みなさまこんにちは!エアークローゼットでCTOをしている辻です。
設計編では、アプリケーション / インフラ / CI / LLMの4軸を、それぞれの問いの性質に合わせて別々の形でObservableにする話を書きました。ここまでで観測スタックの書き込み側は一旦区切ったところです。
ただし、「Observableにしただけ」で話は終わりません。観測スタックには本番データが流れる以上、ここにPIIが混入する経路を断たないといけない ── これはAIとは無関係に、observability設計で手を抜くと漏洩事故に直結する古典的な問題です。
さらにAIを前提にすると、このリスクの重みが一段上がります。従来はログ検索といえばSREや一部の開発者だけがやるもので、仮にログにPIIが混じっていても検索する人の母集団が限定的だった。でもMCP経由でAIエージェントが横断的にログを引く前提だと、検索する主体の幅も頻度も一気に広がる。PII対応ができていないと、これまで「たまたま事故が起きていなかった」で済んでいた構造的リスクが一気に顕在化します。
そしてその上でAIが観測スタックを引ける状態を保たないと、そもそも「AIに渡せるobservability」という前編の目標が成立しません。
実践編ではこの2つの両立 ── PIIを守りつつ、AIから検索できる── をどう実現したか、そしてその結果としてCI失敗からPR提案まで繋ぐ自動修復がどう成立したかを書きます。
観測スタックはPIIの通り道になりやすい
アプリケーションがログを出す → Lokiに流れる → AIがMCP経由で引く ── この素直な流れを組んだだけだと、そこに以下のようなものが混入してきます:
- お客様のemailや電話番号がエラーログに含まれる
- 注文情報のレスポンスがtraceのpayloadに乗る
- DBクエリログにテーブル全行が出る
平文PIIが観測スタックに溜まると、そのままAIから検索可能になります。これはAIの能力以前の話で、観測スタックがPIIの通り道になっていること自体がリスク。そして同時に、PIIを完全に消してしまうと**「お客様Aの問い合わせを調査したい」という当然のサポート業務ができなくなる**。
cortex(社内AIプラットフォーム)では、この対立をどう解いたか。大事なのは**「PIIの通り道を断つ」と「PIIで検索できる」を二者択一にしない**設計です。
多層PII設計 ── 6つの層で守る
cortexのPII対応は、役割の違う6つの層が組み合わさっています:
| 層 | 目的 | 仕組み |
|---|---|---|
| 書き込み: BQ Policy Tag | 列レベルのアクセス制御 | pii_high / pii_medium / pii_low の3層分類。fine-grained readerを持たない権限から該当列にSELECTすると Access Denied でクエリ自体が弾かれる(純粋なCLS、動的マスキングは使っていない) |
| 書き込み: ETL DLP | 平文PIIを派生テーブルに残さない | Cloud DLPでカスタマーサポートデータ等を変換時にredact。[EMAIL_ADDRESS] / [PHONE_NUMBER] のplaceholderで構造は残す |
| 書き込み | Lokiに平文を残さない | アプリケーション側で hashEmail (HMAC-SHA256で12-char prefix、鍵は観測スタック外)を通してからlog出力 |
| 検索 | 平文を介さず特定顧客のログ抽出 | クエリ側も同じ hashEmail を通してからLokiに投げる |
| 出力: MCPマスキング | AIに渡る時点で隠す | カラム名検出で ***@***.com などのplaceholderに置換 |
| Identity分離 | 社員emailはPII扱いしない | Edge RouterでHMAC署名された認証emailとしてattributionに使う |
このうち**4つ目の「検索
」**が、セキュリティと使いやすさの両立で一番美味しいパターンです。ハッシュ化を「書き込み」と「検索」の両端で通す
普通に「ログからPIIを消す」と、後で「お客様Aのログを探したい」ができなくなります。でも、書き込み時にハッシュ化した値をログに残しておけば、検索クエリ側でも同じハッシュ関数を通すことで該当ログをヒットさせられる。平文のemailは両端のどこにも流れない。

具体的にはこういう流れになります。
書き込み側:
// アプリケーションコード
logger.info("Subscription updated", {
user: hashEmail(user.email), // → '7a3f9c2e0b1d' (HMAC-SHA256 12-char prefix)
plan: "monthly",
});
// → LokiにはhashEmailの結果しか残らない検索側(特定顧客のログを抽出したいとき):
検索ツールの入口に同じ hashEmail を仕込んでおきます。ここを通したあとはハッシュ済みの値だけがLokiに渡る、という形:
// 検索ツールの入口でhash化してからLokiに投げる
const hash = hashEmail(input);
// → '7a3f9c2e0b1d'
const logs = await loki.query(`{app="subscription"} |~ "${hash}"`);
// → 該当のhashが含まれるログを返す両端で同じ hashEmail 関数を通すので、同じ顧客から出たログは同じhashでヒットする。一方で:
- Lokiに平文のemailは一度も入らない
- 検索クエリのLokiに届く文字列にも平文emailは含まれない(ハッシュ化後の値だけが届く)
- ログ漏洩時の列挙耐性はHMACの鍵を観測スタック外に置くことで担保。emailは入力空間が狭く列挙可能なので、単方向ハッシュだけだと候補emailを順方向ハッシュして突合される。HMAC化して、鍵を書き込み側 / 検索ツール側の2箇所だけに置けば、ログだけ漏れても鍵がなければ突合できない
これはハッシュ関数の「同じ入力には同じハッシュ値が返る」という性質を、「両端で同じロジックを通せば検索が成立する」という形で再利用したものです。セキュリティとデバッグ利便性のトレードオフをぐっと圧縮できる。
そして当然ですが、この仕組みは「アプリログ層」だけの話で、BQ側はまた別のPolicy Tagによる列レベルアクセス制御で守られている(上の表の1〜2行目)、という多層構造になっています。
なお検索ツール(MCPサーバー含む)の入力引数は、受け取った瞬間だけ平文を持ちます。ツール側で即座に hashEmail を通すので、LokiにもMCP tool-callログにも平文は残らない、というのが運用上の前提です。検索ツールの引数取り扱いも「多層PII設計」の一部に含まれている、ということ。
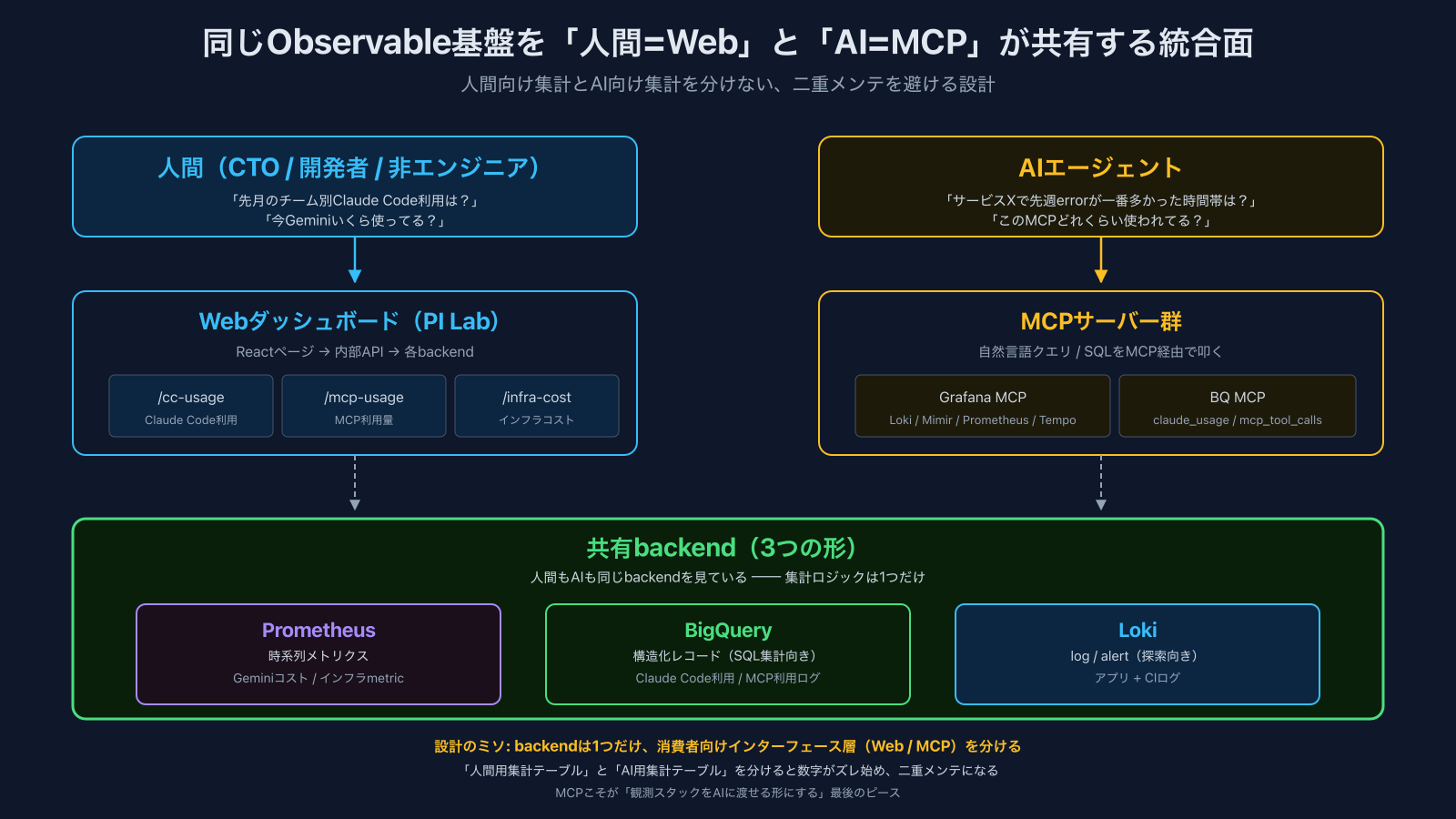
統合面 ── 「人間 = Web、AI = MCP」で同じ裏側を共有する
3つの形でObservableにして、PIIもちゃんと守る形にした。次の問題は、誰がどう引くか。ここでよくある罠は、「人間向けのダッシュボード集計」と「AI向けのデータ提供」を別々に作ってしまうことです。そうすると:
- 同じ問いに対して2つの集計実装を抱える
- 数字が微妙にずれ始める
- どっちが正なのか分からなくなる
- AI用の集計の更新と人間用の集計の更新が非同期になる
cortexはここを**「同じObservable基盤を共有して、消費者向けインターフェースだけ分ける」**という設計にしています。
人間側: AI運用ポータル
社内向けにAI運用ポータル (内部呼称: PI Lab)があり、ここに観測対象別のダッシュボードが集約されています:
- Claude Code利用量 (設計編で見せたcc-usage画面)
- MCPツール利用量 (server別 / tool別 / user別 / team別)
- インフラコスト (Gemini / GCP / AWS / GitHubを1画面で)
- アラート状況、デプロイ履歴、等々
例えばMCP利用ダッシュボードは実物だとこんな感じです:
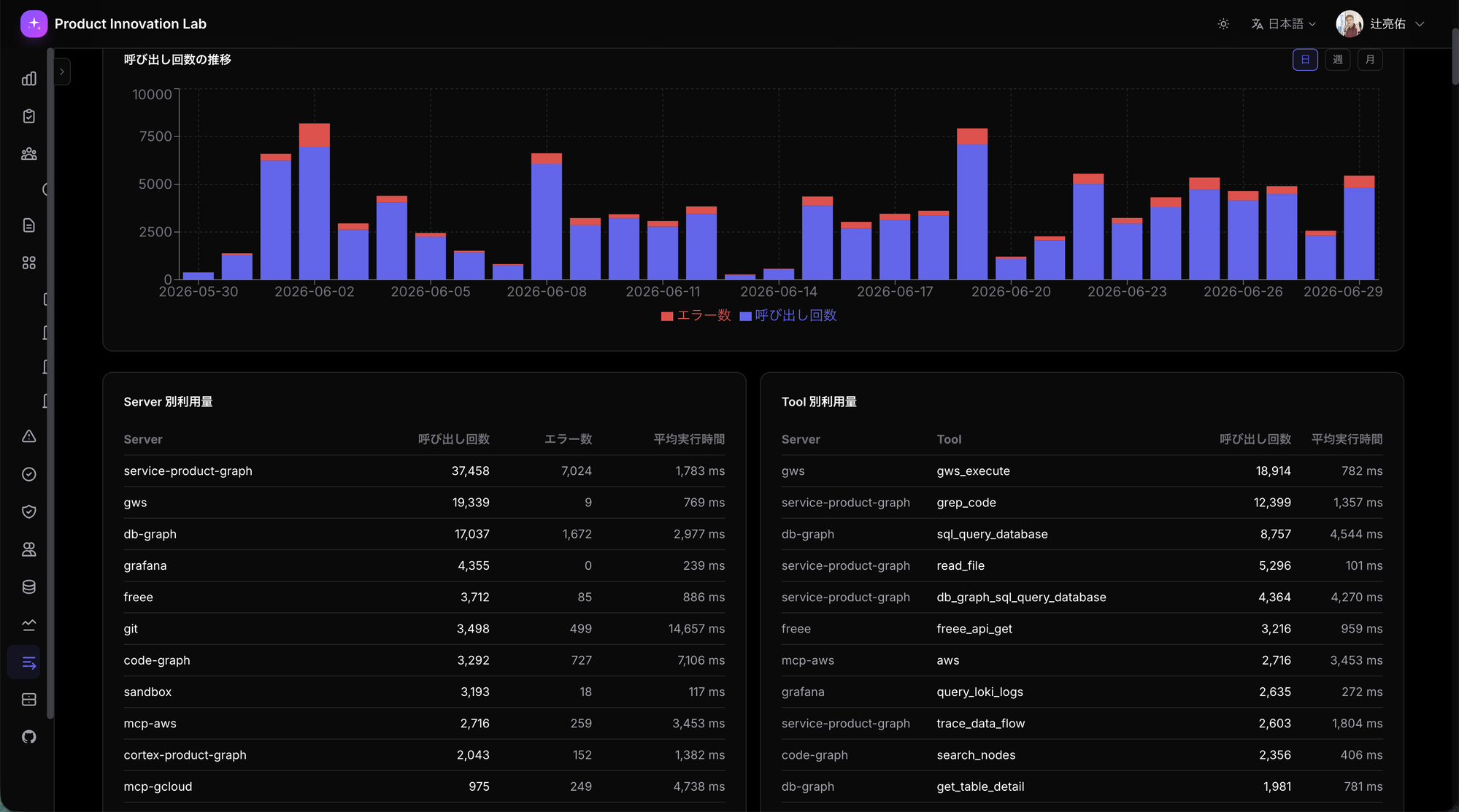
過去30日で service-product-graph が37,458 calls (うちエラー7,024)、gws が19,339 calls、db-graph が17,037 calls ── という形で、どのMCPがどれだけ使われているか、どこで失敗が出てるかが毎日眺められる状態になっています。なおエラー率が高めに見えるserverがあるのは、typed error (= 期待される拒否、例
これらのReact側のページは、内部API経由でBQ / Prometheus / Lokiを引いて表示する構造。集計ロジックはAPI側に集約されています。
AI側: MCP
同じデータソースをAIエージェントが叩く時は、用途別のMCPを経由します:
- Grafana MCP ── Loki / Mimir / Prometheus / Tempoに自然言語クエリで投げる。「先週、サービスXでerrorが一番多かった時間帯は?」のような問いをそのまま投げられる
- BQ MCP (cortex-product-graph経由) ──
claude_usage.claude_usage/cortex.mcp_tool_callsをSQLで引く
ここの設計のミソは、人間ダッシュボードとAI MCPが同じbackendを共有している点です。「AI用の集計テーブル」と「人間用の集計テーブル」を分けない。Observable基盤は1つだけ作って、そこに対する消費者ごとのインターフェース層 (Webダッシュボード / MCP)を別に提供する、という形。
DDDの語彙で言えば、MCPもWebダッシュボードもどちらもプレゼンテーション層であって、同じドメイン(= Observable基盤)に対する別の入出力チャネルに過ぎない、という整理になります。「MCPは何か特別な仕組み」と捉えるより、ただのpresentation layerの一形態として位置付けたほうが、重複実装を避ける判断がブレません。
これがあるからこそ、「観測スタックがAIから見えている」が成立しています。Observable基盤を作っても、**AI向けのプレゼンテーション層(= MCP)**が無ければAIから引けない、という意味で、MCPは「AIに渡す」を成立させる必須ピースです。
自動修復の本当の駆動源
ここまで設計した観測スタックを「単なる見るための画面」で終わらせない層が自動修復です。これはAI Harness連載Part 4で全体は書いたので詳細は省きますが、観測スタック側から見ると、起点と末端は明確です。
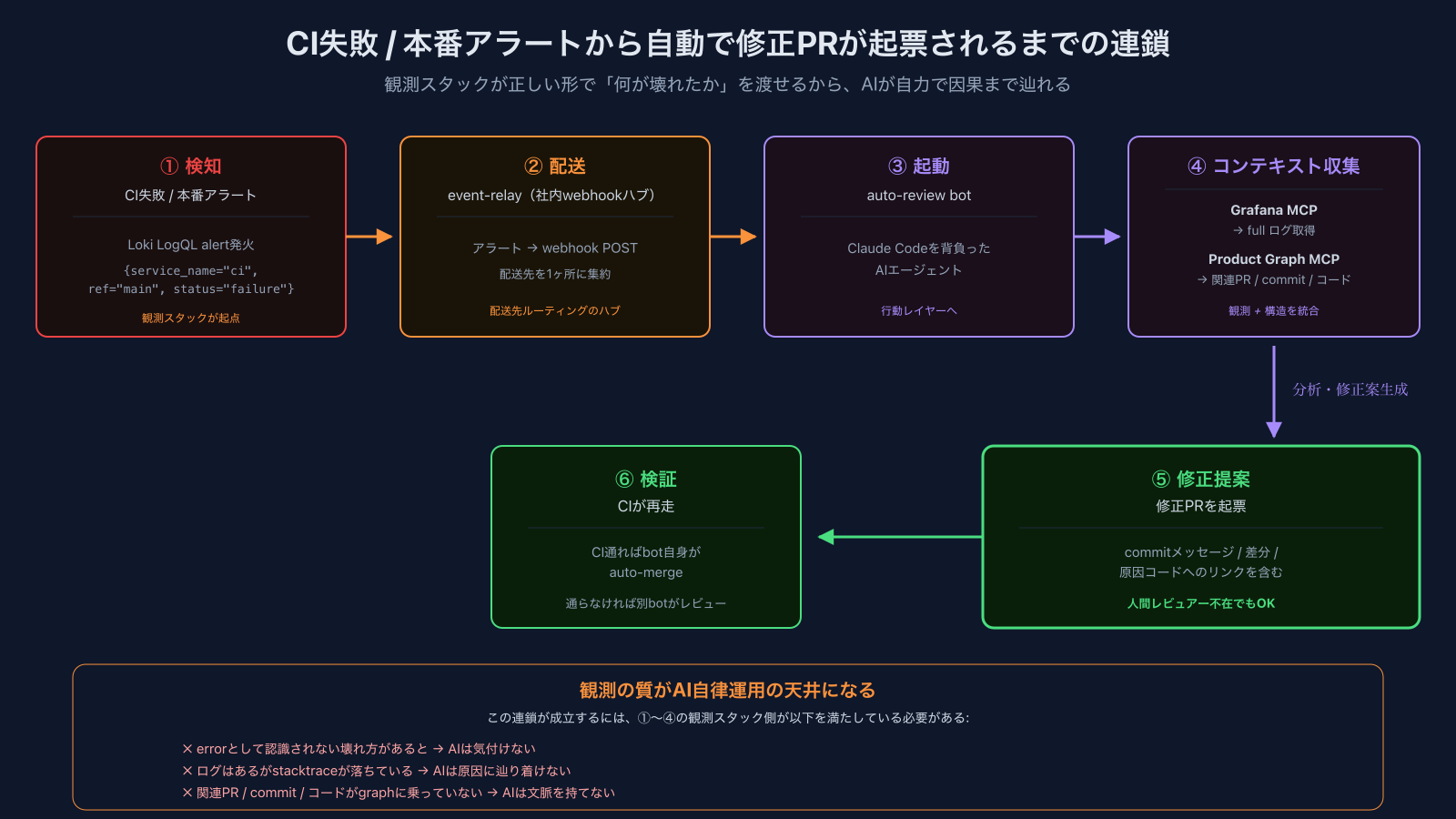
具体的な流れ:
- 検知 / CI失敗がLoki LogQL alertで発火
- 配送: event-relay (社内webhookハブ)にPOST
- 起動: auto-review bot (= Claude Codeを背負ったエージェント)が起動
- コンテキスト収集: botがGrafana MCPでfull logを取得、Product Graph MCPで関連PR / commit / コードを辿る
- 修正提案
- 検証: CIが通ればbot自身がauto-merge、通らなければ別のbotが更にレビュー
つまり自動修復の起点は観測スタックが「何が壊れたか」を正しい形で渡せる状態にあるかどうか、です。errorとして認識される / stacktraceが残っている / 関連コード(PR / commit / graph)に辿れる ── このどれかが欠けていたら、自動修復は止まります(具体的な壊れ方は後述の残課題セクションで掘ります)。別の言い方をすると、
観測の質がAI自律運用の天井になる
これが実践編で一番伝えたい主張です。観測スタックは「監視するための仕組み」ではなく、「AIを動かすための入力」だと位置づけ直すと、設計判断の順位が変わります。
残課題 ── 「何をerrorとして扱うか」とstacktrace設計こそ命
最後に、ここまで作っても残っている一番大きな課題を素直に書きます。
観測スタックをいくらObservableにしても、そもそも何をerrorとして扱うか、そのときstacktraceが残っているかの設計が崩れていると全部無駄になります。これはAI Harness連載Part 2でもcortex内部のナレッジグラフの文脈で触れた話ですが、同じ問題が観測スタック側でも本筋にいます。
具体的にどう崩れるか:
try ~ catchで握り潰してログすら出ない → 観測スタックに何も残らない- catchではログしているが、
console.log相当のinfoレベルで出していて、errorと認識されない - errorとして出しているが、
error.messageだけ書いてstacktraceを出していない → 原因コードに辿り着けない - そもそも非同期エラーがunhandledで落ちている
これらはすべて、観測スタックの問題ではなく、観測の入口を作るコード側の問題です。観測スタックがどれだけ完成度高くても、入口の蛇口が崩れていればそこから何も流れてこない。
現状の対策は3層に分かれていて、どれも完璧ではありません:
- lint(静的検査) ──
no-silent-catchルールが空catchや.catch(() => null)系の握り潰しを禁止。ただし「catch内で何か関数呼び出しさえあれば許容」という構造なので、「logger.info(err.message)でinfoレベルに格落としする」「error.messageだけ拾ってstacktraceは捨てる」のような壊れ方は静的に拾えない - ガイドラインドキュメント ── 「
serializeError(error)を通してstacktraceを構造化フィールドに格納する」「logger.error(err.message)でstackを捨てるのはMajor違反」等は社内guidelinesに明記。ただし静的検査できず、人間 / AIレビュー依存 - AI auto-review ── PRの自動レビューbotはTestカバレッジの観点で「エラーケースをテストしているか」を見るが、observabilityに特化したチェック項目を持たないので、stacktrace設計の質をsystematicには拾えない
つまり**「ガイドラインはある、lintで一部は拾える、AIレビューも一応みる、でも完璧じゃない」**が正直な状態です。本物のギャップは、新規コードが書かれる時点で「ここはerrorとして扱う / stacktraceを残す」をAIが能動的に提案・補完するハーネスが組めていないこと。観測の入口の設計をAIが前のめりに保証してくれる仕掛けまでは整っていません。
「観測スタックは整った、だが観測対象の設計自体は人間が頑張っている」 ── ここが現状の正直な絵です。ここをハーネス化するのが次のステップになります。
閉じ ── 静的編 + 動的編は揃った、ただし合流は次の宿題
code-graph連載で書いた「静的解析グラフをAIから引ける形にする」が、コードの構造を事実として渡す話だったとすると、今回の前後編は本番でいま起きていることを事実として渡す話でした。
| 形 | 何を渡すか | |
|---|---|---|
| 静的編(code-graph + db-graph + annotation graph) | 3グラフ並列接続 + SAME_ENTITY | コードと意味 |
| 動的編(前編 + 本記事) | Prometheus / BQ / Loki + MCP | 本番の挙動とコスト |
ただし正直に書いておくと、この2つは現状ではまだ別々に存在しているだけです。cortexが標榜する「AIには推論させない、事実として渡す」を本当の完成形に持っていくには、静的グラフに動的データを流し込んで一体化するステップが残っています。これはcode-graph連載後編で残課題として挙げた「動的解析の不在」とまったく同じ問題で、「あのedgeが本番でどれくらい使われているか」を静的グラフのノード上に乗せる ── ここまでいって初めて『事実として渡す』が完成形になります。
そしてこの静的編・動的編の上に自動修復が乗ることで「AIが自律的に運用する」までは成立していますが、静的編と動的編の合流は次の連載の宿題です。
最後に、観測スタックそのものより観測対象(=何をerrorとして扱うか、stacktrace残すか)の設計こそ命、という話。ハーネス化の次の宿題はここになります。
長文をお読みいただきありがとうございました。
comments (0)
まだコメントはありません。