Thanks for the series — it's one of the cleaner end-to-end AI architecture write-ups I've read.
"Some failure modes need architectural answers, not better wording" is the line. And "structure what can be structured, let inference operate only inside that" says the principle in fewer words than I managed. Honestly, that closer means a lot. Six posts was a long stretch, and responses like this are what make it worth writing. Thanks for the read, and for the framing.
That really means a lot — six posts is a serious commitment, and the consistency of thinking across all of them showed. "Structure what can be structured, let inference operate only inside that" is exactly the kind of principle that travels well. It'll stick. Looking forward to whatever you write next.
big repos are the real test. stuffing context just creates noise, the model stops actually understanding and starts pattern matching. treating retrieval as a system design problem is the right call.
Right — and that's exactly why pushing the inference to write-time matters. If the model is asked to reason about everything live, it's the noise that breaks it down into pattern matching. But if you let AI generate annotations, structure, dependency edges, etc. at write-time, review them, and freeze them as deterministic context, the live agent never has to handle the noisy "raw repo" — it operates over the curated artifact instead. Retrieval as a design problem solves the noise problem upstream, before any reasoning happens.
This is a strong articulation of the boundary I keep seeing in production AI systems: do not ask the model to rediscover facts the system can make explicit. The write-time vs read-time inference distinction is especially useful. Let AI help generate annotations, graph edges, review dimensions, or policy descriptions, but freeze and review those artifacts before they become runtime facts. Then the live agent is operating over inspected structure instead of re-inferring the world on every request. That also makes failures easier to test: graph wrong, retrieval path wrong, review dimension wrong, or generated conclusion wrong are very different fixes.
Right — and that last point (failures separable by class) is one of the most underrated benefits of the write-time/read-time split. Once inference is frozen at write-time, "the graph is wrong" and "the retrieval missed" and "the live agent reasoned badly" stop being one fuzzy bucket called "the AI got it wrong" and become four distinct categories with four distinct fixes. That distinction is what makes the system testable at all. Without the split, every failure is some opaque mixture of "context was off" and "model was off" with no clean way to bisect.
Exactly. Once the failure classes are separable, the system can stop treating every miss as a mysterious model-quality problem. That separation also changes how I’d build the regression set. I’d want fixtures for graph construction errors, retrieval/path errors, review-dimension errors, schema/format errors, and final-generation errors. Then a model or prompt change is not just “better/worse”; it shows which layer improved or regressed. That is the part I like about the write-time/read-time split: it makes the harness itself testable.
Right — and "which layer improved or regressed" is the metric that suddenly becomes meaningful once the layers are separated. Without that, "the new model is X% better" is a black-box claim that nobody can reproduce or trust. With layer-level fixtures, a model bump that improves final generation by 10% but degrades retrieval by 3% is something you can actually catch and reason about. The harness becomes testable because each layer has a tractable contract; the whole "AI quality" problem stops being one monolithic thing.
"Build rails first" hit different. Ten years in test automation and I never saw it as laying runway for AI until now🤣
Glad it landed 🤣 Ten years of test automation is exactly the kind of foundation work AI ends up depending on. The deep reason: a thick set of existing tests is what lets AI know deterministically what counts as correct behavior. Without it, "did I break something?" is a question AI can only answer by inference — with the tests, it's a question with a deterministic answer. The rails were always there; the framing changes when AI shows up to run on them.
"Tests as determinism boundaries for AI" — that's the framing I was missing. Gonna steal that for the next post. 🤝
Steal away 🤝