みなさまこんにちは!エアークローゼットでCTOをしている辻です。
前編で、46リポジトリに跨る本番システムのコードベースを静的解析で1つのナレッジグラフに統合した話を書きました。 完成はしたものの、 最後に残った課題4つを挙げ、 そのうち特に改善したかったのが 「セマンティック検索ができない (入口問題)」 だと書きました。
graphができても、 そこに辿り着くための入口がgrepしかないなら、 結局AIは推論せざるを得ない。 「事実として渡す」 という本来の目的が成立しません。
今回はこの入口問題をどう解いたか、 という話です。
ヒントはdb-graphにあった
実は、 同じ構造の問題を、 数ヶ月前に別の領域で解いていました。 db-graphの話です。
社内には複数サービスにまたがる大量のDBテーブルがあり、 「どのテーブルがどの業務に使われているか」 を正確にすべて把握できている人はほとんどいない状態でした。 知識の広さも深さも人によってまちまちで、 全体像が誰の頭の中にも収まらない構造です。 そこで、 ORM定義から静的解析でスキーマを抽出し、 Geminiでテーブル説明文を自動生成、 768次元のベクトルにしてgraphに格納、 自然言語クエリで意味検索できるようにしたのがdb-graphです。
記事を書いた時点では991テーブルでしたが、 今は 21スキーマ / 1,133テーブル / 10,815カラム にまで広がっていて、 「テーブル名を知らなくても自然言語で目的のデータに辿り着ける」 が日常的に成立しています。
ここで証明できたパターンが、
静的解析グラフ + AIで生成したコンテキスト注入 = 自然言語で意味検索が成立する
というものです。
同じパターンをcode-graphにも持ち込みたい
db-graphで効いたなら、 code-graphでも効くはず。 そう考えたときに気付いたことがあります。
code-graphの中には、 すでに「DBテーブルノード」 が境界ノードとして存在しているということです(前編で書いた境界ノードの1つ)。
つまり、 code-graphとdb-graphを 接合するだけで、 code-graphが自動的にDBの意味コンテキストを持つようになる。 annotationを1つも振らずに、 既存資産だけでgraphが一段意味豊かになる、 ということです。
「graphを繋ぐ」 という発想が、 ここで初めて出てきました。 個別のgraphで閉じない、 graph同士を接合していく設計へ。
ただしAPI / Event / Page の意味付けは別途必要 ── 全関数にannotationを振るのは無理
db-graphの接合でDBコンテキストは入りました。 ただ、 残りの境界 (API / Event) と、 graph の起点になる Page には別途意味付けが必要です。 これらは静的解析だけでは意味を拾えないので、 何らかの形でコンテキストを注入する必要があります。
選択肢は明快でした。 annotationでコードに直接書き込むしかない(連載Part 2で書いたcortex内部のナレッジグラフと同じアプローチ)。
ただ、 そのまま46リポジトリの全関数に振るのは無理です。 何万関数あるか分かりません。 既存組織で、 既存チームが回している本番コードに、 後から全関数annotationを要求するのは現実的じゃない。
ところがここでもう一つ気付いたことがあって、
重要なのは境界ノードだけ。 だから境界周辺だけannotationを振れば十分意味を持つ。
ということです。
AIが「このコードを変えたら何が壊れるか」 「このAPIは他のどのリポから叩かれているか」 を知りたいとき、 必要なのは関数の中身のロジック説明ではなく、 境界の意図 (= この画面は何のためか、 このAPIは何を返すのか、 このEventは何の節目を表すか)です。
= 最小限のannotationで最大の意味を得る。 これがこの後の設計の核心になりました。
annotation graph の設計
整理するとこうなります(annotation graph は内部では service-product-graph、 略してSPGと呼んでいます)。
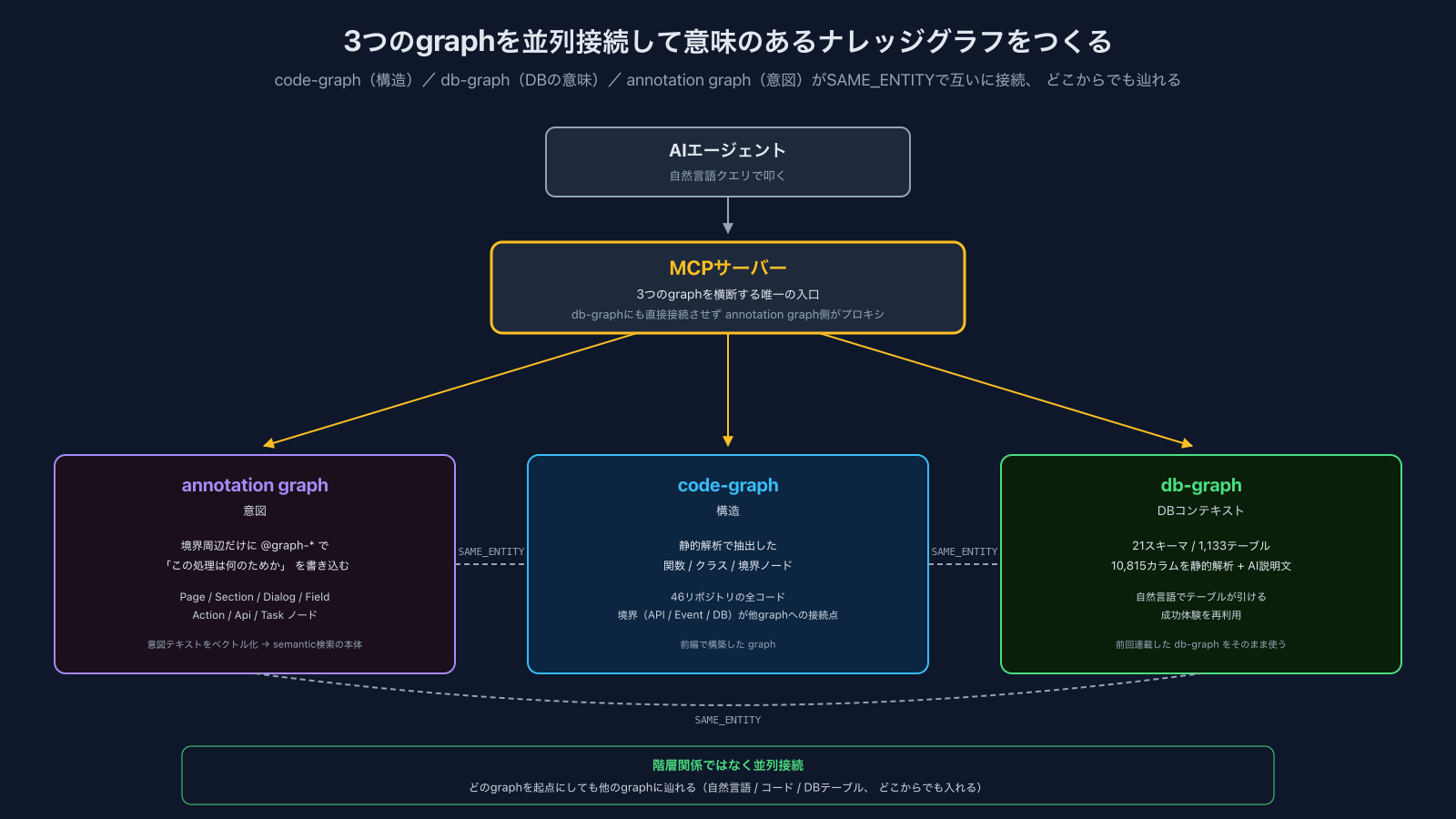
3つのgraphが並列に存在して、 互いに SAME_ENTITY で接続されている構造です。 階層関係ではなく、 どのgraphを起点にしても他のgraphまで辿れる形になっています。
- code-graph(構造) ── 静的解析で抽出した関数 / クラス / 境界ノード(46リポジトリ)
- db-graph(DBコンテキスト) ── 1,133テーブルの意味付き
- annotation graph(意図) ── 境界周辺だけに
@graph-*で振った意図
そしてAIエージェントが叩く入口に MCPサーバー が立っていて、 3つのgraphを横断する形で動きます。 db-graphには直接接続させず、 annotation graph側のMCPがプロキシとして db-graph も呼び出す構造にしています。
annotation graph のノード種は Page / Section / Dialog / Field / Action / Api / Task の7種。 元々は画面中心の設計で screen-graph と呼んでいましたが、 backendのApi / Taskまで広げた段階で名前を service-product-graph に変えました。
annotationの実例
具体的にはこんなふうに書きます(架空例ですが、 形式は本物に近いものです):
/**
* @graph-page /home
* @graph-business メイン画面。 会員が現在借りているアイテムの確認、 購入、 返却ができる
* @graph-label ホーム画面
* @graph-has-section banners, wearing-items, wearing-return, delivery-status
* @graph-has-dialog buying-modal, return-modal
* @graph-navigates-to /return-procedure, /checkout, /my-karte
* @graph-calls GET /api/v1/wearing
* @graph-reads admin_delivery_orders, admin_rental_items
* @graph-flow styling-loop
* @graph-status monthly-member
*/ポイントになるのは2つです。
@graph-businessが日本語の意図テキスト。 これがそのままベクトル化されて、 セマンティック検索の本体になります@graph-flow/@graph-statusが会員ライフサイクル(無料登録 → 月額登録 → スタイリングループ → 解約等)と会員区分。 「この画面は月額会員のスタイリングループの中で出てくる」 という横軸の意味を載せる
これに加えて、 テストケースを導出する根源になる @graph-case(条件分岐パターン)もありますが、 そのあたりは別の機会に。
annotationを「現場の開発フローに干渉せずに」 回す運用設計
ここからが実用性の核心です。
annotation graph を作ると決めたあとに直面する制約はこうでした:
- 現場エンジニアは通常のプロダクト開発 + 人レビューで回している
- 全リポジトリにAIレビューがまだ浸透しているわけじゃない(cortex内部の全自動レビューは 連載Part 6 で書いた通り、 cortexモノレポの中だけで成立している話)
- annotationのレビューを人がやるのは負担
- 「通常コードレビューを人、 annotationレビューをAI」 という分業も、 1 PRに2系統のレビューを混ぜることになって現場の混乱を招く
つまり、 「人とAIを同じPR内で混在させない」 ことが必要でした。
解決策はannotationを物理的に別ブランチに分離する設計です。
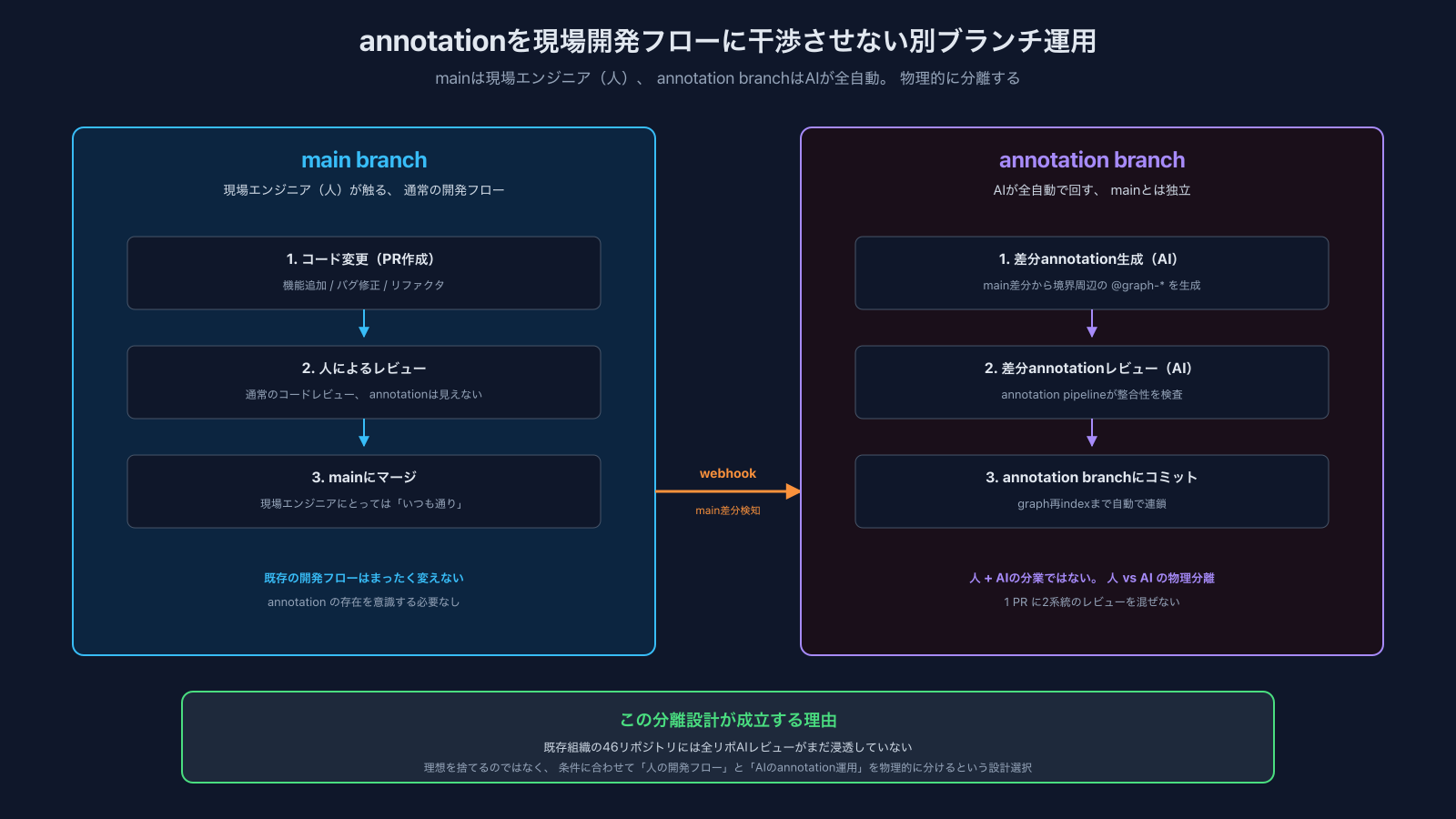
- mainのコードはそのまま、 現場エンジニアの開発フローには一切触れない
- annotationを付与した別ブランチを建てて、 そこをAI専用領域にする
- mainが変わるとwebhookで検知
- 差分annotationの生成と差分annotationのレビューは、 annotation branch側でAIが全自動で回す
- 現場エンジニアにとっては、 自分はmainを触っているだけで、 annotationの存在を意識する必要すらない
これは 連載Part 6 で書いた「AIに全コードを通すゲート設計」 の理想を、 既存組織の現実条件に合わせて分離設計したものです。 cortex(社内AIプラットフォーム)は自分が1から組み立てているモノレポなので「全コード必ずAIゲート通過」 が成立しますが、 46リポジトリの本番系では成立しない。 だから理想を諦めるのではなく、 「人の開発フロー」 と「AIのannotation運用」 を物理的に分けて両方とも回す、 という選択をしました。
3 graph間の整合性をSLOで守る
annotation運用が回るだけでは、 3つのgraph(code-graph / db-graph / annotation graph)の 接合の質 は保証されません。 そこで、 graph全体の整合性を機械的に検査するSLOを定義しています。
主要なルールはこうなっています:
- APIチェーンの繋がり ──
HANDLES_APIハンドラの 95% 以上 が下流の関数呼び出しを持つこと(= APIを受けて何もしないハンドラが残っていないか) - DBアクセスの完全性 ── DB読み書きエッジの 80% 以上 が db-graph側のカラムノードと接合されていること(= code-graphのDB境界がdb-graphの意味と繋がっているか)
- Eventフィールドの解決 ── Eventエッジの 70% 以上 がフィールド情報まで持つこと
- 曖昧マッチの撲滅 ── 名前解決の曖昧なエッジは 0件 (severity: error)
これらは要するに、 「お互いに境界が繋がってなかったらおかしいよね?」 という素朴な問いをSLOに落としたものです。 閾値を下回ったらアラートが上がり、 graph全体の信頼度を毎日守ります。
前編で書いた境界分析cron(接続率5%劣化アラート)はcode-graph単独の話でしたが、 こちらは 3 graphを横断したSLO で、 graph同士の接合まで守りに行く仕組みです。 1リポにparserを追加した、 annotationを書き足した、 schemaが変わった ── 何が起きても、 翌朝には接合の品質劣化が見える状態になります。
静的解析グラフとannotationグラフをSAME_ENTITYブリッジで接合
ここまで「接合」 と書いてきましたが、 実際の接合はそれほど素直ではありませんでした。
静的解析で抽出したAPI / Page / Taskノードと、 annotation graph で書いたAPI / Page / Taskノードは、 別物のノードとして作られます。 同じ意味を持っているはずなのに、 名前 / パス / 識別子の表現が違うので機械的には繋がらない。
これを接合するために、 SAME_ENTITY という別のエッジを生成しています。 3 種類のブリッジ:
- APIブリッジ ── APIパスの正規化を4段階のフォールバックで処理
- リポ別の prefix 変換(コンソール系の
/console/api/を/api/に揃える等) - バージョン除去(
/v1.x/→/) - パラメータ正規化(
/:id,/{id}を/:dynamicに統一) - 完全一致 → 末尾
?差吸収 →:dynamic?末尾除去 → 境界:dynamicの動的dispatch fallback、 と段階的に緩める
- リポ別の prefix 変換(コンソール系の
- Pageブリッジ ── 6つの戦略を優先順位付きで適用(url直マッチ、 componentパス、 itemId、 PascalCase化マッチ、 親ディレクトリ紐付け、 境界の動的部分stripして親URLと突合)
- Taskブリッジ ── リポ別の8パターン
それから運用上の落とし穴も一つありました。 初期実装は INSERT NOT EXISTS で重複を避けていたつもりだったのですが、 BigQuery streaming buffer の反映遅延で重複挿入が起きて、 あるリポではエッジが106 → 214と倍増しました。 これは MERGE INTO に書き換えて冪等化することで解決しています。
結果: 「会員のサブスク料金計算」 でgraphに入れる
ここまで作ったあと、 前編の最後に書いた入口問題が解けました。
「会員のサブスク料金計算が間違っているらしい」
これを自然言語のまま annotation graph に投げると、 ベクトル検索で関連ノード(Page / Api / Function / DBテーブル)が事実として返ります。 そこから SAME_ENTITY 経由で code-graph の関数に渡り、 関連する別リポの呼び出し元 / 呼び出し先まで辿れる。 さらに code-graph のDB境界から db-graph に渡れば、 関連カラムまで取れる。
もちろん起点はどこでも良くて、 「テーブル名から逆引きしたい」 なら db-graph 起点、 「この関数の影響を見たい」 なら code-graph 起点で同じネットワークを辿れます。 1つの自然言語クエリでも、 特定のノード起点でも、 3つのgraphを横断して関連する全コード + 全DBスキーマ が取れる状態になりました。
前編で書いた 「graphはあるのに、 入口が見つからない」 が、 ようやく解消した瞬間です。
上位フロントドアとしてのMCP
この3 graph横断の入口がMCPサーバーです。 サービス検索 / サービス詳細 / API詳細 / データフロー追跡 / 影響範囲追跡 / ビジネスルール全文検索、 という6つのツールを持っていて、 AIエージェントが叩く唯一のエントリーポイントになっています。
特に注目すべきは、 db-graphには直接接続させない設計にしていることです。 annotation graph 側のMCPがプロキシとして db-graph を呼び出す形にして、 AIエージェントからは「1つのMCPに聞くだけで全部出てくる」 状態を維持しています。
これで「画面 → API → コード → DB → カラム」 のフルチェーン辿りが1つのMCPツールで完結する構造になりました。
4-5月の試行錯誤タイムライン
前編で1-3月のcommitを引いたのと同じ手法で、 後編は4-5月の主要commitを並べます。
4月: 拡張とブリッジ初期版
- 2026-04-14 ─
refactor(graph): rename screen-graph to service-product-graph── 画面中心からサービス全体まで広げる宣言 - 2026-04-15 ─
feat(graph): add Api and Task node types to service-product-graph parser── Api / Taskノード追加 - 2026-04-15 ─
feat(mcp): add cross-graph tools to service-product-graph MCP── 3 graph横断ツール導入(上位フロントドアの成立) - 2026-04-15 ─
feat(graph): add SAME_ENTITY bridge edges between service-product-graph and code-graph── ブリッジ初期版 - 2026-04-18 ─
feat(graph): resolve Redis keys to code-graph boundary nodes── Redis経由の境界解決 - 2026-04-19 ─
feat(service-product-graph): add EventBridge EMITS_TO support + SAME_ENTITY bridge - 2026-04-20 ─
feat(code-graph, service-product-graph): improve SAME_ENTITY boundary bridge coverage── 4段階fallback確立 - 2026-04-21 ─
feat(auto-review): SPG annotation auto-maintenance pipeline── AI自動メンテパイプライン(= 前編で予告した「人だけじゃ無理、 AIならできる」 の正体) - 2026-04-22 ─
feat(service-product-graph): add Task SAME_ENTITY bridge to code-graph── 3ブリッジ揃う
5月: 安定化と拡張
- 2026-05-01 ─ annotation生成を手元実行からCloud Run Jobに移管、 運用を安定化
- 2026-05-05 ─
feat(spg): add mall repos to SPG indexing── mall系のリポ取り込み - 2026-05-06 ─
feat(spg): add Go-aware parser── Go対応 - 2026-05-06〜08 ─ Pageブリッジの戦略を6つまで拡張、 接続率100%達成
このタイムラインから見える話
4月15日に「拡張 + 横断ツール + ブリッジ」 がほぼ同時に入って、 そこから1週間で「Redis / EventBridge / Task ブリッジ / annotation自動メンテ」 と週単位で機能を積み上げていったのが分かります。
特に 4月21日のannotation自動メンテパイプラインが、 前編で残した「人だけじゃ無理、 AIならできる」 の宿題を実装で回収した瞬間でした。 ここから先は、 annotationを「人が頑張って書く」 から「AIが書く前提で運用設計する」 にステージが変わりました。
まだ解けていない課題
ここまでで入口問題は解けましたが、 もちろん全部が綺麗になったわけではありません。
1. annotationカバレッジの維持
frontend側は手厚く振られていますが、 backend / Go / batch系はまだ薄めです。 「振られていないノード」 が存在する構造は、 ゼロにはできません。 これは継続的な運用課題です。
2. ブリッジの誤接合の完全排除は構造的に未達
特にPageブリッジは、 1つの境界に対して複数のannotation Pageが紐付くケースが構造的に避けられません。 戦略を増やすことでカバレッジは100%に持っていけましたが、 「正しく繋がっている」 を100%保証するのは難しい。
3. 動的解析の不在
graphに乗っているのは「edgeが静的に存在する」 という事実だけで、 「実際にそのedgeが本番でどれくらい使われているか」 は分かりません。 静的解析グラフに本番実行回数を流し込んで、 dead-code edges を別シグナルとして可視化する ── ここはまだ手をつけられていません。
4. 新リポ追加時の調整負荷
新しいリポジトリが本番系に加わるたびに、 ブリッジの正規化ルールやリポ別パターンの調整が必要です。 前編4番目に書いた「新しい境界パターンが出るたびに独自parserを足す運用負荷」 の、 annotation graph 側の同型課題です。
おわりに ── 「捨てた」 のではなく「進化させた」
前編の冒頭で、 cortex(社内AIプラットフォーム)を作り始めた頃に「2ヶ月で捨てた」 と書いたcode-graphの話を扱いました。 でもこの連載を通して振り返ると、 正確には「捨てた」 のではなく 「進化させた」 が正しい表現でした。
進化の正体は、 結局3つのgraphの並列接続に集約されます:
- code-graph(構造)
- db-graph(DBコンテキスト)
- annotation graph(境界の意図)
これらを SAME_ENTITY で互いに接続して、 MCPで AI に渡す。 静的解析だけでは届かなかった「意味で引く」 を、 db-graphの成功体験を再利用 + 境界周辺だけannotationを振る最小限戦略で成立させた、 という話でした。
そしてもう一つ、 連載 AIハーネス(Part 1-6) との対比で言うと、 こうも整理できます:
- AIハーネス連載 ── 自分が1から組み立てる側で、 どうAIと付き合うか
- code-graph-deep-dive 連載(前編 + 後編) ── 既存組織の本番系で、 どうAIと付き合うか
= 同じ思想(AIを信頼せず設計する)の、 異なる条件下での実装でした。
長文をお読みいただきありがとうございました。
comments (0)
まだコメントはありません。