Hi, I'm Ryan, CTO at airCloset.
Disclaimer: "cortex" in this article is the internal codename for an AI platform built in-house at airCloset. It is unrelated to existing commercial services like Snowflake Cortex or Palo Alto Networks Cortex.
In Part 1 (Series Intro), I wrote about how cortex's harness has matured to the point where non-engineers (business-side managers, PMOs, and the like) can open PRs to the production repository. The harness here is the runtime foundation for AI in production -- the combination of the knowledge graph, Auto Review, Self-Healing, and Recurrence Prevention covered across Parts 1 through 4.
Part 5 is what comes next: that harness has now reached the layer of who actually writes the code.
"Surely an engineer is still checking afterward, right?" -- I expect a lot of readers will land here with that question. So this post leads with one concrete example before anything else.
Part 5 covers:
- What kinds of PRs are actually shipping -- two recent ones in detail
- What works and what doesn't -- the boundary between adding on top of an existing stack and standing up new infrastructure
- Why this holds for non-engineers -- how the four mechanisms from Parts 1-4 carry it
- What's next -- into toC services -- the direction of travel for consumer-facing scale
The deeper toC implementation story will live in a separate post; here you'll get the framing and the direction.
Series
| # | Theme | Key scene | Article |
|---|---|---|---|
| 1 | Series intro: cortex harness | PRs merging unattended / incidents fixed before anyone notices | ai-harness-intro |
| 2 | Product Graph (cpg) | Code / docs / DB / infra unified into one graph | cortex-product-graph |
| 3 | Auto PR review | webhook -> AI review -> auto-fix -> squash merge | cortex-auto-review |
| 4 | Self-Healing + observability + auto-added guardrails | Alert -> AI investigates -> fix PR + new lint/type gate -> auto redeploy + same pattern auto-rejected from then on | cortex-self-healing |
| 5 | Democratizing the maintenance phase | Domain experts open PRs to production; the harness owns the quality gate | This article ← you are here |
| 6 | Series Final | The underlying philosophy plus a retrospective on the failures and lessons | cortex-philosophy |
Start with one scene
A +1,742 line / 41 file PR lands on the internal dashboard web app. Title: "PL dashboard ver.2". The change opens up project visibility to managers and team leads across multiple business units, scoping what each person sees to their own division or team. It adds an SSoT in the shared types package, new routes on the API server with SQL involving INNER JOIN and LEFT JOIN, new pages and view-state on the web app, and a personal-settings surface -- the whole stack of things you'd expect for a real feature.
The point is, this isn't a typo fix or a string swap. Entities, repositories, API routes, screens, filters, personal settings -- every layer you'd normally touch for a feature got touched. A few days of work for an experienced engineer, in scale terms.
The review-fix cycle ran like this:
- PR open (+1,742 / 41 files)
- auto-review pass 1: Major finding (a permission-scope fall-through -- data from other divisions leaking into the view that shouldn't be there) plus a handful of Minor items
- author bot push: closes the scope fall-through, addresses the Minor items
- auto-review pass 2: Nit items remaining, plus a lint catch (
no-empty-function) - author bot push: lint clean
- auto-review pass 3: still some COMMENTED nits, not yet APPROVE
- author bot push (iteration 2): hardens loading skeleton, reverts an unnecessary JSDoc tweak
- auto-review pass 4: APPROVED → CI green + APPROVE both met → auto-merge → production
From PR open to merge: four review-fix rounds, three author-bot pushes, zero human reviewers in the loop. The reviews come from the auto-review bot, the fixes come from an author bot (an automated review-response agent that the PR author has running on their machine), the final APPROVE is submitted by the AI, and an auto-merge script picks it up the instant CI is green. Production lands with 56/56 shared type checks (SSoT), 2,284/2,284 API tests, 1,113/1,113 web specs, and 0 lint errors. (cortex splits the lint job between oxlint for general checks and a custom eslint plugin for the @graph-* rules.)
The second review pass is worth noting. "Scope fall-through" is a somewhat technical finding -- a hole in the permission filter meant data from divisions other than your own could leak into the view. This is an internal dashboard, so it's not an external-leak incident, but "only see what's relevant to you" is the whole point of a dashboard like this -- losing it doesn't just risk an information slip, it drowns the user in noise that they shouldn't be filtering through in the first place. That's the kind of issue that's easy to merge by mistake and painful to notice in production. The fact that auto-review caught it on pass one and bounced it back for the author side to fix is what makes this whole flow viable for non-engineers. Without that loop, a PR of this size from a non-engineer would be a bad bet.
And: the author of this PR is not an engineer. A business-side teammate handed a feature description to Claude Code, leaned on the knowledge graph (covered in Part 2) to pull in the relevant existing code, and the +1,742 line PR is what came back. The four review-fix rounds above are what happened next.
That setup lines up directly with the central claim of this post: the person who knows the business requirements best, instead of organizing them and handing them to an engineer, runs them through Claude Code to production themselves.
Quick clarification on "write." When I say "write" in this article, I don't mean typing line by line in an editor. I mean handing the business requirements to Claude Code, judging the resulting diffs and AI review comments with domain knowledge, and seeing it through to a production merge -- the whole arc. Most of the actual diff is written by Claude Code; review feedback is handled by the author bot. What the human does is three things: put what they want into words, make the judgment calls along the way ("does this fit, is this off"), and sign off when it's ready to merge. None of that is implementation work in the technical sense. That's what "write" means here.
There's still a learning curve, of course -- the prompts you give Claude Code, where to point it for context. But none of that is learning to program. What you need is the ability to articulate what you want clearly, not syntax or framework knowledge.
The harness covers quality, so even at +1,742 lines / 41 files, this works.
Out of scope: this post does not cover the path where non-engineers freely ship apps to a sandbox environment instead of opening PRs against the production repo. That's a different mechanism, covered in an earlier post: Bridging "I Want to Build" and "I Want to Publish Safely" for Non-Engineers with a Custom Sandbox MCP. This post is specifically about opening PRs against the production repo -- the front door that's traditionally been engineer-only.
When you need a change, you can make it yourself
The point of the previous section is this:
When you need a change, you make it yourself, without flagging an engineer.
When that holds, work like:
- "I want a new metric on the dashboard"
- "The aggregation filter doesn't match how the business actually operates"
- "I want a small business-support feature embedded in the production app"
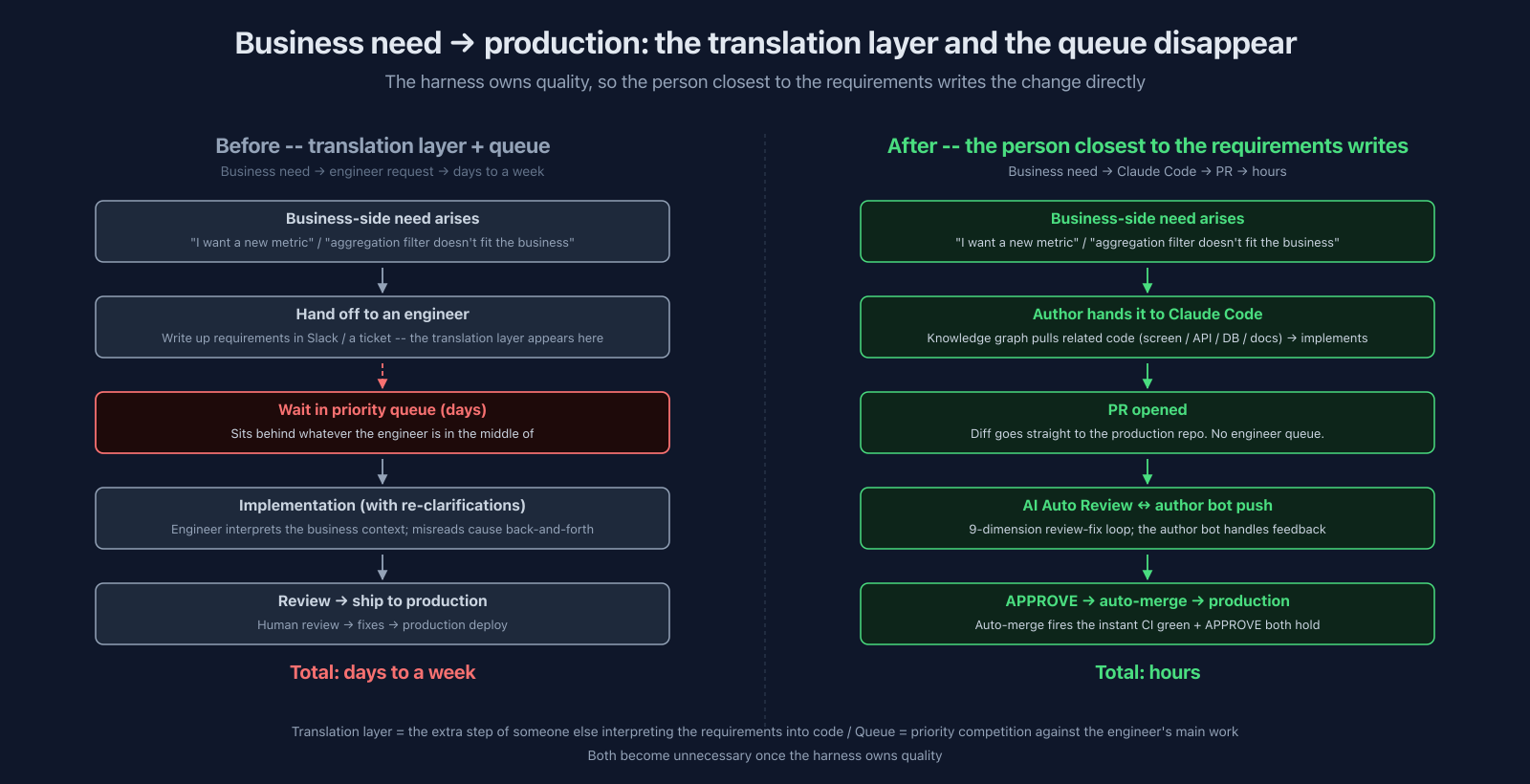
stops queueing behind whatever an engineer is in the middle of. The fix lands when the need lands.
Think about the old flow. Someone on the business side notices a small thing that needs to change. They write the requirements up. They open a ticket or a Slack thread for an engineer. The engineer is in the middle of something else, so it queues. When they finally get to it, the interpretation drifts from what the business actually meant, there's a back-and-forth, a review pass, and only then does it ship. Even a small change takes days to a week in wall-clock time.
That's the cost of a translation layer between business understanding and code, and it gets worse the busier the engineer is. The business's improvement cycle ends up paced by engineering's backlog.
When the person who knows the requirements writes the change themselves, that translation layer and that queue both disappear.
Here are two recent examples of that working.
Two non-engineer PRs that recently shipped
| PR | Kind | Size | What changed |
|---|---|---|---|
| PR 1 | Deep bug fix | +348 -177 / 7 files | The dashboard's actuals number was unfairly exceeding the target. Root cause: the "which teams to aggregate" definition was asymmetric between target side and actuals side. Fix lifts the shared "teams to include" list into its own file and points both sides at it. Tests added too. |
| PR 2 | Feature build on top of existing stack | +1,742 -227 / 41 files | The PL dashboard v2 from the opening scene. Entities, repositories, API, UI -- all touched, but the web app itself (the stack) was already standing; this rides on top. |
Different shapes, but both are non-engineer PRs that made it all the way to merge.
PR 1 -- a deep root-cause fix
This started from "the number looks wrong" on the business side, and the PR went all the way down to a data-integrity issue. The surface symptom: "the actuals number on the dashboard exceeds the monthly target, with the achievement reading 101% even though the team knows that's not real." The lazy fix would be a fudge factor or a clamp on the display. That's not what happened.
The author dug into the aggregation queries and pinned the real cause: the actuals side and the target side were reading from different tables, and the definition of "which teams count" wasn't symmetric between them. Teams that don't carry a target value (designers, PMOs, and so on) didn't show up on the target side but were getting counted on the actuals side, so the numerator was inflated against the denominator.
The fix is structural, not cosmetic. A single file defines "the teams in scope for this aggregation" as a shared list, and both sides reference it. No future drift between target-side and actuals-side definitions -- it's locked in by the shared constant.
The handling of "what data falls out of an aggregation" and "are the target and actuals sides really symmetric" is the kind of thing engineers miss too. A non-engineer working through it down to the structural level and fixing it there is what stands out about this PR.
PR 2 -- a big feature build on top of an existing stack
This is the PR the opening scene walked through. +1,742 / 41 files spanning entity, repository, API, and UI -- a scale of change that's well past what people usually mean when they say "modification."
What lets a non-engineer ship this size of change is that the web app itself (the stack) is already standing. Nobody's standing up a new app, no new Cloud Run service needed defining, no new dependency packages, no new directory structure. The change adds a route, a page, and a repository entry inside the existing structure that's already there. It rides on what's been built.
This is the "on top of an existing stack" range. That's where the boundary is, and the next section spells it out.
Note on terminology: "modification" in this article is broader than "small tweaks to existing logic." It includes adding new entities, new endpoints, and new pages on top of an existing stack. The line I'm drawing is between building on top of a stack vs. standing the stack up in the first place.
What works, what doesn't
The principle: standing up a stack is hard, building on top of one isn't
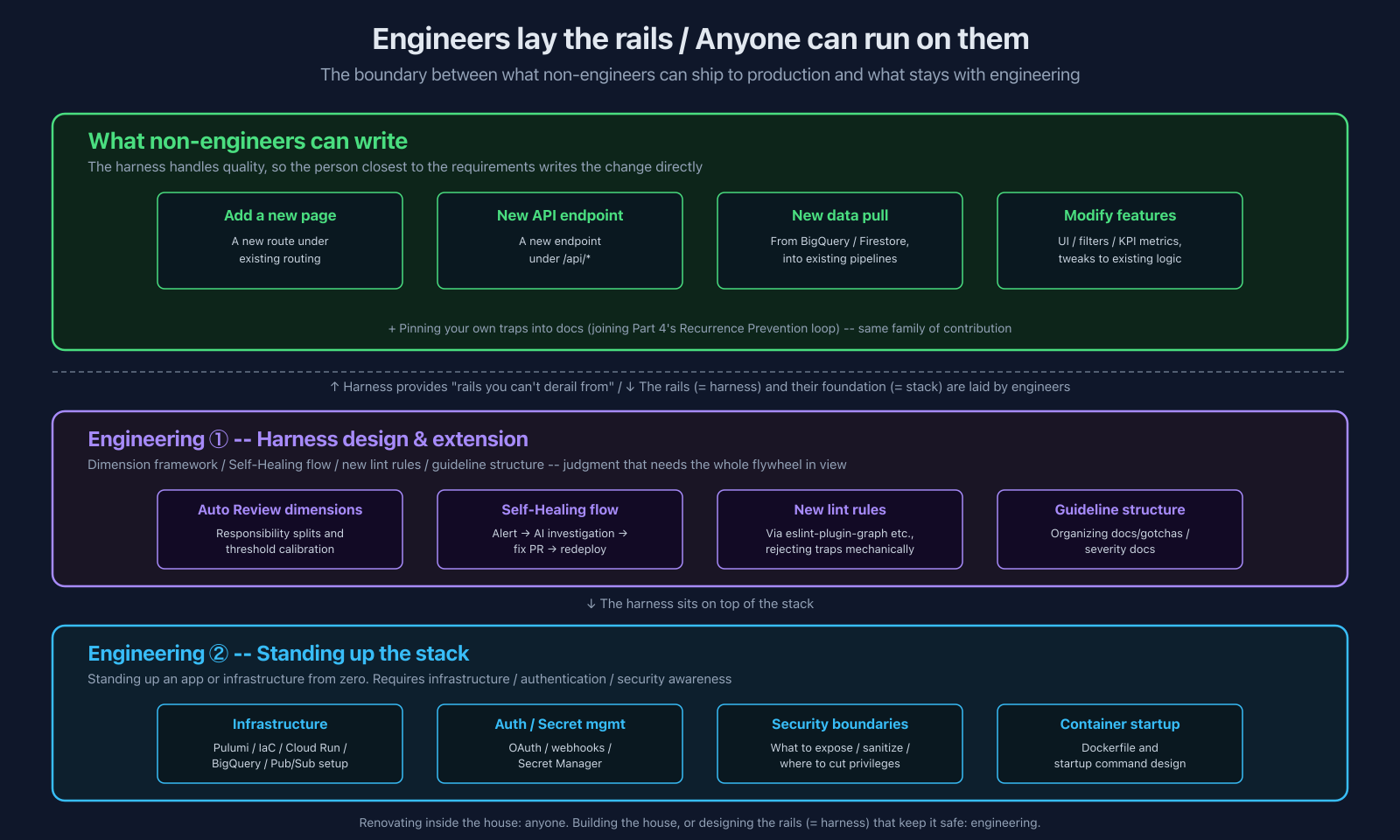
The cleanest dividing line for non-engineer development isn't "modification vs. new development." It's "on top of an existing stack" vs. "stand up a new stack."
- Standing up a new stack (work that starts from infrastructure: a new web app from scratch, a new Cloud Run service defined from a Dockerfile, a brand-new BigQuery pipeline) → engineering work
- Adding to an existing stack (a new page in an app that already exists, a new endpoint on an existing API, a new data source on an existing pipeline) → non-engineers can do this
All three of the example PRs above sit on the second side. The stack itself was already built (by me, for the most part), so they get to work inside it. "Stand up a new app from scratch" or "define infrastructure (Dockerfile / IaC) from zero" are still engineer territory.
Put another way: renovations and new rooms inside an existing house are open to anyone. Building the house itself is engineering. Get the structure wrong -- the load-bearing parts, the wiring, the plumbing -- and the cost of recovery is high. That's the part of stack design where there's still too much "if this is wrong, everything downstream breaks" risk to hand to AI.
What's left for engineers: laying the rails -- the stack and the harness itself
The flip side: the rail-laying work -- standing up a stack, and extending the harness itself -- is what non-engineers don't touch yet. Both require a different kind of knowledge:
- Infrastructure: containers, IaC, the operational characteristics of cloud services. Cloud Run resource ceilings, cold starts, Pub/Sub at-least-once semantics, BigQuery partition / cluster design, how Pulumi stacks split. Get this wrong and a thing that compiles can still fall over in production
- Authentication for external integrations: OAuth, webhooks, how you handle API keys and where they sit in Secret Manager. One small slip leaks credentials into the repo or lets a webhook fire something you didn't intend
- Security fundamentals: what to never expose, where to sanitize, where the privilege boundary cuts. SQL injection, XSS, SSRF, broken authorization -- "it works" isn't enough here
- Harness design and extension: adding a new Auto Review dimension, changing Self-Healing logic, writing a new lint rule (e.g. in
eslint-plugin-graph), structuring guidelines. Decisions that require understanding how the whole flywheel hangs together -- the most meta layer
That last bullet -- harness extension -- has an important implication: for non-engineers to keep being able to ship to production, someone has to keep the harness evolving. Recurrence Prevention (Part 4) is the automatic loop that adds lint / CI guards / guidelines per trap. But the architecture of the harness itself -- the structure of dimensions, the calibration of judgment, the design of the Self-Healing flow, the shape of the knowledge graph -- those are a meta layer that still requires engineering judgment.
Concrete case: the current nine Auto Review dimensions ([Graph] / [Architecture] / [Security] / [Test] / [Doc] / [Impact] / [Observability] / [AI-Antipattern] / [Recurrence]) were designed by observing past incidents and fix patterns. When a tenth dimension becomes necessary -- say, a "breaking change check on dependency upgrades" axis -- decisions about responsibility splits with existing dimensions and where to set thresholds are made by looking at the whole structure. That's the kind of engineering work that stays.
The harness provides "rails you can't derail from." Laying those rails -- and laying the foundation those rails sit on -- is a different job, and it's still on engineering. Engineers lay the rails; anyone can run on them. That's the boundary today.
Why this works for non-engineers
This is a short recap, because everything that makes it work was already covered in Parts 1 through 4. Four mechanisms reinforcing each other -- that's what lets non-engineers operate safely on top of an existing stack.
① The knowledge graph pulls relevant code from "what you want to do"
cortex-product-graph from Part 2 -- the unified graph fusing code, docs, DB schema, and infrastructure into one knowledge base (implementation name: cpg) -- carries this layer.
Non-engineers don't need to know function names or repo structure. A natural-language question like "I want to add a metric column to the dashboard" goes to Claude Code, which hits the knowledge graph with a semantic search and gets back the relevant nodes -- the screen, the API, the DB, the docs -- in one or two hops. You can get started without knowing the technical vocabulary.
For PR 2: the author told Claude Code "I want PL dashboard v2 with division/team scoping for non-PI-Div PMOs and team leads," and the knowledge graph pulled the existing /projects route, project-repository.ts, FilterHeaders.tsx, and ProjectTable.tsx as the relevant nodes. The author never needed to know what file to edit. That's how the translation layer drops out.
② Auto Review enforces quality at the gate
The 9-dimension automated review from Part 3 is the next layer. [Graph] / [Architecture] / [Security] / [Test] / [Doc] / [Impact] / [Observability] / [AI-Antipattern] / [Recurrence] -- the AI returns REQUEST_CHANGES on what's missing and loops with the author bot until APPROVE -- the four-round example from the opening scene is exactly this in motion.
The point is this: the first PR doesn't have to be perfect. The author doesn't need to ship a completed, security-hole-free version on the first try. Push the initial PR and the rest gets sorted by the auto-review and the author bot bouncing off each other. The reason the author bot doesn't spin off into a loop of confused fixes is that the knowledge graph holds the full codebase context: changes are made with structural awareness of what they touch, so misreadings of the review feedback don't compound.
③ Self-Healing catches what slips through to production
Part 4 covered Self-Healing. If something does break in production, the AI starts from the alert, investigates root cause, opens a fix PR, and gets it auto-redeployed -- the entire loop runs without humans. Incidents triggered by a non-engineer's change recover on their own, hands-off. That's what makes the bar to opening a PR feel survivable.
This isn't "non-engineers are safe because nothing can go wrong." It's "even if something goes wrong, the harness has it covered." The system is designed to minimize damage, not eliminate failure. The three-layer construction (Observation → Repair → Strengthening) from Part 4 is what makes that net real.
④ Recurrence Prevention keeps the trap count from growing
The Recurrence Prevention loop from the back half of Part 4. Every trap that gets stepped on gets nailed down in the same PR, so the next attempt at the same pattern gets caught. The form depends: mechanizable traps become lint or CI guards; less-mechanizable ones become entries in the guideline docs (docs/gotchas, severity docs) that the AI reviewer reads. Either way, the catch happens before merge. Non-engineers contribute to this loop too -- when they hit a trap, the doc entry that prevents the next person from hitting it can come from them.
As this compounds, the rails get denser. Where there was once a loose "don't go that way" guideline, every incident adds another small rail saying "or this way, or this way, or this way," and the lane that's safe to walk gets clearer. The denser the rails, the safer non-engineers are in the lane.
→ The four pieces aren't independent components. Each one's output feeds the next one's input. This is the Guides + Sensors flywheel from Part 1 in action. I won't re-explain the details since they're in the prior posts, but non-engineers shipping to production is the result of all four wheels turning together. Take any one out and the level of upfront knowledge required to write to production jumps, and the whole thing collapses.
Next -- carrying the pattern to consumer-facing services
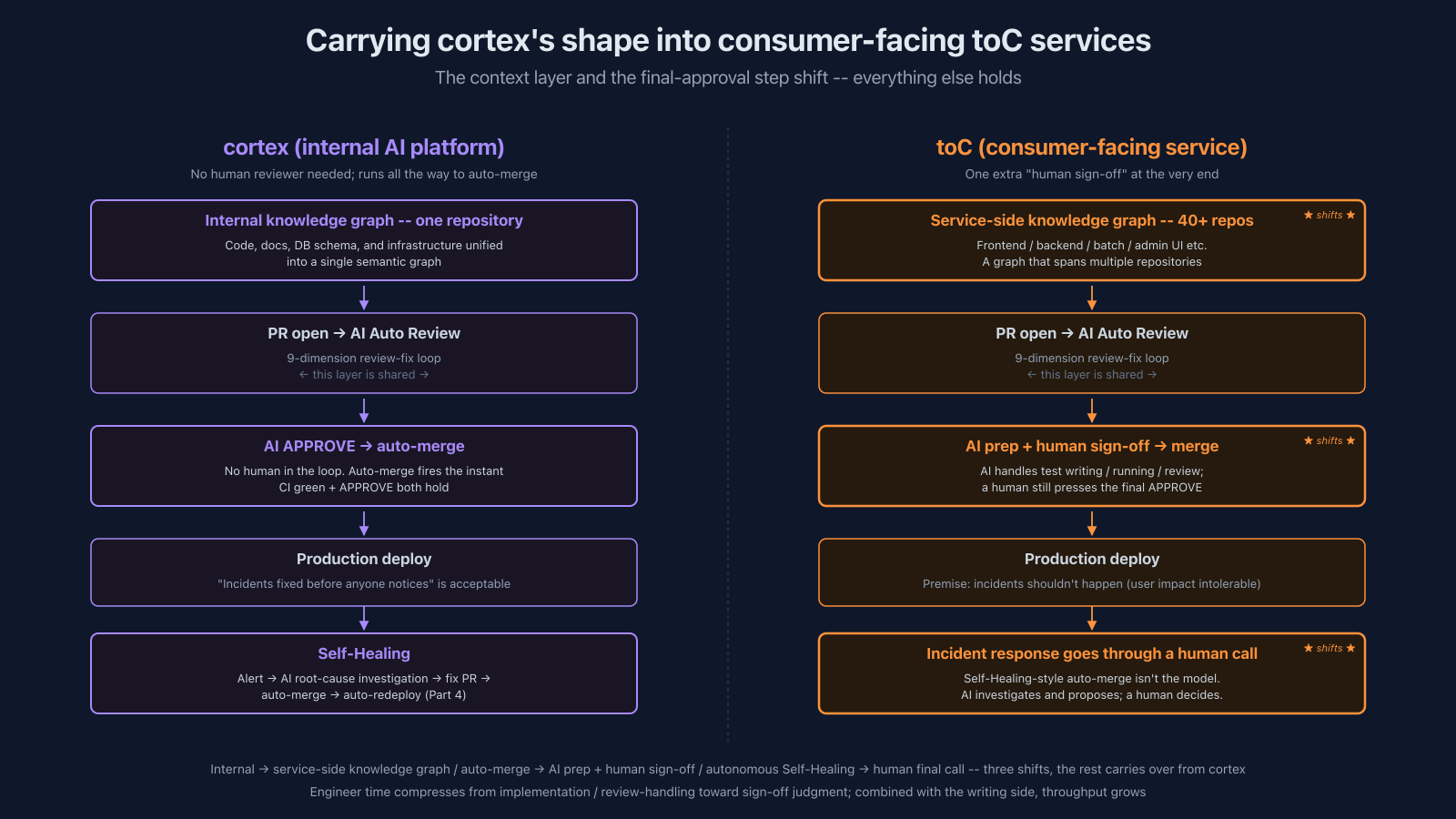
cortex is an internal AI platform, so the system as it stands can't be lifted into a toC production service as-is. The biggest issue is the difference in quality bar. For toC, "detect after user impact → Self-Healing fix" is too late. The requirement becomes: incidents don't happen, and when something is about to ship, there's review and testing on top of human sign-off.
That said, the shape of the harness -- a knowledge graph for context, 9-dimension AI review, an author bot responding to feedback -- carries over directly. The thing that changes is the final step: cortex's auto-merge becomes "AI does the prep, a human signs off." Not by giving up the AI's range, but by having the AI handle the heavy lifting (test writing, environment setup, test runs, the 9-dimension review) and leaving only the final APPROVE on a human. "If the human sign-off stays, engineer time doesn't really decrease, does it?" -- but historically engineers were spending the bulk of their time on the implementation, the test writing, the environment setup, the self-review, the back-and-forth on review. Sign-off itself is the smallest piece of that pie. With AI doing the prep work, what an engineer spends time on shifts from implementation labor to quality judgment.
A caveat on the knowledge graph: it only earns its keep at large codebase scale. If the codebase fits in one AI context window, a cross-repo graph is unnecessary. The reason cortex (100+ apps) and the toC side (40+ repos) need one is because the scale forces it.
The concrete plan is real (extending the knowledge graph across the toC side's 40+ repositories, designing the AI-prep flow, etc.), and the full version goes in a separate post.
Wrap-up
- The person who knows the business requirements best, instead of writing them up for an engineer, runs them through to production directly. Quality is held by the harness, so what's required from the writer is domain knowledge and the ability to direct an AI well. Business asks stop queuing behind engineering, and the cycle speeds up
- The four mechanisms from Parts 1-4 (knowledge graph / Auto Review / Self-Healing / Recurrence Prevention) form a reinforcing flywheel. The first PR doesn't have to be perfect, and what does break is repaired automatically. That's the design
- The boundary: engineers lay the rails, anyone can run on them. Standing up the stack (infrastructure, authentication, security) and extending the harness itself (new lint rules, new review dimensions, Self-Healing flow design) stay on engineering
- Carrying this to consumer-facing toC services, the knowledge graph (a 40+ repo cross-repo graph on the service side) covers the context layer, but the quality bar shifts, so auto-merge becomes "AI prep + human sign-off." Details in a separate post
In Part 6 I'll wrap the series with the philosophy at the foundation -- why this design, what got given up, what got kept. The series so far has been about "the parts that are working"; Part 6 puts the failures and the dead ends on the table too, including the gap between the philosophy and the actual implementation. A retrospective for myself, and -- I hope -- a reference for anyone heading down a similar road.
comments (32)
the harness as guardrail is what makes non-engineer PRs viable. without it you're just hoping. curious what breaks first when a PMO touches a prompt that's load-bearing for 3+ workflows downstream.
The scenario shouldn't be reachable by design — load-bearing prompts (Auto Review dimension prompts, Self-Healing triage prompts, etc.) live in the "harness itself" layer, not the "build on top of the harness" layer that non-engineer PRs operate in. Same boundary as the post (stack vs. on top of), applied at the prompt layer. If a PR did cross that line, the Auto Review's impact dimension would catch it via the knowledge graph — it traces the prompt's downstream usage and refuses the merge until a human design review approves the change to the harness layer itself.
the knowledge graph tracing impact is the part that operationalizes the boundary - you can't rely on convention when non-engineers are authoring. Auto Review blocking a merge that crosses layer boundaries is the right enforcement mechanism, not documentation and code review.
Right — and the dependency on the knowledge graph here goes deeper than enforcement. Without it, you can't even tell whether a given prompt is load-bearing across multiple workflows in the first place. Convention-based review (docs + human eyes) collapses well before the prompt layer; nobody can hold "this prompt feeds three downstream workflows" in their head reliably. The graph is what makes "load-bearing" a checkable property at all, and the enforcement (Auto Review blocking on impact) just rides on top of that. Without the graph, there's nothing for the gate to check.
yeah load-bearing prompt detection is the right frame - a prompt feeding three workflows looks identical to an isolated one until something breaks. the graph surfaces that dependency before it becomes a production incident. without it you are doing blast radius analysis by memory, which does not scale past 5 workflows.
Right — "looks identical until it breaks" is exactly the failure mode that makes convention-based review useless at scale. The 5-workflow ceiling matches what I've seen too; once a codebase has more than a handful of cross-references between prompts and downstream consumers, nobody can hold the dependency graph in their head, and blast radius decisions degrade from "informed" to "guessed." Surfacing it before incident is the part that turns the graph from a debugging tool into a gating mechanism — it stops being something you query after the fact and starts being something the merge can't proceed without.
nobody can hold that graph mentally past 5-6 connections - it collapses the same way any undocumented API dependency graph does. explicit tooling is the only fix that scales.
Agreed — "any undocumented API dependency graph" is a useful generalization. Explicit tooling at the gate is the only fix that holds across that class.
right, though a static gate only covers known topology — agents hit new tool connections mid-run that weren't visible at entry. gate + runtime check is the full pattern, not just gate.
This works when the harness turns intent into reviewable structure. A non-engineer can author a change, but the system still needs hard gates around tests, ownership, and risky surfaces. Otherwise “anyone can author” becomes “no one owns the failure.”
Exactly the right framing. The harness in cortex separates authorship from failure ownership: anyone (PMO included) can author the change, but the failure ownership sits at the system layer, not the PR layer. PR-level correctness is owned by Auto Review + the test / lint gates you mentioned. System-level reliability — "did this keep running in production" — is owned by the engineers who designed the harness, backed by Self-Healing for routine fixes and human escalation for what Self-Healing can't crack. "Anyone can author" only works because "someone owns the system" is true one layer up.
Exactly. "Anyone can author" only works when ownership moves to the right layer. The harness can let more people express intent, but the system still needs clear engineering ownership for reliability, gates, escalation, and production behavior. Otherwise low-code authorship becomes unowned execution, which is where the risk shows up.
Agreed, and that's the exact architecture the post describes. Ownership never moves away from engineering here. Engineers own the harness, the infrastructure, and the failure path, and the only thing that moved to non-engineers is authorship on top of those rails. So when an authored change misbehaves in production, that's not the author's failure, it's a hole in the harness, which means it's an engineering failure. "Unowned execution" is precisely the state the whole design exists to make impossible.
The four-mechanism flywheel is convincing, and the scope fall-through catch is a great example of the gate doing real work. The open question for me is the one you flag yourself: the harness still needs engineers to extend it, and those engineers got their judgment from years of exactly the implementation work you're now routing around non-engineers. So who lays the rails in ten years? The harness buys huge leverage today but quietly depends on a generation of engineers it doesn't reproduce.
Sharp question — and one I keep coming back to. My current bet: the rails-laying side stays engineering work for a long while, and the next generation of engineers grows by doing exactly that. The implementation work isn't going away; it's moving up one level, from "implement this feature" to "design the gate that catches the next class of bug like this." That's still hard, still requires years to mature, still builds the same muscle in a different shape. Engineering doesn't reproduce by accident — it reproduces by doing real work, and there's plenty of real work at the harness layer. Whether the shape of that judgment ends up identical to today's, I doubt — but the path isn't broken either.
The harness idea is the important part. If the workflow has strong constraints, tests, and review points, more people can author safely without pretending every author is also an engineer.
Exactly. "Without pretending every author is also an engineer" is the line — that pretense is what breaks down at scale. The harness is what lets the same workflow safely accept changes from very different authors without lowering the quality bar.
That is the right boundary. The harness should make contribution safer, not flatten everyone into the same role. A non-engineer can bring domain taste, examples, constraints, and edge cases; the harness translates that into checks the system can actually enforce. That is a much better model than asking every author to become half-engineer just to participate.
Beautifully put — "the harness translates that into checks the system can actually enforce" is exactly the design problem. The series wrap-up I have coming next week is almost entirely about that translation work, which I've come to think of as the whole job. You named it cleaner than I did.
That translation work feels like the real product. The hard part is not giving non-engineers a prettier text box; it is turning domain intent into enforceable constraints without making the author learn the machinery. Looking forward to the wrap-up. That boundary between expression and enforcement is where these systems either become empowering or quietly dangerous.
"Translation work feels like the real product" is exactly how I've come to think of it. And the "prettier text box" trap is real — you can ship a sleek interface on top of the same untranslated mess, and it just routes the failure further downstream. The hard work isn't in the surface, it's in turning intent into something the system enforces while the author keeps thinking in their own language. Your "empowering or quietly dangerous" framing — I'd phrase it slightly differently: this is fundamentally about the quality of the harness design itself. A well-built harness empowers; a sloppy one becomes a hazard. That's an old systems-engineering truth, not AI-specific — what's new is the kind of author we're handing the harness to, not the principle.
That is a fair correction. The harness quality is the real variable. The AI-specific part is the surface area of delegation: more people can now express intent into systems they do not fully understand. So the harness has to carry more responsibility for constraint, feedback, and safe failure than a normal UI would.
Yes — "surface area of delegation" captures the AI-specific part well. A regular UI exposes a bounded set of operations; the user picks among them. An AI harness accepts open-ended intent and has to translate it into system operations the author never wrote. So the harness ends up owning much more of what used to be the author's responsibility — constraint, feedback, safe failure, exactly as you said. The consequence I've come to accept is that harness engineering ends up being harder than the development it routes around, not easier. The author's job gets simpler; the harness builder's job gets more demanding.
Exactly. The hard tradeoff is that the harness has to make complexity legible without dumping it back on the author. My current test is: can the harness explain what it refused to do, what assumption it made, and what artifact changed? If it can do those three things, the author gets leverage without needing to become the engineer of the whole system.
That's a sharp test. Mapping it onto how I've built mine: "what it refused to do" shows up as lint + CI gates + review REQUEST_CHANGES with the rule cited; "what assumption it made" comes back as the knowledge-graph facts it pulled into the decision; "what artifact changed" is just the PR diff plus the auto-generated review summary. None of those are AI-novel — they're plain old observability of the harness. But none of them come for free either; designing those exposures intentionally is exactly the demanding part I meant by harness engineering being harder than the development underneath.
That breakdown is exactly what I would want to see from a mature harness. The interesting part is that none of those signals are magical, but the combination changes the trust model. A refusal with the rule cited tells you the boundary is active. The assumption list tells you what context the agent believed. The diff/review summary tells you what actually changed. Together they make the harness inspectable instead of mysterious. I think that is where a lot of teams underinvest: they spend time on the agent’s capabilities, but not on the evidence surface around those capabilities. Without that surface, even a good harness feels like a black box.
Honestly, my sense is sharper: to me, the whole job of the harness is taking the context handed to AI and pushing it from inference toward determinism — that's what confines hallucinations. Once you've actually done that, the evidence surface isn't a separate layer you bolt on; it's already there as the byproduct of the determinism. Refused / assumed / changed are just what the deterministic work looks like from the outside. So a "good harness without the surface" isn't really a picture I can hold — if the surface is missing, the determinism wasn't really done.
I like that framing. "Evidence surface" should not be a reporting layer added after the harness works; it is the external shape of the harness doing its job. If the harness really made the work deterministic, then it should be able to show the constraints, inputs, refused paths, assumptions, and changed artifacts without extra storytelling. When that surface is missing, the system may still be useful, but it is asking humans to trust an invisible process. That is the difference between "the AI helped" and "the team can safely delegate this class of work again."
Well put. That's a clean place to leave it — appreciated the thread.
Yes. That is also where the evidence surface becomes useful to humans, not just to the harness. If the harness can show which assumption failed, which artifact changed, and which check produced confidence, review becomes much less ceremonial. The worst version is a green/red badge with no chain behind it. The better version is a small audit trail that lets someone decide whether the result deserves trust.
standing up a stack is hard, building on top of one isn't 😀
Yes, exactly. The harness is what makes the "building on top of one" half safe enough to hand off. Without the harness, even that side stays engineering work.