みなさまこんにちは!エアークローゼットでCTOをしている辻です。
これまでに社内MCP群の全体像、DB Graph MCP、Biz Graph、Google Meet録画のデータ化、Sandbox MCP、MCPの退避パターン、そして直近のAgentic Graph RAG MCPのススメと、社内向けの個別アプリ・MCPサーバー・設計原則を順に紹介してきました。
これらは全部、cortexと名付けた社内向けのAI開発プラットフォームの上で動いています。今回は、そのcortexそのものについて書きます。今回から数回に分けて、その仕組みを公開していく予定で、本記事はその初回・総論編です。
連載一覧
| # | テーマ | キーシーン | 記事 |
|---|---|---|---|
| 1 | 総論:cortexのハーネス | PRが無人マージ / 障害が気づく前に治っている | 本記事 ←現在地 |
| 2 | Product Graph (cpg) | コード・ドキュメント・DB・インフラを1グラフに統合 | cortex-product-graph |
| 3 | AI PRレビュー | webhook → AIレビュー → 自動修正 → squash merge | cortex-auto-review |
| 4 | Self-Healing + Observability + 自動lint追加 | アラート → AI調査 → 修正PR + 新規lint/型gate → 自動再デプロイで同じ書き方を機械的に弾く | cortex-self-healing |
| 5 | 改修フェーズの民主化 | 業務要件を把握している人が本番に直接PR、ハーネスが品質を担保 | cortex-non-engineer-prs |
| 6 | 連載総括・最終章 | 根底にある思想(何を捨てて何を取ったか / なぜこの設計か)と失敗の振り返り | cortex-philosophy |
いきなり2つのシーンから
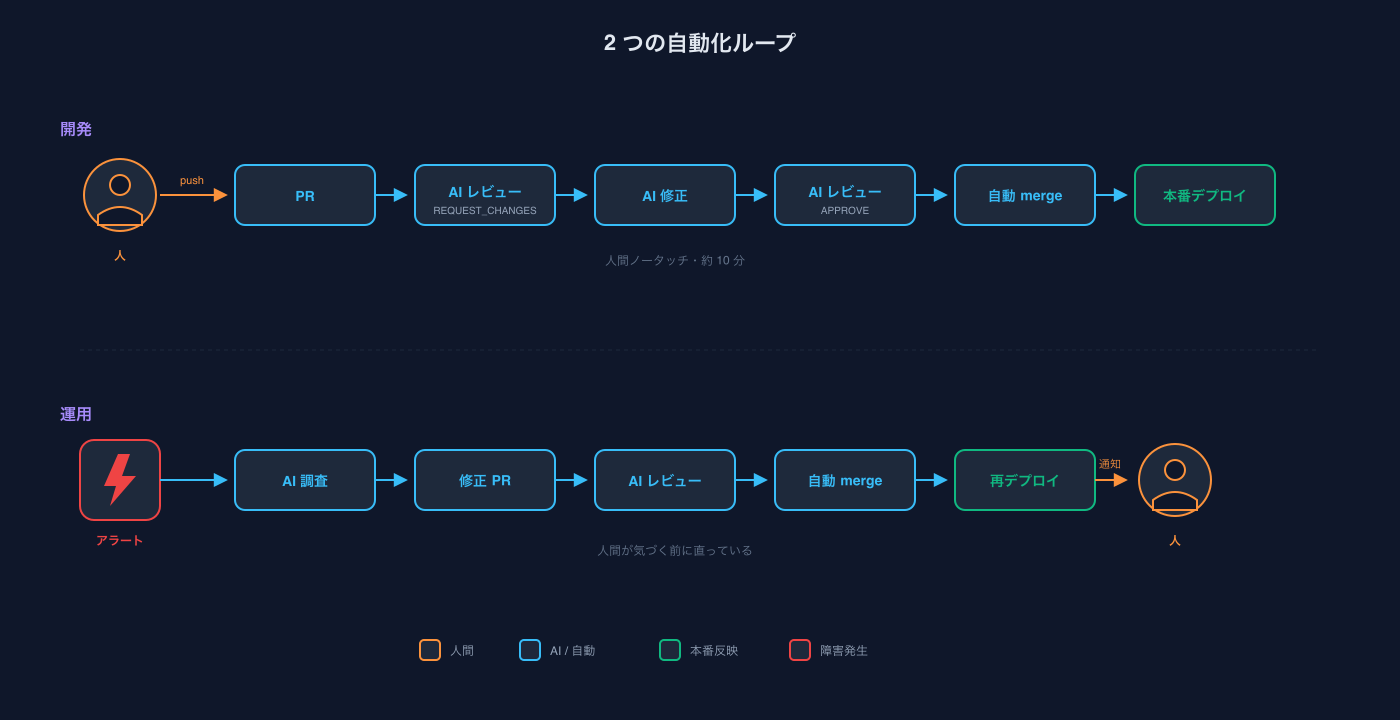
シーン1: PRは無人でマージされる
月曜の朝、エンジニアがローカルで機能を実装し、ブランチをプッシュしてPRを出す。
- 数分後、AIレビュアーからREQUEST_CHANGESが付く。指摘は複数:
- 「同じデータ整形を共有パッケージの
formatRow()がすでに実装しているので重複しています。共通化してください」 - 「APIのレスポンス型を変更していますが、関連するドキュメント(
docs/api/...)の記述が古いままです」
- 「同じデータ整形を共有パッケージの
- AI対応エージェントがworktreeを切って、修正をコミット、プッシュ
- 再度のレビューでAPPROVE
- 自動でsquash merge
- 変更されたスタックだけがGitHub Actionsで検出され、Cloud Run / Cloudflare Pagesへデプロイ
ここまで人間ノータッチで完了します。エンジニアはPRのタブを更新して、「あ、マージされてる」と気づく。
シーン2: 障害は気づく前に直っている
朝7時、Grafanaのアラートが飛ぶ。「BQパイプラインが3回連続で失敗」。
- AIがwebhookを受け取り、Grafana MCP経由でLokiからエラーログを取得
- Product Graph(実装名:
cortex-product-graph。cortexのコード・docs・DBスキーマ・インフラ定義を1つのグラフに統合した知識基盤。本記事の後半とPart 2で詳述)で当該パイプラインのコード・依存テーブル・関連docsを辿り、根本原因を特定 - 修正PRを作ってプッシュ
- AIレビュアーがAPPROVE → 自動squash merge → 自動再デプロイ
9時に出社してSlackを見ると「pipeline直っといたよ」とログが流れている。エンジニアが対応するのはAIがどうしても解けない一部の難しいケースだけになります。
この2つのシーンを支えているのが、これから紹介する開発環境です。
業界文脈 ── 「ハーネスエンジニアリング」の流れ
cortex自体の話に入る前に、業界の文脈を1段落だけ書かせてください。直近半年、AIエージェントを実務で使うための土台づくりが、海外の主要企業からひとつのトレンドとして言語化されてきました。
「ハーネス」自体は新語ではなく、AI領域では2020年にEleutherAIが公開したlm-evaluation-harness(LLMの評価フレームワーク)から使われていた言葉です。それがLLMエージェント文脈の「ハーネスエンジニアリング」として、ひとつのエンジニアリング領域に昇格したのが直近半年の出来事:
- 2026年2月: OpenAIが"ハーネスEngineering: leveraging Codex in an agent-first world"を公開。社内の少人数チームがCodexを主導役に5ヶ月で100万行を書いた、という事例
- 数日後、Mitchell Hashimoto(HashiCorp共同創業者 / Terraform作者)が
Agent = Model + Harnessという公式に蒸留 - 2026年4月: Martin Fowler(『リファクタリング』著者 / ThoughtWorks Chief Scientist)が"ハーネスEngineering for Coding Agent Users"でGuides(事前制御)/ Sensors(事後制御)の分類を確立
- 同4月、Anthropic / Cursorも独自のハーネス記事を公開
業界の合言葉として"2025 was the year of agents. 2026 is the year of harnesses."が浸透しつつあります。
要は、モデル単体は急速にコモディティ化している(Claude / GPT / Geminiの差は使う側からは縮まっている)。差がつくのは「AIを本番で動かすための土台=ハーネスをどう設計するか」だ、という認識です。
cortexは、この「ハーネス」を社内で本気で作ってみた事例として読んでもらえると素直に伝わります。本記事ではFowlerのGuides / Sensorsの枠組みでcortexを整理して紹介します。
ここからは、「モデルよりハーネスで差がつく」という世界線を、cortex上でどう具現化しているかを見ていきます。
誰が開発しているか
cortexの最初の数ヶ月は、自分が100%、1人で開発していました。「ハーネスが整わないと他人がPRを出すのは難しい」というレベルではなく、そもそも誰も乗りこなせない段階だった、というのが正確なところです。
当時すでに、Google Meet録画のデータ化、17 MCPサーバーのうちの半分、それ以外の記事化していない機能まで含めると、全部で50近いアプリケーションが疎結合に動いていました。各機能の目的・背景・データフローはドキュメントに手厚く残していましたが、量が膨大すぎて、仮にAIを使っても関連docsを逐一読ませて理解させるのは現実的ではない状況でした。要は、人にもAIにも一度に把握させきれないコードベースになっていた。
直近、ハーネスが組み上がってきたことで、エンジニアではないメンバー(事業サイドのマネージャー、PMOなど)もcortexにPRを出せるようになってきました。執筆時点での累計コミット比率は約91%が自分、残りの9%が直近の他メンバー寄与です。
非エンジニアが本番リポジトリにPRを出すと聞くと「品質が保てるのか」と思うのが普通ですが、cortexではAIレビューと自動化が品質ゲートを担う設計になっているので、
- 注釈やテストやlintが足りないPRはAIレビュアーにREQUEST_CHANGESを付けられる
- 修正はAI対応エージェントが代行する
- 直らないとマージされない
という流れで、書いた人がエンジニアであろうとなかろうと、マージされる時点では同じ品質基準を満たしている状態が作れます。重要なのは、「自由にコードが書ける」のではなく「逸脱できないレールの上で書ける」こと。書く側の責任は「やりたいことを正確に伝える」ところまでで、コードの正しさはハーネスが担保しています。
「その人だから書けた」ではなく「cortexの上だから書ける」── これはハーネスを組み上げたことで初めて成立する性質で、cortex設計の根幹です。
何が動いているか
cortexで動いているアプリ(マイクロサービス・ジョブ・MCPサーバー・Webフロント・Cloudflare Workerなど)は、執筆時点で123個あります。これまでの記事で紹介してきた機能はそれぞれ複数のアプリの組み合わせで成立しているのですが、機能ベースで合算しても全体の約10%に留まり、残り9割は記事化していない機能です。例えば:
- プロダクトUX計測の集約Web ── UXメトリクス・画面分析・ファネル・エラー分析をひとつにまとめて可視化
- 開発組織のポータルWeb ── KPI(バグ発生率など)/ メンバー別のGitHub Activity / QA評価結果を可視化し、KPIに対する自然言語質問をAgentic RAGで返すAIチャット付き
- 業務支援系のSlack Bot群:
- 各種ジョブ設定(DB / 勤怠SaaS / Google Driveなど)をSlackから直接管理する設定管理Bot
- 請求書OCRから会計SaaSの支払依頼・経費精算申請の下書きを自動作成する経理アシストBot
- チャンネル情報検索・課題管理・要望管理・ミーティング作成を担う社内ナレッジBot、BigQuery横断RAG Bot、Google Drive横断RAG Bot
- BigQueryのマーケデータからインサイト(トレンド・クリエイティブ分析)を返すマーケBot
- APM自動分析エージェント ── 監視SaaSのAPMデータを毎日分析し、性能問題を自動検出して課題管理SaaSにチケットを作成
- AI Bot監査Bot ── 上記Slack Bot群のコマンド応答を自動E2Eテストして仕様逸脱を検出
など。シリーズの後半で順に各論を書いていく予定です。
規模感:
| 数 | |
|---|---|
| apps(マイクロサービス・ジョブ・MCP・Web等) | 123 |
| packages(共有ライブラリ) | 66 |
| MCPサーバー | 19 |
| Pulumiスタック | 110 |
| TypeScriptコード(実装) | 約63万行 |
| テストコード | 約56万行 |
| ドキュメント(Markdown) | 約11万行 / 389ファイル |
| 期間 | 約5ヶ月(本格開発は約4ヶ月) |
| マージ済PR | 約790 |
4要素のフライホイール ── cortexのハーネス
「本格開発4ヶ月でほぼひとり」と「非エンジニアもこの環境に直接コードを足せる」が両立できているのは、全レイヤーで品質をAIと自動化に委譲するハーネス設計をしているからです。
cortexのハーネスは、FowlerのGuides(事前制御)/ Sensors(事後制御)の4つの要素が互いに強化し合うフライホイールとして組まれています。
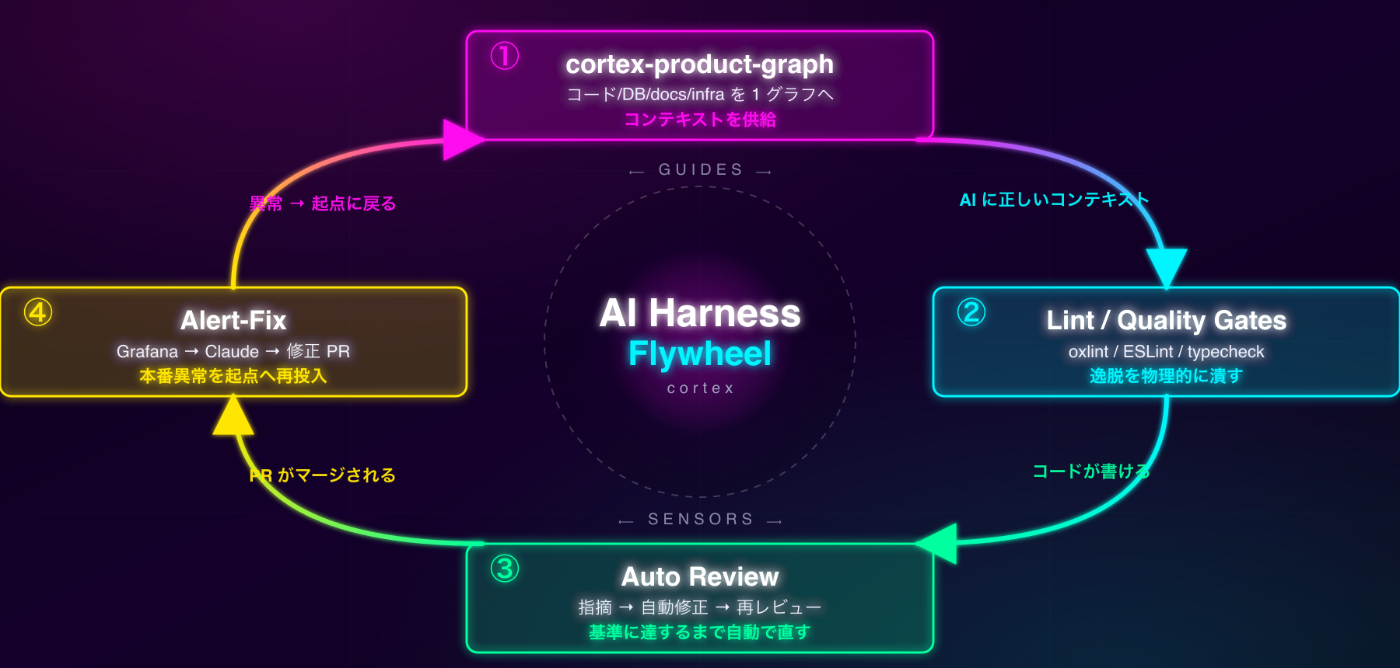
① Product Graph(Guides ── 正しいコンテキストを供給する)
cortex全体は、コード・ドキュメント・DBスキーマ・インフラ定義が1つのグラフに統合された状態でリアルタイムにインデックスされています。MCP経由でセマンティック検索できる。
「このKPIを計算しているコードはどこ?」「そのコードが触っているBQテーブルは?」「そのテーブルのカラム定義は?」「関連ドキュメントは?」── これらを1つの問い合わせで辿れるグラフが、AIのあらゆる作業の文脈源になります。
これは、AIが「迷う頻度を構造的に減らす」ための土台です。grepが「文字列がある場所」しか教えてくれないのに対して、Product Graphは「何が、なぜ、どう繋がっているか」を返す。実装の話は次回(Part 2)で詳しく書きます。
② Lint / Quality Gates(Guides ── 逸脱を物理的に潰す)
eslint-disable / oxlint-disableをリポジトリ全体で禁止。実装コード上の: any / as any / TODO / FIXMEも、自動生成ファイルや外部ライブラリ起因のやむを得ないケースを除いて0件です。型チェック(tsgo ── TypeScriptのGo移植版コンパイラでtsc比で10倍前後高速。CI時間を抑えるため採用)も全コード対象にCIで強制しています。
加えて、テストカバレッジはstatements / branches / functions / linesすべて90%以上をCIで強制。閾値を下げてカバーする運用は禁止で、テストを書くしかない。
逃げ道を全部塞いであるので、AIが間違ったコードを書いてもマージされない。AIレビューの判定もこれによって安定します。
③ Autoレビュー(Sensors ── 基準に達するまで自動で直す)
冒頭のシーン1がこれそのものです。仕組み側の補足としては、AIレビューは単なるlintの延長ではなく、Product Graphで影響範囲を辿った上での指摘になっている、というのが効きどころ。例えば実際に飛んでいる指摘を分類すると:
- [Graph] Critical ── 注釈漏れによってグラフのエッジが欠落するパターン
- [Impact] Critical ── BQ MERGE文が既存テーブルに存在しないカラムを参照、本番で失敗するパターン
- [Doc] Critical ── コード変更に関連docsが追従していないパターン
- [Security] Minor ──
execSyncで環境変数を文字列展開しコマンドインジェクションが可能になるパターン
「AIレビュー」と聞いて連想されるような表面的なものではなく、コードベース全体を文脈として保ったうえでの指摘が出るのが、Product Graphと組み合わさることの本質です。
エンジニアの介在は「AIレビューが詰まる難しいケース」だけ。普段のPRは、プッシュしてからマージまで触ることなく完結します。
④ Self-Healing(Sensors ── 本番異常を起点へ再投入する)
冒頭のシーン2がこれそのものです。Grafanaアラートを起点にAIがProduct Graph + Loki + git blameで根本原因を特定し、修正PRを ③ のAutoレビューに流して自動マージまでいく。異常を起点に戻して再投入する ── これがSensorsの本質です。詳細は別回で。
フライホイールとして何が起きているか
この4要素は互いに強化し合います。
- ① Product Graphがあるから、③ Autoレビューは影響範囲を踏まえた指摘ができる
- ② Lintがあるから、③ Autoレビューは「全コードが基準を満たしている」前提で動ける
- ③ Autoレビューがあるから、新しいコードが ① Product Graphに正しいセマンティック注釈付きで取り込まれる
- ④ Self-Healingが拾った本番異常も、③ を通すことで品質基準を維持しながら ① に戻る
コードが増えるほど、ハーネスの効きが強くなる構造です。
支える基盤層
この4要素を成立させるための土台として、3つの基盤があります(Part 4で詳しく書きます):
- テストとカバレッジ: 実装コード約63万行に対してテストコードが約56万行(実装:テスト ≒ 1.13 : 1)
- ドキュメント: 約11万行 / 389ファイル。人間とAIの両方が読む前提で書き、Product GraphのDocumentノードとしても取り込まれる
- Observability: フロント=Faro、バックエンド=OTel、インフラ・CIも含めて全部Grafanaに集約。人間が見るのと同じものを、AIも見ている。Gemini APIのトークン使用量とコストはPrometheusで別途計測
技術基盤
cortexは、フルTypeScriptのモノレポです。
| レイヤー | 技術 |
|---|---|
| アプリケーション(apps/) | TypeScript(Hono, TanStack Router, Vite, etc.) |
| 共有パッケージ(packages/) | TypeScript |
| インフラ(infra/) | TypeScript(Pulumiで書く) |
| エッジ(worker/) | TypeScript(Cloudflare Workers) |
| Lintプラグイン | TypeScript |
| docsスクリプト | TypeScript(tsx) |
すべて1言語で書ける状態にしてあるメリットはAIから見たときに大きいです。具体的には:
- AST / 型定義をそのままAIのコンテキストに食わせられる ── 言語境界で文脈が分断されない
- リファクタが言語境界をまたがない ── ESLintプラグイン1つでapps / packages / infra全部を一括で検査・自動修正できる
- Product Graphに乗せたときにエッジが切れない ── 例えばCloud Runのサービス定義(infra/TS)から、それが叩くAPIのHonoルート(apps/TS)まで、1つのグラフで繋がる
「この機能の影響範囲は?」をAIに聞いたとき、infra → apps → packagesを行き来して1ホップで答えが返るのは、これらが土台になっています。
ビルドはTurborepoとpnpm workspacesで並列化、デプロイはGitHub Actionsで変更されたスタックだけを検出してPulumiで並列適用しています。
数字(執筆時点のスナップショット)

| 値 | |
|---|---|
| 期間 | 約5ヶ月(本格開発は約4ヶ月) |
| コミット数 | 約4,000 |
| マージ済PR | 約790 |
| そのうち自分が書いたコミットの比率 | 約91% |
| apps | 123 |
| packages | 66 |
| MCPサーバー | 19 |
| Pulumiスタック | 110 |
| TypeScript(実装) | 約63万行 |
| TypeScript(テスト) | 約56万行 |
| Markdownドキュメント | 約11万行 / 389ファイル |
手書きコードのas any / TODO / 無理由lint-disable |
0(自動生成・外部ライブラリ起因を除く) |
| Coverage強制ライン | 90%(statements / branches / functions / lines) |
PR運用への切り替えで流量が一段変わった
実は4月までは、自分が手元でAIを使いながら徹底的にレビューして、そのまま直接mainにコミットするスタイルでした。レビューの厳しさは落とさない代わりに、捌ける本数は自分の手作業に律速される構造です。
4月からPR単位の細粒度運用(自動レビュー → 自動修正 → 自動マージ)に切り替えたことで、月別マージ済PRが劇的に変わりました:
| 月 | マージ済PR |
|---|---|
| 2026-02 | 10 |
| 2026-03 | 23 |
| 2026-04 | 518 |
| 2026-05(10日時点) | 235 |
3月から4月で約22倍。コミット数自体は逆に減っている(main直接コミットからPR経由に変わったため)ので、これは「書く量が増えた」のではなく「手作業のレビューがハーネスに置き換わって、捌ける流量が一段上がった」結果です。この22倍は、人間レビュアーがAutoレビューに置き換わった瞬間そのものであり、コードが増えるほど効きが強くなるフライホイールの性質がはっきり出ています。
数字が成立している前提設計
ここまでの数字は、「AIを使ったから」だけでは成立しません。前提として、
- フルTypeScriptモノレポ ── コード・テスト・インフラ・スクリプトを1言語の静的解析で横断
- Composable Architecture ──
packages/に再利用可能な部品を置き、apps/は部品を組み合わせて構成。apps/間の直接importは禁止し、必ずpackages/経由で接続することで互いに干渉しない設計を担保 - strictな品質ゲート ── lint / coverage / 注釈は「下げない・回避させない」運用
- 統合グラフ ── コード・docs・DB・インフラを1つのグラフに乗せ、AIが文脈を踏まえて動ける土台
- 自動PRレビュー / 自動修正 / 自動マージ / 自動自己修復 ── 律速段階を人間の手からAIに置き換えるハーネス
- 統合Observability ── 人間が見るのと同じデータをAIも見る(OTel + Faro + Prometheus)
という設計が先にあって、その上でAIが動いているから、量と質が両立しています。
特にComposable Architectureは手数の多さに直結していて、各コンポーネントが互いに干渉しないからこそ、Claude Codeを並列に走らせて別々の場所を同時に開発できる。実運用では最大10並列ほどで動かしていた時期もあり、これがハーネスの効きと掛け算になっています。
「魔法」ではなく「システム設計」の結果です。各論はこの後の連載で順に取り上げます。
正直に書いておきたいこと
ここまで読むと「全自動で完璧」に見えるかもしれませんが、現実はそこまでではないので、3つだけ正直に書いておきます。
1. コード品質が高くてもバグは起こる
ハーネスが守れるのは「コードの正しさ」であって「仕様の正しさ」ではありません。実装が綺麗に書かれていても、仕様の解釈を間違えたら結局バグは出ます。AIレビューが拾えるのは「コードと仕様(docs / コメント)が矛盾している」までで、その仕様自体が間違っていればすり抜けます。ここは引き続き人間の責務です。
2. 役割分担は明確に分けている
外部APIとの接続が必要な新規パイプライン開発や、Secureな情報を扱う部分はエンジニアが担当。非エンジニアは基本的にすでに作られている機能の改修が中心です。実際に最近マージされた事業側メンバーのPRを見ると、KPIダッシュボードに新しい指標カラムを足す、既存集計の絞り込み条件を直す、グラフUIに前週比カラムを追加する、UIの表示を整える、といった粒度です。「非エンジニアも開発できる」というのは、ハーネスが「逸脱しないレール」を提供しているから、改修フェーズで安全に手を入れられる、という話で、ゼロから何でも作れるという話ではありません。
3. 社内基盤だからこのレベルまでできた
cortexがデプロイまで全自動にできているのは、もちろんComposable Architectureでアプリケーション / インフラが分離できていることもありますが、正直なところ社内向け基盤であることが大きいです。トラブルが起きても困るのは社員だけで、即座に巻き戻せばいい。ToCのプロダクトや、WMSのように停止が即Criticalになるシステムで同じことはできません。少しでも近づける動きは別途始めているので、それはまた別の機会に書きます。
次回以降のロードマップ
このシリーズは全6回を予定しています。
Part 1: 総論(本記事) cortexがどんな環境で、なぜ「ハーネス」という形で機能するかの全体像。シリーズ全体の地図役。
Part 2: Product Graph ── コード・docs・DB・インフラを1つのグラフに統合する ★最初に読み進めるおすすめ この統合グラフがどう構築・維持されているかの実装編。直前のAgentic Graph RAG MCPの記事で書いた設計原則をcortex全体に適用するとどうなるか。
Part 3: AIがPRをレビューし、修正し、マージし、デプロイする GitHub webhook → AIレビュー → REQUEST_CHANGESならworktreeでAI修正 → 自動squash merge → 変更スタック検出 → 並列デプロイ、までの全フロー。
Part 4: 障害が自動で直り、ガードレールが自動で増える Grafanaアラート → AI調査(Loki + Product Graph + git blame)→ 修正PR + 新規lint/型gateの追加 → 自動マージ → 自動再デプロイ、の自動自己修復システム。フルOTel + Loki + Mimir + Tempo + Faro構成と、品質ゲートが「下げない・回避させない・自動で増える」設計になっている話まで含む。
Part 5: 非エンジニアが本番にPRを出す ── 改修フェーズの民主化 AIレビューと自動化が品質ゲートを担った結果、業務要件を把握している非エンジニア(事業マネージャー / PMO等)がエンジニアを介さず本番リポジトリに直接PRを出せるようになった話。何ができて何ができないか(レールを敷くのはエンジニア / レールの上を走るのは誰でも)、この型を本番toCサービスへスケールする構想まで。
Part 6: AIは信用するものではなく設計するもの ── 連載総括 各機構の根底にあるひとつの思想の整理と、そこに至るまでに何を捨てたか・失敗の振り返り。
それぞれ単独でも読めるように書きますが、Part 2(Product Graph)は他の各論の前提になるので、Part 1 → Part 2 → 任意の順で読むのがおすすめです。
公開ペースは火または木の朝8〜10時JSTを予定しています。
おわりに
cortexを作っていて感じるのは、AI時代の開発環境では「書く側の負担を減らす」よりも「書いたあとを全部受け止める」方が効くということです。テスト・lint・型・カバレッジ・コードレビュー・障害対応 ── これらを「邪魔だから減らす」ではなく「全部AIに任せて代わりに徹底する」と決めると、品質を上げながら同時に開発速度も上がる、という反直感的な状態が成立します。
そしてそれは、ひとりのエンジニアが書ける量や、エンジニア以外が参加できる範囲を、これまでよりも大きく押し上げてくれます。これが、cortexの上に組み上げた「ハーネス」の手触りです。
次回からは、これを実現している個別の仕組みを順に見ていきます。
comments (15)
The "non-engineer contributors" piece is the most interesting and most dangerous part of this. A real harness (auto-reviewed PRs + self-healing ops) is exactly what makes it safe to let non-engineers contribute - the guardrails do the gatekeeping a senior used to do manually. Without that harness, non-engineer contributions are how you get the 3am incident. So the harness isn't just productivity, it's the trust boundary. Auto-review catches the "looks right, is wrong" PRs; self-healing absorbs the operational mistakes; and only then can you safely widen the contributor pool. Looking forward to the series - the part I'd most want detailed is how strict the auto-review gate is, because that single threshold decides whether "non-engineer contributors" is empowering or terrifying. Strong intro, subscribed.
Thanks — and "harness as trust boundary" is a sharper framing than I had in my head. The 3am incident line in particular: yes, exactly the scenario the harness has to absorb. On the strictness question — [Part 3](https://dev.to/ryantsuji/human-on-the-loop-ai-reviewing-ai-prs-at-cortex-769-prsmonth-while-raising-the-quality-bar-4lh5) (just out) goes deep on this. Short version: PRs go through an average of 10.8 review-fix iterations before merge (max 56). 9 dimensions are reviewed sequentially under a strict no-downgrade rule, and the usual excuses ("existing code has the same issue", "will fix later", "leave a TODO") are explicitly closed off. At the meta-layer, quality-bar relaxation itself (lowering a lint rule, coverage threshold, or guideline binding) is classified Critical and the AI is forbidden from approving it — a human reviewer's approve is required ([severity.md](https://github.com/air-closet/cortex-review-guidelines/blob/main/en/guidelines/severity.md)). What this means for non-engineer contributors specifically: they can't land something that violates the contract. The strictness isn't relaxed for them; they just get more iterations, and the iteration cost is paid by the author-side AI, not by the contributor's morale. So "empowering vs terrifying" resolves toward empowering — the contributor never personally wrestles with the lint or test details. The AI does that work. And the gate doesn't stay static — Part 4 (coming soon) covers how bug-fix PRs are required to add a prevention layer in the same PR, with a strict priority order: code/logic > lint > guideline. Every review-time catch gets promoted toward generation-time enforcement, so the gate strengthens autonomously over time — not just self-healing, but self-strengthening. Part 5 will dig into where the actual boundary sits in practice (existing-pipeline extension: yes; new architectural patterns: not yet). Thanks for the framing.
accountability gap on non-engineer push is the part that gets messy fast - if a sandbox app fails in prod, who owns the fix? not obvious when the contributor can't debug the stacktrace.
Great question. The ownership question lands on me, the CTO. The whole point of opening this work up to non-engineers is that the surrounding environment is supposed to hold even when the contributor can't debug a stacktrace — designing that environment is on me, and so is everything that breaks because the environment didn't hold yet. If a problem surfaces, the fix and the work to prevent it from happening again are the same delivery. In practice it hasn't gotten messy yet, partly because self-healing catches most issues before anyone has to debug anything. I'll cover that in detail in Part 4 of the series. The bigger qualifier: this is an internal platform, not customer-facing product code. We're starting to extend similar guardrails to our user-facing product, but I'm not opening non-engineer pushes to that side anytime soon — for that surface, human verification is still a hard requirement.
most teams try to split it - builder vs. environment designer. you end up with two people to blame and neither one fixing it. what you're describing sidesteps that cleanly.
On the Product Graph -- what's the freshness model? Does it ingest code changes async (via webhooks/CI) or pull on-query? Asking because the auto-review quality probably correlates strongly with how stale the graph is at moment-of-comment; if a PR touches a file the graph hasn't reindexed yet, the impact analysis is partial. Curious how you handle that at 4,000 commits / 5 months scale.
Great question — this is exactly the right place to push on. The freshness model is async via CI on push-to-main. GitHub Actions triggers a Cloud Run Job that rebuilds the graph with differential embedding (only nodes whose textForEmbedding changed get re-embedded via Vertex AI), so a typical push costs ~$0.001 and finishes in a few minutes. You're right that this means PR review can hit a stale-graph window. Two things soften it more than the raw freshness suggests: PR review reads diff + graph, not just graph. The PR diff carries the change itself; the graph provides the surrounding context. So even a function the graph hasn't seen yet has its definition in the diff. The AI reviewer reasons about both. MCP tools have graceful fallback. When the graph misses (e.g., a function freshly added in a sibling PR), the AI falls through to grep_code / read_file against the live git tree via our git-server MCP. So "graph miss → silent failure" doesn't happen — it's "graph miss → fall through to raw code search". Worst case — a large refactor landing in main while a related PR is open against the old base — the answer is rebase, not graph freshness. For larger scale than ours, the next obvious step would be PR-branch-aware indexing (transient graph for the PR head ref). We haven't needed it yet at 4K commits.
Good point to add on top of what I said: even if a review runs against a stale-ish graph, the merge itself is gated by (a) conflict resolution and (b) re-review on push. So if main moved enough to matter, the PR can't merge cleanly, and once rebased the re-review runs against the now-updated graph. The "stale graph + merged change" pathological combination is structurally hard to hit.
The diff-as-context plus MCP-fallback composition is the right shape. One thing I'd ask at larger scale: when the fallback kicks in (grep_code / read_file against the live tree), what's the fan-out cap per review? Watching agents work in our codebase, the cost of an unbounded grep walk -- function ref → usage → containing test → unrelated helper — sometimes dwarfs the embedding miss it's filling in. Does cortex's reviewer prompt enforce a depth/budget heuristic, or does differential embedding keep fall-through rare enough that it's not worth bounding?
The honest answer here is closer to your second framing — differential embedding keeps fall-through rare enough that we never bothered with an explicit fan-out cap. Two softer things do the bounding: Per-tool response size limits. grep_code returns capped output, and files in this repo are small (a 500-line max-code-lines lint rule enforces it). A single fallback call can't return enough for the reviewer to lose itself in unrelated context. The reviewer is anchored on a documented guideline, not a free-form prompt. We maintain a review guidelines doc that spells out review criteria and severities — composable architecture, impact analysis, security boundaries, test coverage, doc/spec alignment, etc. The reviewer prompt requires reading and applying these for every review, so the work is shaped as "verify the PR against these criteria" rather than "walk around the codebase and tell us what you see." That framing pulls the AI's attention back to the diff and the listed criteria, instead of an open investigation. We also have an MCP-layer mechanism that scopes AI review more deliberately. I'll cover it in the next post in this series, going up around Tuesday next week. At larger codebase size or higher cross-cutting churn, both bounds would probably fray, and that's where a hard depth budget on trace or a token-based circuit breaker becomes the right call.
The "reviewer anchored on documented guidelines, not free-form exploration" is the part that makes the fan-out question almost moot — bounded scope shrinks the surface area before any token math kicks in. We hit a smaller version of this with cursor rule files in equip. When the rules are specific (one file per area, banned patterns, naming conventions), the agent stays inside lanes even on large diffs. When they drift toward generic "follow best practices", token usage balloons because the model fills the gap by reading everything. Token-based circuit breaker as v2 makes sense, but the guideline anchor is the real circuit breaker. Same playbook as the invariants-in-PR pattern you described upthread.
Big concern from experience: self‑healing can create a “heal and hide” pattern where the same issue recurs and is silently fixed without anyone noticing the root cause is still rotting. Do you pair auto‑healing with mandatory root‑cause logging, or does the system just patch and move on? This is where AI goes from toy to force multiplier. Auto‑reviewed PRs and self‑healing ops aren’t sci‑fi anymore; they’re team‑extenders. I like that you even thought about non‑engineer contributors — that’s where real org‑wide impact lies. What if the self‑healing steps were always proposed as a “suggested action” with a 5‑minute delay, and only auto‑execute if no human overrides? That gives you a semi‑autonomous system that teaches rather than hides.
Heal-and-hide is the right anti-pattern to name. The way we avoid it: every auto-fix PR carries 3 artifacts beyond the code change. The fix itself A pattern doc entry (problem, solution, code example, checklist) A 1-line invariant added to the agent's persistent rules file, so the next agent run already has the pattern in context Concrete example from a recent fix: a Cloud Run deploy failed because secretKeyRef version:latest was pointing at a Secret with no versions. The auto-fix PR added the placeholder SecretVersion to unblock the deploy, and the same PR added a 40-line entry to our cloud-run-deploy guideline (problem, solution, code, checklist) plus a 1-line invariant to the agent's rules file. The next agent that touches a Cloud Run service with secretKeyRef sees the pattern before it codes. Patch-and-move-on is a real risk, agreed. Our answer is making the docs and invariant update part of the PR scope itself. If the agent doesn't generate the learning artifact, the PR isn't ready for review. On your 5-min delay suggestion: we use the code review window (auto-review agent + human approval) as the override surface instead of a time window. Different trade on the gate, same goal.
Solid pattern. Baking the learning artifact into the same PR scope closes the loop cleanly — fix, doc, invariant, all in one atomic commit. That's not self-healing anymore, that's self-documenting TDD for ops. One edge I'd watch: invariant collision. As the rules file grows, two invariants can silently contradict under a narrow condition. Do you have a reconciliation mechanism, or does the review surface catch that before it commits? Curious if you've considered a periodic "rule set lint" pass — treat invariants like a test suite that can be checked for internal consistency.
Nice catch. That gap was missing. Implementing it is cheap in our setup: every doc (including the review guidelines) is ingested into the knowledge graph and the agent reaches it via MCP at any time. Just opened a PR to add rule set lint to the review guideline. Thanks!