みなさまこんにちは!エアークローゼットでCTOをしている辻です。
連載5本を通じて、cortexのハーネスがどう組み上がっているかを機構ごとに書いてきました。総論 / ナレッジグラフ / Auto Review / Self-Healing + 再発防止 / 非エンジニアPR ── ひと通り見たうえで、最後にもう一段下の話をしておきたい。そもそもなぜこれを作っているのか、根っこの思想の話です。
5本の記事はそれぞれ独立に見えるかもしれませんが、根っこは1つで、それを言語化しておかないと連載の輪郭がぼやけて閉じない、という感覚があります。あわせて、ここまでの記事では「うまく回っている結果」を中心に書いてきたので、その裏で踏んできた失敗 ── 何を捨てたか / 何でつまずいたか ── も振り返ります。同じようなことを始めようとしている人にとっての参考になれば、と。
連載一覧
| # | テーマ | キーシーン | 記事 |
|---|---|---|---|
| 1 | 総論:cortexのハーネス | PRが無人マージ / 障害が気づく前に直っている | ai-harness-intro |
| 2 | Product Graph (cpg) | コード・ドキュメント・DB・インフラを1グラフに統合 | cortex-product-graph |
| 3 | AI PRレビュー | webhook → AIレビュー → 自動修正 → squash merge | cortex-auto-review |
| 4 | Self-Healing + Observability + 自動lint追加 | アラート → AI調査 → 修正PR + 新規lint/型gate → 自動再デプロイ | cortex-self-healing |
| 5 | 改修フェーズの民主化 | 業務要件を把握している人が本番に直接PR、ハーネスが品質を担保 | cortex-non-engineer-prs |
| 6 | 連載総括 | 根底にある思想(何を捨てて何を取ったか / なぜこの設計か)と失敗の振り返り | 本記事 ←現在地 |
起点 ── 2025年に考えていたこと
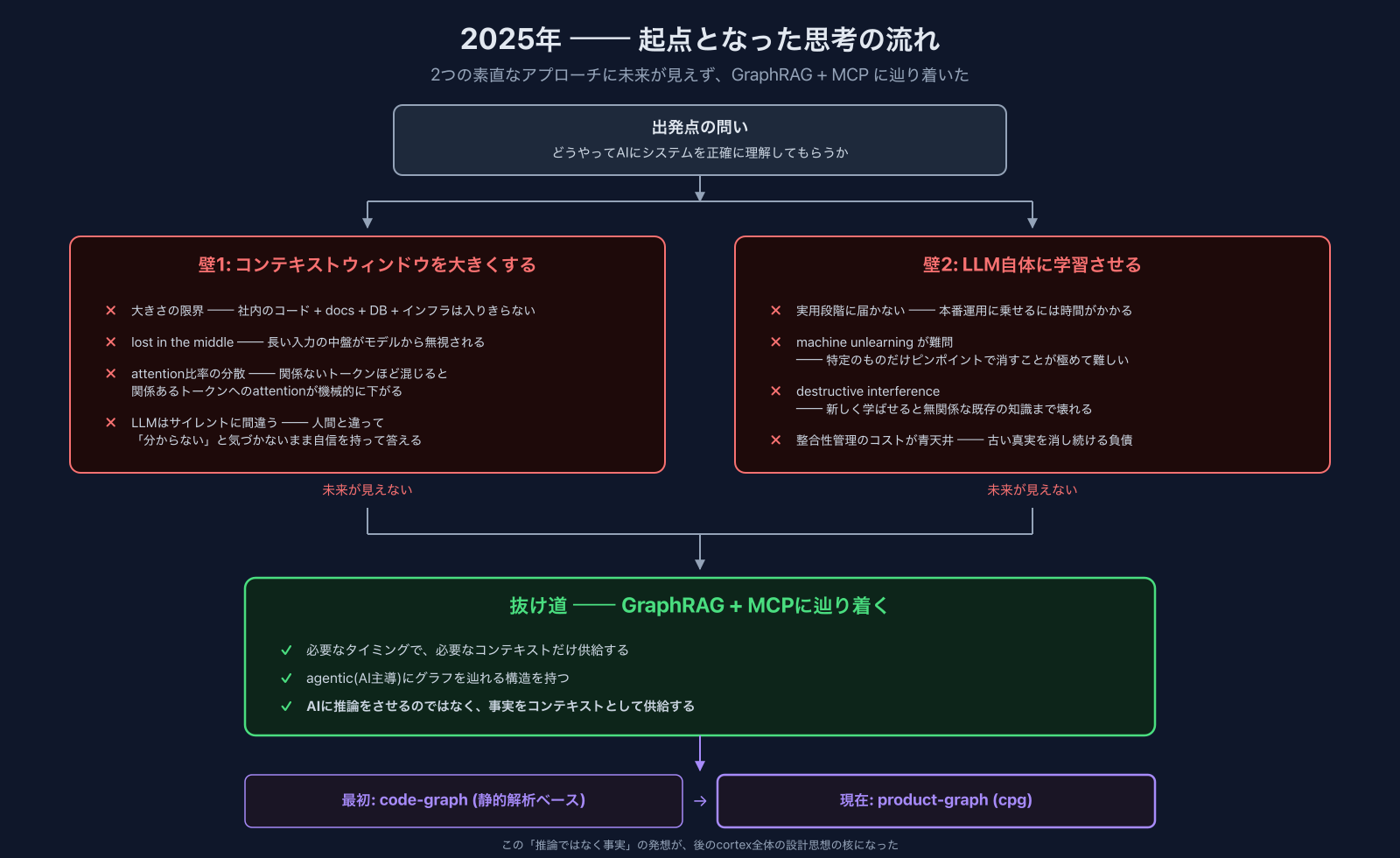
cortexを作り始めた頃、自分が答えを出したかった問いは1つでした。
どうやってAIにシステムを正確に理解してもらうか
AIがシステムを正確に理解できさえすれば、PRレビューもバグ調査も修正も任せられるし、エンジニアではないメンバーにも開発を開放できる、という直感がありました。逆に言うと、「正確に理解してもらう」ところで詰まっている限り、その先のすべては不安定に乗っている。だから機構ごとの工夫よりも前に、前提のところをどう実装するかを考える時間が長かった。
ただし、ここに対する素直なアプローチはいずれも壁にぶつかります。
壁1: コンテキストウィンドウの限界
最初に考えるのは「必要そうな情報を全部渡せばいいのでは」というアプローチです。コードベース全部 + ドキュメント + DBスキーマ + インフラ定義をプロンプトに乗せれば、AIは全体像を把握できるはず。
これは大きさの面で破綻します。社内のコード・ドキュメント・スキーマ・インフラを全部足すと、現実的なコンテキストウィンドウには収まりません。
「ではコンテキストウィンドウがもっと大きくなれば解決するのでは」── これも、考えれば考えるほど未来がないと思いました。
Geminiのようにコンテキストウィンドウが非常に大きいモデルでも、限界近くまで使うと挙動が不安定になります。中盤の情報が拾われなかったり、関係ない情報に引きずられて結論が変な方に振れたり。これはattentionの構造的問題で、関係ないトークンが混じるほど関係あるトークンへのattention比率が機械的に下がります。研究上は "lost in the middle"(長い入力の最初と最後にある情報は使われるが、真ん中に置かれた情報は事実上無視されやすい現象)として知られていて、コンテキストウィンドウに何でも詰め込むと、入れたつもりの情報がモデルから見えていない、という状況が普通に起きます。
「lost in the middle」自体はlong-contextモデルが進化すれば緩和される可能性があり、そこは経験的な傍証として捉えています。本当に効くのはもっと根本的な再帰の方の問題です。「大きさ」を解決しても、次に「その中からどれが必要でどれが不要かを判断するための、上位のコンテキスト」が必要になる。これは再帰的な問題で、コンテキストウィンドウのサイズでは原理的に解けない。情報を構造化しない限り、AIは正しい判断をしてくれない ── これは人間にも当てはまりますが、人間より一段悪いのは、LLMは「分からない」と気づかないまま自信を持って答えるところです。サイレントに間違うほうが、はっきり詰まるよりタチが悪い。
コンテキストウィンドウを大きくする方向には、根本的な解決の絵が見えませんでした。
壁2: 学習に頼る方向も外す
もう1つ素直なアプローチは「AI自体に学習させる」ことです。組織ごとにファインチューニングして、自社のコードベース・ドキュメント・業務を覚えさせる。これも考えましたが、現状外しています。
理由は2つ。1つは、学習を実用に乗せるのは(2025年当時も、書いている2026年現在も)まだ研究フェーズで、本番運用に乗せるには時間がかかること。もう1つは、より厄介な問題で、仮に学習できたとしても「忘れさせる」ことが極端に難しいことです。
業務システムでは「今の真実」が要件です。設計変更 / DBスキーマ変更 / ビジネスルール変更があると、古い知識は能動的に消したい。ところがLLMの重みに焼き付いた知識を「特定のものだけピンポイントで消す」のは未解決の難問で、machine unlearning という分野名がついている程度には難しい。さらに新しいことを学ばせる過程で無関係な既存の知識まで壊れてしまう現象(destructive interference / catastrophic forgetting)も知られていて、学習に倒すとこの2つが同時に効いて整合性管理のコストが青天井になります。
「学習しないこと」をネガティブに捉えるのではなく、学習しないからこそ外部の知識を差し替えるだけで現状を反映できる、と素直に受け止めるほうが整合性管理は楽になる ── これが当時の判断でした。
抜け道 ── GraphRAG + MCPに辿り着く
コンテキストウィンドウの方向にも学習の方向にも未来が見えなかったタイミングで、GraphRAGの概念に出会います。
GraphRAG自体は外で広く議論されている概念ですが、自分にとっての意味は「必要なタイミングで、必要なコンテキストだけ供給する」という発想でした。ここにMCP(Anthropicが定義したLLMと外部ツールの接続プロトコル)を組み合わせると、AIが自分で必要な情報を取りに行ける形になる。
決定的だったのは、これがagentic(AI主導)にグラフを辿れる構造を持っていたことです。AIに「全部読ませて推論で関連箇所を見つけてもらう」のではなく、AIが自分で必要なノードまで辿り着いて、事実として取り出せる。これは、
AIに推論をさせるのではなく、事実をコンテキストとして供給する
という形に整理できます。この一文が、後のcortex全体の設計思想の核になりました。
最初に着手したのは静的解析ベースの code-graph でしたが、これは試行錯誤の末に捨てて、annotation-baseの product-graph (cpg) に辿り着きます(詳細は試行錯誤の章)。
そもそもAIを信用していない
起点章を一言にまとめると、結論はこうなります。
AIを信用していない
ここでいう「信用していない」は、信頼していないとは違います。Claude / GPT / Geminiの生成品質を疑っている話ではなく、こういうことです。
- 渡されていないコンテキストのことは知らない
- 何も言わなくても理想状態を作ってくれるとは考えていない
前者は、どれだけモデルが進化しても変わらない真実です。LLMのアーキテクチャ上、訓練データに無いことや、そのsessionのコンテキストに無いことは、原理的に把握できません。「将来モデルが賢くなれば自動で察してくれるのでは」── そういう未来は来ない、と思っています。賢くなる方向はあっても、賢いだけでは無いものは知り得ない。
後者は、人間が定義する責任の話です。AIは「何が理想か」を勝手に決められません。決めようとすると、現場と少しズレた一般論に着地します。何が理想かは、その業務・その組織・その時点のビジネス状況に依存していて、これは人間側が言語化して渡さない限りAIには見えない。
だから「AIを信用していない」というのは、AIの能力を過小評価している話ではなく、AIに前提条件を自動補完させない、という設計判断です。
「AIを使いこなす」とは、AIに自由を与えることではなく、AIの出力を予測可能な範囲に閉じ込めることだと考えています。
閉じ込めるための仕組みが、連載で書いてきたハーネスです。
だからハーネスで決定論に寄せる
各機構を「AIに推論させず、決定論に寄せる」というレンズで読み直すと、5本の連載で書いたものはすべて同じ思想の異なる現れだということが見えてきます。
Part 2 ── ナレッジグラフ: コードベースをAIに探させる代わりに、コードベース側を読みやすく整える方向に倒した機構です。@graph-* annotationでコード / docs / DB / インフラを1つのグラフに統合し、AIがgrepと推論で関連箇所を探さなくて済むようにしました。これは起点章の「事実をコンテキストとして供給する」の直接的な実装です。→ cortex-product-graph
Part 3 ── Auto Review観点: 9つの観点(responsibility / severity / type SSoT / etc.)が事前に固定されています。AIにレビューを任せるとき、何をチェックするかを推論させないようにする設計です。「全体としてどうか」を聞くと推論の余地が広がりすぎるので、観点を細かく分けて観点ごとに個別の問いとして判定させる。観点 = ハーネス側で固定、評価 = AIに任せるという役割分担。→ cortex-auto-review
Part 4 ── Self-Healing + 再発防止: アラート → 調査 → 修正PR → 再デプロイ ── このフロー自体が固定されています。AIに「障害が起きたらどう対応するか」を毎回考えさせない。さらに、同じ罠を二度踏まないようにlint / CI gateを追加する再発防止のループは、推論ではなく機械的な拒否で同じ事故を排除する仕組み。「AIが二度同じミスをしない」を期待していない、と言い換えてもいい。→ cortex-self-healing
Part 5 ── 非エンジニアPR: ハーネスが品質を担保していなければ、業務側が直接PRを出すなんて成立しません。逆に言うと、ここまでのPart 2〜4で積み上げた機構(コンテキスト確定 / 観点固定 / 罠の機械的排除)が揃ったから、業務要件を一番把握している人が直接書ける状態が成立した。翻訳レイヤーと優先順位待ち行列が消えたのは、決定論に寄せた結果として後から現れたものです。→ cortex-non-engineer-prs
つまり、ここまで書いてきた4つの機構と、その上に成立した非エンジニアPR ── これらはすべて「AIに推論させず、決定論に寄せる」をいろいろなレイヤーで実装した結果であり、根っこは同じ思想にぶら下がっています。
「AIに推論させず、決定論に寄せる」とは
ここまで何度か出てきたこのフレーズの解像度を、もう少し上げておきます。
「決定論に寄せる」は、AIが推論する余地をゼロにするという意味ではありません。コード生成・レビュー指摘・エラーログからの原因推定 ── こういう「変動が許容される領域」では、むしろAIに推論してもらわないと話が進みません。
寄せたいのは「変動を許してはいけない領域」のほうです。具体的には:
- どのコードベースを見るか ── 推論で類推させず、ナレッジグラフから確定的に取り出す
- 何の観点でレビューするか ── AIに「重要そうな観点」を選ばせず、観点リストを事前に固定する
- 障害対応のフローはどう動くか ── AIに毎回フローを考えさせず、アラートから修正PRまでの経路を決める
- 同じ罠を二度踏まないこと ── AIに「気をつけよう」と思わせるのではなく、lint / CIで機械的に拒否する
この線引き ── 「推論させていい場所 / 推論させてはいけない場所」── を実装したものがハーネス、というのが今の整理です。Part 5で使った比喩を引き継ぐと、ハーネスは「踏み外せないレール」を敷いている。レールの上では自由に走れる(推論は推論として活きる)、でもレールを踏み外す方向には動けない。
別の言い方をすると、これはPart 2(cortex-product-graph)で書いた「ハルシネーションをどこに閉じ込めるか」と等価です。「推論させない」と言い切ってしまうと厳密にはズレていて、ハーネスはハルシネーションをゼロにする仕組みではなく、起こっても大丈夫な場所(推論させていい領域)にだけ閉じ込める仕組みです。コードベース全体の構造や事実は決定論的に取り出されるので取り出しの過程にハルシネーションが入る余地が無く、判断側で起こったハルシネーションは下流のテスト / lint / 観点別レビューで弾かれる。ハルシネーションが許されている場所と、許されていない場所を、ハーネスで物理的に分けている、というのがPart 2で立てた話の続きになります。
もう一段視点を引くと、ハーネスがやっているのは推論の発生時刻をずらすことでもあります。グラフに乗っているannotationや説明文も、元はAIが書いていて、そこには確かに推論が入っています。ただしそれは write-time ── 一度だけ発生し、レビューを通って凍結された推論 ── であって、read-time(クエリのたびに毎回発生し、その時点では未検証)ではない。グラフは「凍結され検証済みの推論」であって、だからこそ読み出し側で事実として扱える。「決定論に寄せる」と言っているのは、検証されていない推論をクエリのたびに走らせないこと、と言い換えてもいい。

これは連載Part 1(総論)で書いた「モデルはコモディティ化する、ハーネスで差別化」の根拠でもあります。モデル単体の品質はClaude / GPT / Geminiの間で差が縮まっていますが、ハーネスはコードベース固有 / 業務固有なので、ここを整えるのが組織としての差別化になる。
念のため触れておくと、この境界線の位置はモデル性能に依存して動きます。agentic searchや推論能力が向上すれば、今日決定論が必要としている領域も、明日は推論で足りるかもしれない(実際cortex自身も、ハーネス内でAIにagenticにグラフをtraverseさせる形で、AIの発見能力に依拠しています)。ただ、境界線そのものが消えることはありません。情報をどう構造化するか、どこから先を推論に任せるか ── これを 明示的に設計として持っているか否か が、どのモデル世代でも組織としての差になります。
なお、この発想 ── 決定論で適切なコンテキストを渡し、AIに推論させない ── はcortexのハーネスだけに閉じた話ではありません。社内DBスキーマを自然言語で検索できるようにするdb-graph MCP、非エンジニアがAIで作ったアプリを安全に公開できるSandbox MCPなど、社内でAIを使う他の基盤も同じスタンスで作っています。AIを使って何かを成立させる基盤すべてに通底する考え方だと思っています。
もう一段抽象化して言うと、個別の機能そのものに本質的な価値があるわけではない、ということでもあります。価値があるのは思想の側で、cortex / db-graph / Sandbox MCPのそれぞれの実装は、その思想を自分たちのユースケースに具体化した結果に過ぎません。
ここで言う「設計」を、自分は次のように定義しています。
設計とは、抽象的な思想を、自分たちのユースケースに合わせて具体的な実装へ落とし込むこと
クラス図を描く作業でもなく、アーキテクチャ図を整える作業でもなく、「自分たちの業務 / コードベース / 制約のもとで、この思想がどう形になるか」を翻訳する仕事こそが設計です。ここに各組織の固有性が宿り、コピーできない価値が生まれる。
逆に言うと、別の組織がcortexの見た目をそのままコピーしても本質を再現したことにはならず、自分たちのユースケースに対してこの思想をどう具体化するかが、それぞれの組織で問われる、ということでもあります。
ここに辿り着くまでの試行錯誤
ここまで「うまく回っている結果」を中心に書いてきましたが、最終形に辿り着くまでには何度も捨てた選択肢があります。代表的な3つを残しておきます。
静的解析ベースのcode-graphを2ヶ月かけて捨てた
最初に着手したのは、静的解析でコード構造を抽出してグラフ化する code-graph という方向でした。AST(抽象構文木)からimport関係 / 関数の呼び出しグラフ / 型の依存関係を機械的に取り出して、グラフDBに乗せる。「AIにコードベースを理解させる」の素直な実装に見えました。
cortexを作り始めた最初の3ヶ月のうち2ヶ月をこれに費やして、一通り動くものは出来ました。
でも、捨てました。
理由は、静的解析は構造を捉えるのは得意ですが、意図やビジネス文脈で辿れないからです。具体的に詰まったのは3点:
- 意味で検索する入口がない ── 「会員のサブスク料金計算をしている関数を出して」というクエリでコードを引きたいのに、関数名やファイル名を先に知っていないと辿れません。静的解析だけで作ったグラフには「何のための処理か」という入口の意味タグが乗っていない
- ノードがコードしかない ── 内部関数 / utility / 型 / 引数 / すべてがノードになるので、ある関数から関連箇所を辿ると数ホップでhelperやprimitiveまで巻き込んで爆発します。意味的な関連性で絞る軸がない
- 本来欲しかったのは「コード + DBスキーマ + ドキュメント + インフラ」が同じグラフに乗っていること ── ある関数を見たら、それが触るDB tableと、設計が書かれたドキュメントと、紐づく業務要件まで、1回のクエリで一括で取り出したい。コードだけのグラフではこれが不可能
→ annotation-basedのアプローチ(@graph-* JSDocタグで各コードに業務責務を書き込み、それをDBスキーマ / docs / インフラ定義のグラフと統合する)に切り替えました。意味で検索でき、辿るときも関連性のあるものだけが出てくる、というのが現在の product-graph (cpg) です。サンクコストに引っ張られると最終形に辿り着けない ── 2ヶ月の投資を取り返そうとせず捨てた判断が、後の機構すべての土台になりました。
Coverage 90%以上を目標にしたら実装が劣化した
テストカバレッジは現在も90%以上を条件にしています(Part 3でも触れた通り)。これ自体は維持していますが、過去にCoverageだけを単独の目標として扱った時期があり、そのときは逆に実装が弱くなる現象が出ました。
具体的には:
- デフォルト値を多用して条件分岐を見せなくする:
function(input = {})のような書き方で、欠落入力に対する条件分岐をテスト経路から消す。Coverageは上がるが、想定外入力に対する保護は消えている - エラーをthrowしないで黙って吸い込む: try / catchで握り潰して
return nullする。throwを書かないので「throwしないケース」のテストだけでCoverageが満たせる。でも不正状態がサイレントに進む - 早期returnでロジックを単純化しすぎる: 複雑な条件を「いったんreturn」で逃がす。テストは通るが、本来あるべきバリデーションが抜ける
結果として「Coverage 90%だが、品質は下がっている」状態になります。Coverageというメトリクスを単独で見ると、それを満たす最短経路として「テストの通る弱い実装」が選ばれる。
教訓は2つ:
- 数値目標を立てるとそれが目的化する。Coverageは「最低限満たしてほしい床」であって「達成すべき目標」ではない
- メトリクスは単独で評価しない。Coverageに加えて、責務分割 / 例外設計 / 境界値の網羅 / etc.を別観点として評価する必要がある
そして対策として、Coverageを満たすために実装を弱くする経路自体を機械的に塞ぐlintを整えていきました。具体例を2つ:
no-silent-catch: 空のcatchブロックや.catch(() => null)のようなsilentパターンを禁止。catch内で何らかの関数呼び出し(logger含む)/ 再throw / new / await が無いとエラーになります。「throwを消して握り潰せばCoverageは上がるが、本番では失敗が観測できない」という典型的なズレを構造的に防ぐ。違反時のメッセージで@cortex/otel/loggerでの構造化ログ出力を案内し、Cloud RunのOTelパイプライン経由でLoki / Grafanaに届くようにする経路まで揃えていますvitest-strong-matchers:toBeTruthy/toBeDefined/toContain/toBe(true|false)/expect.any/expect.objectContaining等の弱いmatcherを禁止。「とりあえず通るassertion」でカバレッジだけ稼ぐパターンをASTレベルで阻止し、toStrictEqual/toMatchInlineSnapshotのように出力全体を固定するmatcherへ誘導します。これはCoverageそのものより一段上のテスト品質の話ですが、「数値を目的化させたら実装が歪む」という同じ反省から並びます
加えて、cortexのテスト品質ガイドラインの冒頭で「カバレッジは目的ではなく補助指標」を明文化し、閾値の引き下げ・istanbul ignore での回避もCriticalで差し戻すようAuto Reviewの観点に組み込みました。Coverageを満たしている実装でも、「条件分岐を意図的に削っている」「例外を握り潰している」と判定されればMajor指摘が返ります。
数値目標で実装が歪んだ反省から、ガイドラインで思想を明示 → lintで機械的に弾く → Auto Reviewで観点として評価まで降ろして、ようやくCoverage 90%が「最低限の床」として機能するようになりました。これもPart 4で書いた再発防止(同じ罠を二度踏ませない構造)の系譜です。
並列sub-agentから順次評価への切り替え
3つ目はAuto Reviewの内部構造に関する話。9観点を並列sub-agentに分散して同時並行にレビューさせる── 一見「並列なら速くなる / 品質も担保できそう」に見えるこの設計を最初に試して、捨てました。
実際には、時間もコストも精度もすべて落ちることが分かりました。
- 時間がかかる ── sub-agentの起動、各sub-agentへのコンテキストロード、結果の集約、それぞれにオーバーヘッドが乗ります。「9並列だから9倍速い」にはならず、1つのsessionで順番に評価するより遅くなることもありました
- コストがかかる ── 各sub-agentは独立にPRのdiffとガイドラインと関連コードを読み直すので、共通のコンテキストロードが9回走ります。実測で9倍ではなく4倍弱のトークン消費(diff以外のコンテキストは多くの観点で共通だったため、9倍まで膨らまずに収まったという内訳)
- 精度が高くない ── 並列sub-agent同士は互いの判定結果を見ずに独立に評価するので、同じ問題に対して片方が「APPROVE」、もう片方が「REQUEST_CHANGES」のように食い違う指摘が出ます。同じ指摘の重複も多発。「全体としてどういうPRか」を踏まえた判定ができないので、観点を分けるほど局所最適になり、全体の整合性が下がる
順次評価に切り替えると、同じsessionで9観点を順番に判定するので、コンテキストロードは1回で済み、前の観点で出した判定を踏まえて次の観点を見られる。速度・コスト・精度の3つが同時に改善しました。
もちろん順次評価には観点間の順序依存が入ります ── 前の観点の判定が後続の評価に影響しうる、というトレードオフ。これは認識した上で許容しました。観点が完全に独立で互いに食い違うレビューを返すよりは、順序依存を許容してでも観点間の整合性を取る方が、9観点を組み合わせたレビューとして実用的だ、という判断です。
教訓は、「並列にすれば速くなる / 品質が上がる」という分散システム的な直感は、AIハーネスでは前提が壊れることがあるということ。手元のCPUコアを並列にする話と違って、AIの場合はコンテキストが「共有メモリ」ではなく「各プロセスの所有物」になります。1つのsessionで連続的に評価したほうが、速度もtoken効率も観点間の整合性も、すべて同時に良くなる ── これは設計のときに見落としやすい構造的な性質です。
この章で言いたいこと
連載で書いてきた最終形は、何度もトライアンドエラーした結果です。最初から正解が見えていて、その通りに作ってきたわけではない。サンクコストを抱えて捨てる判断、自分が選んだメトリクスを目的化させてしまう罠、自然に見える分散構成が逆効果になるパターン ── これらを踏みながら今の形に着地しています。
簡単とは思っていません。でも、ここまでやればちゃんと成果がついてくる、というのが今の実感です。
連載の閉じ方
6本の連載を通じて伝えたかったことは、結局のところ1つだと思っています。
AIコーディングは「使い方」の話ではなく、「使う環境の設計」の話
別の言い方をすると、こうも言えます。
AIは信用するものではなく、設計するもの。
大規模コードベースを前提にすれば、プロンプトエンジニアリング / モデル選び / ツール選定 ── どれも個別には大事ですが、それらを磨くだけでは、PRの自動マージや障害の自動修復や非エンジニア開発までは届きません。届かせるためには、AIが推論しなくて済むコードベース / 業務フロー / 観測 / 修正サイクルを整える必要があり、これは個別のAI技能ではなく環境設計の問題です(逆に、ファイル数十程度の小さなプロジェクトなら、今のAIモデル単体でも十分機能する場面はあります。ハーネスが必須になるのは、1人が全体を頭に入れきれないスケールに達したときです)。
そして環境設計の根っこにある思想は、繰り返しになりますが「AIを信用していない」── 渡されていないコンテキストは知らないし、何も言わなければ理想状態にはならない、という現実を直視することです。この前提を受け入れると、何を作るべきかは自然に決まってきます。
振り返ってみると、ここに至るまでで効いたなと思う判断は4つあります:
- 思想を先に決めた: 「AIを信用していない」のような根っこの言語化が、各機構の優先順位を決めてくれた。手段から入っていたら最終形に辿り着けなかったと思っています
- 捨てる前提で投資した: code-graphに2ヶ月かけて捨てたように、最初に作ったものは捨てる前提で進めていました。サンクコストに引きずられると先に進めない
- 数値目標を単独で立てなかった: Coverage 90%のように、メトリクスは目的化した瞬間に実装を歪めます。他の観点と組み合わせて評価する設計にしました
- AIに推論させないことを設計の中心に置いた: AIの能力を頼るよりも、AIが推論しなくて済む構造を作るほうを優先しました。結果としてそれが安定したシステムに繋がったと感じています
同じようなことを始めようとしている人にとって、何か1つでも参考になれば、と思っています。
あとがき ── エンジニアの仕事はどこに向かうか
ここからは連載総括の本筋から離れて、最近個人的に考えていることを1つ。ポエムなので軽く読み流していただければと。
ハーネスが整っていけばいくほど、エンジニアの仕事はふたつの方向に分かれていくんじゃないか、というのが最近考えていることです。
1つは、課題抽出や業務設計からの価値創出に寄っていく方向。Part 5で書いた非エンジニアPRが成立する世界では、「コードを書く」こと自体は徐々に誰でもできるようになっていくので、価値の源泉は何を作るべきかを定義する力に移ります。業務要件を一番把握している人 ── PMOだったり事業マネージャーだったり、ドメインを深く知るエンジニアだったり ── が、Claude Codeを使って自分でコードまで通せるようになる。この方向に寄っていくエンジニアは、もはや「エンジニア」というよりも、ドメインと実装のあいだを行き来する業務設計者に近い存在になっていく気がしています。
もう1つは、それが安全に、かつ迅速に実行できるようにする基盤づくりに寄っていく方向。非エンジニアが本番リポジトリにPRを出せる世界が成立するのは、その裏でハーネスが品質を担保しているから ── ナレッジグラフ、Auto Review、Self-Healing、再発防止、lint、CI、テスト、観測スタック、それらが噛み合っているから。これを設計・維持・進化させる仕事は、むしろ難度が上がっていきます。家自体を建てる側、レールを敷く側として、深いインフラ理解 / セキュリティ感覚 / 観測設計 / AIのアーキテクチャ的な癖の把握、これらが要求される。
自分はcortexを作っていて、後者の仕事に時間を割いているところはあります。「業務側でやりたいことを、業務側が直接実行できる土台」を作るのが面白い、というのが正直なところ。もっとも、自分自身はどちらかに寄り切るタイプではなくて、業務側の問いに耳を当てる時間と、基盤を組み上げる時間を行き来していて、どっちの手応えも別の意味で面白いと思っています。「どちらが偉い」みたいな話ではなくて、ハーネスがあるからこそ前者が成立し、前者が回るから後者の意味も立つ ── という相互依存の関係だと感じます。
「コードを書く能力」だけを磨いていた時代から、エンジニアのキャリア観そのものが少しずつ変わっていくのかもしれません。どちらの方向で価値を出すのか、あるいは両方を行き来するのか ── これは、これからのエンジニアにとって意識的に選び取るべき問いになっていきそうです。
ここまで6本、お付き合いいただきありがとうございました。
| # | テーマ | キーシーン | 記事 |
|---|---|---|---|
| 1 | 総論:cortexのハーネス | PRが無人マージ / 障害が気づく前に直っている | ai-harness-intro |
| 2 | Product Graph (cpg) | コード・ドキュメント・DB・インフラを1グラフに統合 | cortex-product-graph |
| 3 | AI PRレビュー | webhook → AIレビュー → 自動修正 → squash merge | cortex-auto-review |
| 4 | Self-Healing + Observability + 自動lint追加 | アラート → AI調査 → 修正PR + 新規lint/型gate → 自動再デプロイ | cortex-self-healing |
| 5 | 改修フェーズの民主化 | 業務要件を把握している人が本番に直接PR、ハーネスが品質を担保 | cortex-non-engineer-prs |
| 6 | 連載総括 | 根底にある思想と失敗の振り返り | 本記事 |
comments (15)
The write-time vs read-time inference distinction maps cleanly onto something I keep running into on the content side of AI too. When AI generates a draft, that's write-time inference — it happens once, a human reviews it, corrections get made, it gets frozen into reviewed content. That process is fine and powerful. But then the challenge is the distribution step: getting that content to 15 platforms, in multiple languages, with the right metadata per-platform. If you let AI infer those steps on every publish ("guess what format this platform expects"), you get exactly the problem you describe — unverified inference running on every query. The determinism fix applies there too: structure the platform requirements as explicit facts (not inferred from the platform's vibes), let AI operate over that structured knowledge at publish-time. The harness confines hallucination to where it's acceptable. "Mastering AI is not about giving it freedom — it's about confining its output to a predictable range" — this is going on my wall. The word 'confining' is doing more work than 'prompting' or 'fine-tuning' ever will. The sunk-cost point in the trial section is also underrated. Code-graph was 2 months in and working. Throwing it out anyway because the architectural truth pointed the other direction is the kind of decision that separates harness architects from prompt engineers.
The content-distribution mapping caught my eye—it's the exact same failure mode playing out in a completely different domain. The "harness architects vs prompt engineers" distinction is sharper than what I had in the post: the real line isn't about optimizing a prompt; it's about changing what we allow the model to handle in the first place. The decision to scrap the code-graph wasn't about tweaking the prompts to be smarter. It was facing the reality that we were asking the model to infer something that should have been managed by a deterministic architecture. Overcoming that sunk-cost fallacy is painful, but it's what forces you to look at the system, not the prompt. Glad "confining" landed. That word does the heavy lifting precisely because prompting and fine-tuning only try to influence the model's behavior, whereas a harness actually shapes the boundaries around it.
"Shapes the boundaries around it" vs "influences the behavior inside it" — that's a genuinely useful distinction for explaining to non-engineers why prompt engineering has a ceiling. The harness argument becomes: some failure modes need architectural answers, not better wording. The content-distribution parallel actually runs deeper than I initially framed it — every platform API has its own schema, rate limits, metadata requirements. If you let the system infer those at publish-time, you get exactly the silent variance you described: it works until it doesn't, and the failure is invisible until the content is already gone to the wrong place. The harness answer is the same: structure what can be structured, let inference operate only inside that. Thanks for the series — it's one of the cleaner end-to-end AI architecture write-ups I've read.
"Some failure modes need architectural answers, not better wording" is the line. And "structure what can be structured, let inference operate only inside that" says the principle in fewer words than I managed. Honestly, that closer means a lot. Six posts was a long stretch, and responses like this are what make it worth writing. Thanks for the read, and for the framing.
That really means a lot — six posts is a serious commitment, and the consistency of thinking across all of them showed. "Structure what can be structured, let inference operate only inside that" is exactly the kind of principle that travels well. It'll stick. Looking forward to whatever you write next.
big repos are the real test. stuffing context just creates noise, the model stops actually understanding and starts pattern matching. treating retrieval as a system design problem is the right call.
Right — and that's exactly why pushing the inference to write-time matters. If the model is asked to reason about everything live, it's the noise that breaks it down into pattern matching. But if you let AI generate annotations, structure, dependency edges, etc. at write-time, review them, and freeze them as deterministic context, the live agent never has to handle the noisy "raw repo" — it operates over the curated artifact instead. Retrieval as a design problem solves the noise problem upstream, before any reasoning happens.
This is a strong articulation of the boundary I keep seeing in production AI systems: do not ask the model to rediscover facts the system can make explicit. The write-time vs read-time inference distinction is especially useful. Let AI help generate annotations, graph edges, review dimensions, or policy descriptions, but freeze and review those artifacts before they become runtime facts. Then the live agent is operating over inspected structure instead of re-inferring the world on every request. That also makes failures easier to test: graph wrong, retrieval path wrong, review dimension wrong, or generated conclusion wrong are very different fixes.
Right — and that last point (failures separable by class) is one of the most underrated benefits of the write-time/read-time split. Once inference is frozen at write-time, "the graph is wrong" and "the retrieval missed" and "the live agent reasoned badly" stop being one fuzzy bucket called "the AI got it wrong" and become four distinct categories with four distinct fixes. That distinction is what makes the system testable at all. Without the split, every failure is some opaque mixture of "context was off" and "model was off" with no clean way to bisect.
Exactly. Once the failure classes are separable, the system can stop treating every miss as a mysterious model-quality problem. That separation also changes how I’d build the regression set. I’d want fixtures for graph construction errors, retrieval/path errors, review-dimension errors, schema/format errors, and final-generation errors. Then a model or prompt change is not just “better/worse”; it shows which layer improved or regressed. That is the part I like about the write-time/read-time split: it makes the harness itself testable.
Right — and "which layer improved or regressed" is the metric that suddenly becomes meaningful once the layers are separated. Without that, "the new model is X% better" is a black-box claim that nobody can reproduce or trust. With layer-level fixtures, a model bump that improves final generation by 10% but degrades retrieval by 3% is something you can actually catch and reason about. The harness becomes testable because each layer has a tractable contract; the whole "AI quality" problem stops being one monolithic thing.
"Build rails first" hit different. Ten years in test automation and I never saw it as laying runway for AI until now🤣
Glad it landed 🤣 Ten years of test automation is exactly the kind of foundation work AI ends up depending on. The deep reason: a thick set of existing tests is what lets AI know deterministically what counts as correct behavior. Without it, "did I break something?" is a question AI can only answer by inference — with the tests, it's a question with a deterministic answer. The rails were always there; the framing changes when AI shows up to run on them.
"Tests as determinism boundaries for AI" — that's the framing I was missing. Gonna steal that for the next post. 🤝
Steal away 🤝