みなさまこんにちは!エアークローゼットでCTOをしている辻です。
Part 3では「AIが書いたコードはAIが見る」── 自動レビューパイプラインで PR時点の品質を守る話を書きました。
今回は本番時点の品質を守る側、Self-Healing(自己修復)です。本番アラートをAIが調査して修正PRを起票、自動レビューに乗せて自動マージ、自動再デプロイまで完結させる仕組み。そしてその修正PRには再発防止のlint/型ゲートの追加が必須化されていて、結果としてガードレールが日々自動で増えていく。
「障害が自動で直る」だけだと派手で目を引きますが、たぶんそれだけでは中長期では負ける。直したついでに同じ罠の再発を構造的に潰す ──「自己修復」+「自己強化」の2つが組み合わさって初めて、品質ゲートは時間とともに育っていきます。
いきなり1ヶ月分の数字から
直近30日でマージされたSelf-Healing PR: 115本。
ほぼ全て人の介入なしでmerge + deploy完了。
人の対応は「AIが手を出せないと判断したケースだけ」。
これがcortexの「障害対応」の現状です。
ここで「115件=ユーザー影響のある障害」とは読まないでください。内訳はざっくり:
- 約半数(54本)がDeploy Failed系 ── CI/Pulumiデプロイ段階で失敗を検知し、本番に出る前にAIが消化したもの。ここは最近
[Recurrence]ループ(後述)で対策が積み上がってきていて、体感では減少傾向 - 残り61本が本番ランタイム系(Service Error Log Detected / Pipeline Failure / Generator Failure等)── 本番では走っているが、エラーログ閾値や連続失敗の閾値を超えた段階で発火する型のアラート。ユーザー影響に至る前にAIが消化したもの
つまり「障害対応」というよりは「監視で拾った本番異常を、人が起きる前にAIが115回直した」が正確。実際に人が認知するインシデントは月数件レベルに絞られます。
加えて、同じサービスで繰り返し発火しているケースが目立ちます(あるETL系サービスだけで61件中25件) ── これがまさに後段で書く[Recurrence]ループでlint/型ゲート化して構造的に潰していく対象になる、というのが本記事後半の話です。
もう一つ正直なところを書いておくと、直近1ヶ月の数字はやや上振れしています。元々コードベース内に「エラーをcatchで握り潰して何も通知しない」サイレントcatchが多く存在していて、no-silent-catchのlintルールを追加して既存のsilent catchを順次潰した結果、それまで隠れていた本番障害がアラートとして表に出てきた、という側面があります。「監視が見える化された」分のスパイクなので、[Recurrence]ループで対応+lint化が進めば数字は収束していく見込みです。「見えていなかったものが見えるようになった」のは品質的にむしろ前進で、いま起きているのはそのcatch-upフェーズです。
もう一段補足すると、これを人間が手動で消化することは現実的にできません。115回分の「アラート確認 → ログ調査 → コンテキストスイッチ → コード把握 → 修正 → PR起票 → レビュー → デプロイ」を回したら、開発チームの可処分時間は崩壊します。仕組みが平然と無人で消化し、しかも修正と同時にlint/CI guardへ変換している ── ここが本記事の主題です。
アラートが発火した瞬間にAIが調査を開始、Loki / Product Graph / git blameを辿って根本原因を特定し、修正PRを起票してPart 3の自動レビューに乗せ、APPROVE → 自動マージ → 自動再デプロイで一周まわります。
連載一覧
| # | テーマ | キーシーン | 記事 |
|---|---|---|---|
| 1 | 総論:cortexのハーネス | PRが無人マージ / 障害が気づく前に治っている | ai-harness-intro |
| 2 | Product Graph(cpg) | コード・ドキュメント・DB・インフラを1グラフに統合 | cortex-product-graph |
| 3 | AI PRレビュー | webhook → AIレビュー → 自動修正 → squash merge | cortex-auto-review |
| 4 | Self-Healing + Observability + 自動lint追加 | アラート → AI調査 → 修正PR + 新規lint/型ゲート → 自動再デプロイで同じ書き方を機械的に弾く | 本記事 ←現在地 |
| 5 | 改修フェーズの民主化 | 業務要件を把握している人が本番に直接PR、ハーネスが品質を担保 | cortex-non-engineer-prs |
| 6 | 連載総括・最終章 | 根底にある思想(何を捨てて何を取ったか / なぜこの設計か)と失敗の振り返り | cortex-philosophy |
全体像 ── 「観測」「修復」「強化」の3層
Self-Healingを機能させるには、その手前にちゃんと観測層が必要で、その後ろに強化層(再発防止)が必要です。Self-Healingそのものは真ん中の修復層に位置していて、3層が揃って初めて「自己修復+自己強化」のループが回ります。
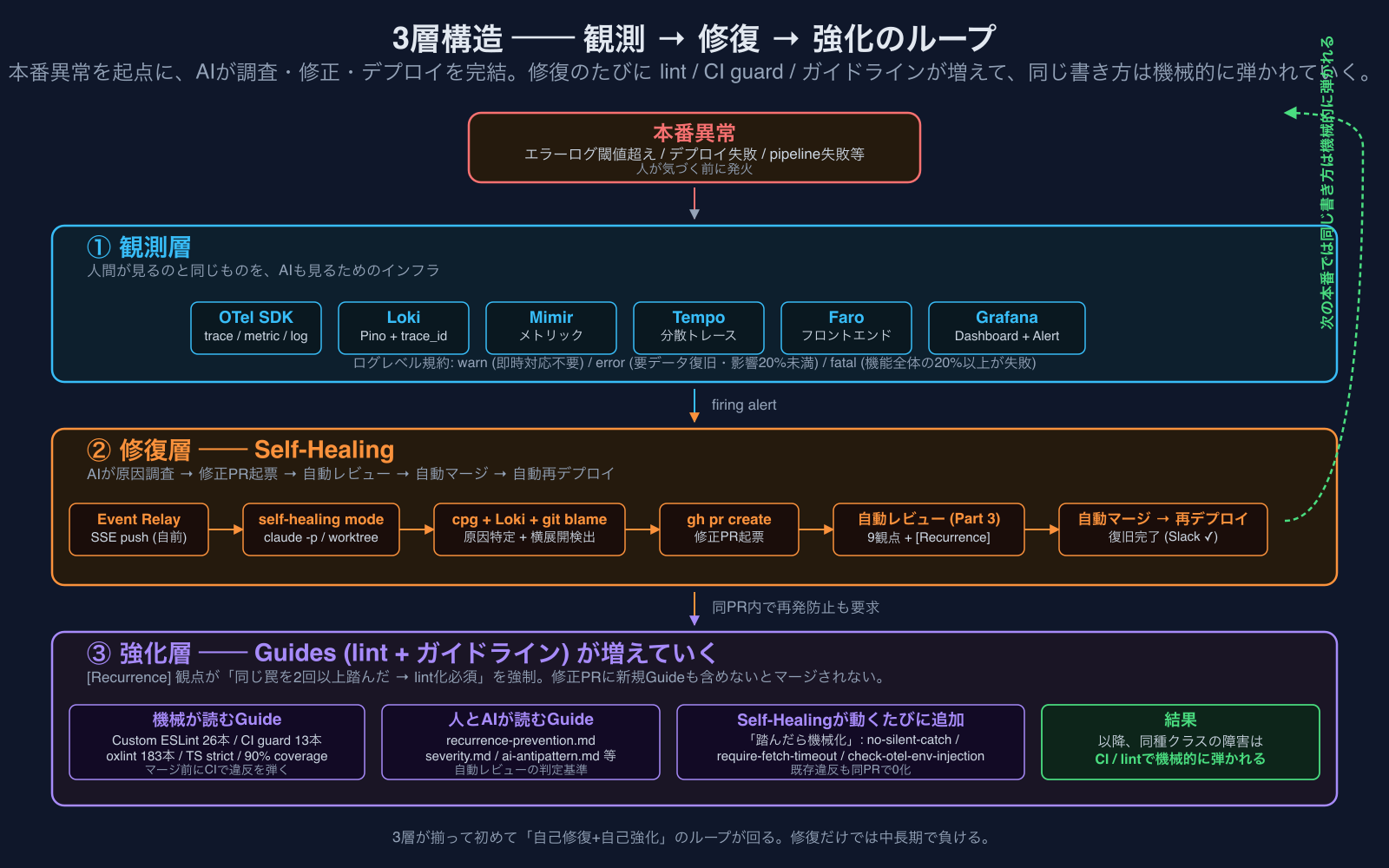
| 層 | 何をするか | 主な構成要素 |
|---|---|---|
| 観測 | 本番の異常をリアルタイムに検知 | OTel SDK / Loki / Mimir / Tempo / Faro / Grafana / Pino logs with trace_id |
| 修復 | アラートをAIが受けて原因調査 → 修正PR起票 → 自動レビュー → 自動マージ → 自動再デプロイ | Event Relay → SSE → self-healingモードスクリプト → claude -p (worktree) → gh pr create |
| 強化 | 修正PRに新規Guide(lint / CI guard / ガイドライン)の追加を必須化、同種アラートが二度と発火しないように構造化 | @cortex/eslint-plugin-graph(26本)、scripts/check-*.ts(13本)、recurrence-prevention.md、自動レビューの[Recurrence]観点 |
順に分解していきます。
観測層 ── アラートはどこから来るか
cortexの本番observabilityはGrafana Cloud + OpenTelemetryで構成されています。
- OTel SDK(
@cortex/otel共通パッケージ)── 各サービスのエントリポイント最初でinitOtel({ serviceName })を呼ぶ。trace / metric / logをOTLPでGrafana Cloudに送る - Loki(ログ)── Pino構造化ログに
trace_idを自動付与。trace ↔ log相互参照可能 - Mimir(メトリック)── Cloud Run / pipeline / Gemini APIトークン使用量等
- Tempo(トレース)── 分散トレーシング
- Faro(フロントエンド)── ブラウザのJSエラー / パフォーマンス / ネットワーク失敗を捕捉
- Grafana ── ダッシュボード + Alert Rules + Notification Policy
加えて、Pinoの構造化ログはログレベルの定義をビジネスインパクト軸で規約化しています:
| レベル | 定義 | 例 |
|---|---|---|
warn |
業務上予見されうる、ただちに問題にならない(リトライで自然回復する想定) | 検索クエリで該当0件、任意フィールド未設定、レート制限による短時間retry |
error |
確実に後からデータ復旧/再実行が必要。影響範囲は20%未満と予想 | あるはずのuserレコードが見つからない、BigQuery insert失敗、個別レコードのenrichment失敗 |
fatal |
その機能全体が20%以上失敗する状態。サービス継続不能・致命的な設定欠如・依存先の全断 | OTel初期化失敗、起動時の必須secret欠如、Pipelineの入力データソース全断 |
ポイントは、NotFoundErrorのような型名や例外クラス名で機械的にレベルを決めないことです。同じ「レコードなし」でも、「絶対に存在すべきレコードが存在しない」ならerror/fatal、「ユーザー検索のヒット0件」ならwarn。「データ補正が要るか」「機能全体が止まるか」のビジネスインパクトでレベルを決める規約で、これが曖昧だと「監視疲労」と「重大障害見逃し」が同時に起きる。Self-Healingが反応するのは主にerrorの閾値超えで、fatalは人手エスカレーション側。
Alert RulesはPulumiで宣言的に管理していて、サービスごとにBOT / Pipeline / Transformer / Generator / Gemini / CI / Deploy / Service Catch-All等のカテゴリでルールをまとめてあります。新サービスを追加するときも、infraコードにルールを1行足せばダッシュボード+アラートが自動で立ち上がる構成です。
ここまでが「人間が見るのと同じものを、AIも見る」ためのインフラ。Self-Healingは、ここで上がったアラートを受け取って動きます。
Observabilityで拾えないものはSelf-Healingも無力
正直に書いておきます。Self-Healingはあくまで観測層が異常として検知できたものにしか反応できません。Observabilityが命、というのはここに直結する話です。
現状cortexの観測スタックで取れているのは、ざっくり「ロジックレベルのエラー」 ── 例外、エラーログ、デプロイ失敗、外部API呼び出しエラー、閾値型メトリック異常 ── が中心です。
逆に、いまの構成では取れていない領域があります:
- UIのエラー ── ロジックは通っていてエラーログも出ないが、画面に意図通り表示されない / 誤った値が表示されるクラスの障害。Faroでクライアント側のJS例外やnetwork failureは拾えるが、「ロジックが通った上で結果が意図と違う」はアラートにならない
- 静かなdata corruption ── 集計値がじわじわずれる、テーブルに不正な値が入る等。閾値やschema違反として現れない限り検知できない
- ユーザー体感の劣化 ── レスポンスが遅い、UXがおかしい等。SLO / レイテンシ閾値を超えて初めて拾える
つまりSelf-Healingは、「観測層が捉えられる障害」をAIに置き換える仕組みであって、観測層自体の網羅性が前提条件です。観測の穴は、自動レビューやSelf-Healingの届かない死角としてそのまま残ります。
これはSelf-Healingの限界というより「観測スタックを育てることの重要性」であり、cortexでも継続的に投資している領域です(Part 1で書いた「支える基盤層」の一つがObservability)。
修復層 ── Self-Healingの流れ
MODE=self-healingで起動したPart 3と同じwebhook-serverスクリプトが、Grafanaのfiring alertを受けて動きます。
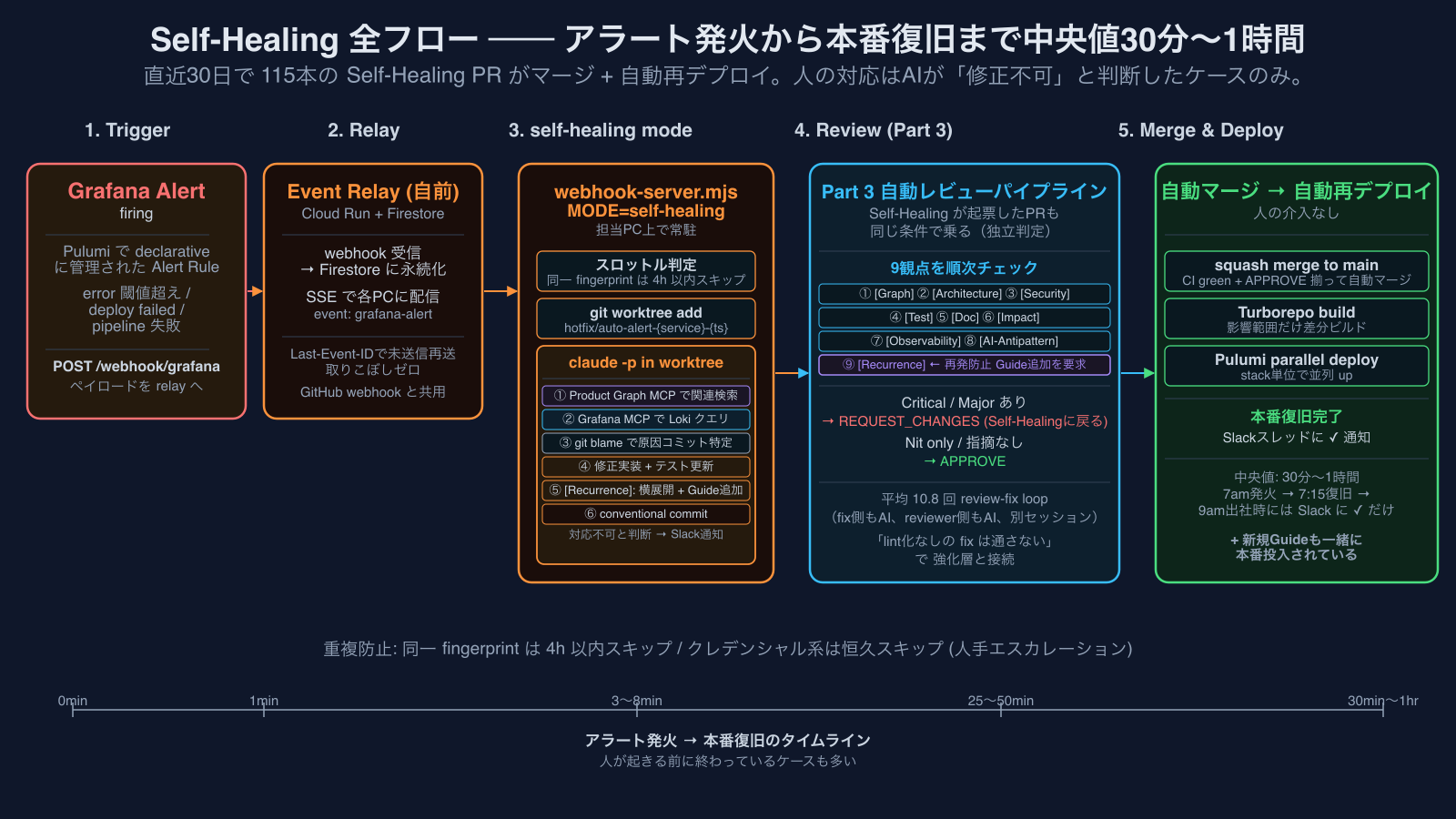
テキストで書くとこういう流れ:
[Grafana Alert Rule firing]
↓ POST /webhook/grafana
[Event Relay (自前)] ── Firestoreに永続化
↓ SSE push (event: grafana-alert)
[self-healing モードスクリプト]
↓ スロットル判定(同一fingerprintは4h以内スキップ)
↓ Slackに 👀 リアクションで対応開始通知
↓ git worktree add -b hotfix/auto-alert-{service}-{ts} origin/main
↓ claude -p をworktree内でspawn
- Product Graph MCPでサービス関連コードを検索
- Grafana MCPでLokiからエラーログを取得
- 根本原因を特定して修正
- 必要なテスト更新
- conventional commit形式で commit
↓ git push + gh pr create
[修正PR]
↓ 自動レビュー (Part 3 のパイプライン)
↓ APPROVE → 自動マージ → 自動再デプロイ
[復旧完了]
↓ Slackスレッドに ✅ 完了通知AIが「修正不可」と判断したらどうなるか
すべてのアラートがAI修正可能なわけではありません。実装では「修正不能と判断したら何も変更せずに終了」というルールにしてあって、その場合Slackスレッドに「コード修正では対応できないアラートです。調査結果: ...」という形でAIが何を調べたかの調査結果付きで通知する。
なお冒頭の「115本」はPR化されてmerge+deploy完了に到達した数で、この「修正不能で終了」したケースは別集合として月数件発生しています(外部サービスの一時障害、コードでなくインフラ設定の問題、AIの判断負荷が高すぎるケース等)。「人が出てきて対処する」のはこの別集合だけで、115のうち何件かが失敗しているわけではない、という点だけ補足しておきます。
実際に飛んでくるSlackメッセージはこういう粒度です(一例: あるtransformer系サービスのGitHub PAT失効ケース):
ℹ️ コード修正では対応できないアラートです。調査結果:
調査結果サマリ
直近1時間のエラーログをLokiで確認したところ、対象サービスの現在の唯一のエラー要因は GitHub PAT (Personal Access Token)の失効 / revoke でした。
発見した事実
- BQ snapshot pipelineは正常稼働中: 直近7回連続
[BQ] Snapshot rows insertedが成功。以前のautodetect型ドリフト障害は別PRでSAFE_CAST(... AS INT64)が適用済みで解消済み。- 現在の唯一のエラー(直近1時間以内、複数回発生):
GithubUnauthorizedError: GitHub API /commits/master unauthorized (401): PATが失効/revokeされた可能性が高い──/check-driftハンドラがCloud Scheduler起動の度に401で失敗根本原因
該当サービスのSecret Managerに保存されているGitHub Personal Access Tokenが失効/revokeされた。コード側では401を専用クラス
GithubUnauthorizedErrorとして再throwし、Slackに「PAT更新が必要」通知も既に出している。コード側の検知・通知設計は意図通り。対応方針: 無変更で終了
これは外部資格情報の運用障害(PAT失効)であり、Secret Managerを人間が新しいPATで更新する必要がある。コード変更で解決できる種類の障害ではないため、コード変更・コミット・PR起票は行わずに終了します。
オペレータ向けアクション:
- GCP Console / Secret Managerで対象シークレットに有効なPAT(
repo権限、対象リポジトリへのreadアクセス)の新バージョンを追加- Cloud Run revisionの再デプロイは不要(
secretKeyRef version:latest参照)
この粒度で「何を調査したか、なぜコード変更で解決できないか、人は何をすべきか」が全部出てくる。Slackスレッドを開けばオペレータはそのまま対応に入れるので、「アラートだけ転送される」のとは生産性が桁違いです。
重複防止
同一fingerprint(Grafanaアラートの一意識別子)に対して4時間以内は再処理しないスロットルが入っている。これがないと、修正PRがマージされる前に同じアラートが再発火 → 別worktreeで別修正PR → ... という無限ループに陥りやすい。
加えて、alertnameに「クレデンシャル」「credential」を含むものは恒久スキップ。クレデンシャル系はAIが触ると漏洩リスクがあるので、明示的に人にエスカレートする設計です。
Self-HealingとPart 3自動レビューの関係 ── 「修正AI」と「審査AI」が独立している
ここはエージェント設計として一番効いている部分なので強調しておきます。
Self-Healingが起票するPRは特別なPRではなく、ただのfix PRです。Part 3の自動レビューパイプラインに同じ条件で乗ります。9観点(Graph / Architecture / Security / Test / Doc / Impact / Observability / AI-Antipattern / Recurrence)を順にチェックされて、Critical / MajorがあればREQUEST_CHANGES、Nit only / 指摘なしでCI greenならAPPROVE → 自動マージ。
ここで重要なのは、「AIがAIを直す」一枚岩のループではなく、「修正側のAI」と「審査側のAI」が完全に独立しているという点です:
- 別プロセス・別セッション: self-healingモードのAIと、reviewerモードのAIは別の
claude -pプロセスとして起動する。コンテキストは共有されない - 別の入力ソース: 修正側はGrafanaアラート + Loki + cpgから問題を組み立てる。審査側はPR差分 + cpg + ガイドラインで判定する
- 別の評価軸: 修正側は「障害を止める」、審査側は「9観点とseverity規約に違反していないか」。利害が一致しない設計
結果として、Self-Healingが雑に書いたPRは自動レビューで弾かれる(REQUEST_CHANGES → 修正側に戻る)。AIが自分の出力を自分で承認するわけではないので、自己満足的な「とりあえず動くfix」は通らない構造になっています。
これはLLMエージェント運用でしばしば論点になる「審査の独立性」を、複数AIエージェントの分業で素直に実装した形です。
具体例: meet subscriptionの409 ALREADY_EXISTS
例として、Meeting Intelligenceで実装を書いたGoogle Meet録画の自動取得系で発火したアラートを取り上げます。2026-05-21にSelf-Healingが起票した自動修正PR(fix(meet-xxx): auto-fix for Service Error Log Detected)です。
Lokiから拾った発火元のエラー:
Workspace Events API request failed: 409 Conflict
"Subscription associated with the resource already exists."AIの調査の流れ:
- Lokiクエリでエラーログを特定 ── Grafana MCP経由で
{service_name="meet-xxx"} | json | level=~"ERROR|error|Error"を実行、Failed to renew Meet subscriptionのスタックトレース取得 - Product Graphで呼び出し経路を辿る ──
renewSubscriptions→createMeetSubscriptionのcall pathを特定 - 過去のPRと突合せ ──「逆方向の不整合」(Firestoreに名前があるがGoogle側から消えた=404)は既に別PRで
patchMeetSubscriptionTtl→ null fallbackでself-heal済み。今回の方向(Google側に残っているがFirestoreに無い=409)はまだ対応されていないことを発見 - 判定:「パターンが他にも存在しうる」状況 →
[Recurrence]判定マトリクスの「横展開必須」のケース
その場凌ぎの修正ではなく、逆方向に存在していたfallbackと対称になるように同方向の自己修復を実装しました:
createMeetSubscriptionをidempotentに変更- POSTが409を返したら、レスポンスから既存Subscription名を抽出して
patchMeetSubscriptionTtlを呼ぶ - 戻り値を呼び出し元がFirestoreに書き戻すので、次回以降のrenewalは通常のPATCHパスに収束(自己修復)
- 既存lintルール
graph/no-silent-catchに従って、JSON.parse失敗時もlogger.warn+serializeErrorで構造化ログ - テスト3件追加
これが「Self-Healingがroot causeまで踏み込んで横展開してくる」の具体パターンです。「症状を消す」ではなく「再発のクラスを閉じる」(recurrence-prevention.mdの思想)を、AIが自律的に実行している例。
強化層 ── Guides(lint+ガイドライン)が自動で増えていく
ここがSelf-Healingを単なる「自動修復」で終わらせないためのキーです。
Part 1で出てきたMartin FowlerのGuides / Sensors分類で言えば、強化層はGuidesを増やす場所 ── AIが逸脱を起こす前の事前制御を厚くしていく側に当たります。cortexのGuidesは2層構造になっていて:
- 機械が読むGuide: lint / 型 / CI guard / カバレッジ閾値 / Prettier ── commit/CIで違反を物理的に潰す
- 人とAIが読むGuide:
recurrence-prevention.md、severity.md、ai-antipattern.md等のガイドライン ── 自動レビューが判定基準として使う
Part 3で書いた9観点やseverity規約・降格禁止ルールが後者、Part 4で書く自動lint追加が前者の話で、両者がセットでGuidesを構成する。lintは「形式化されたガイドライン」、ガイドラインは「まだ形式化されていないlint」と言ってもいい。
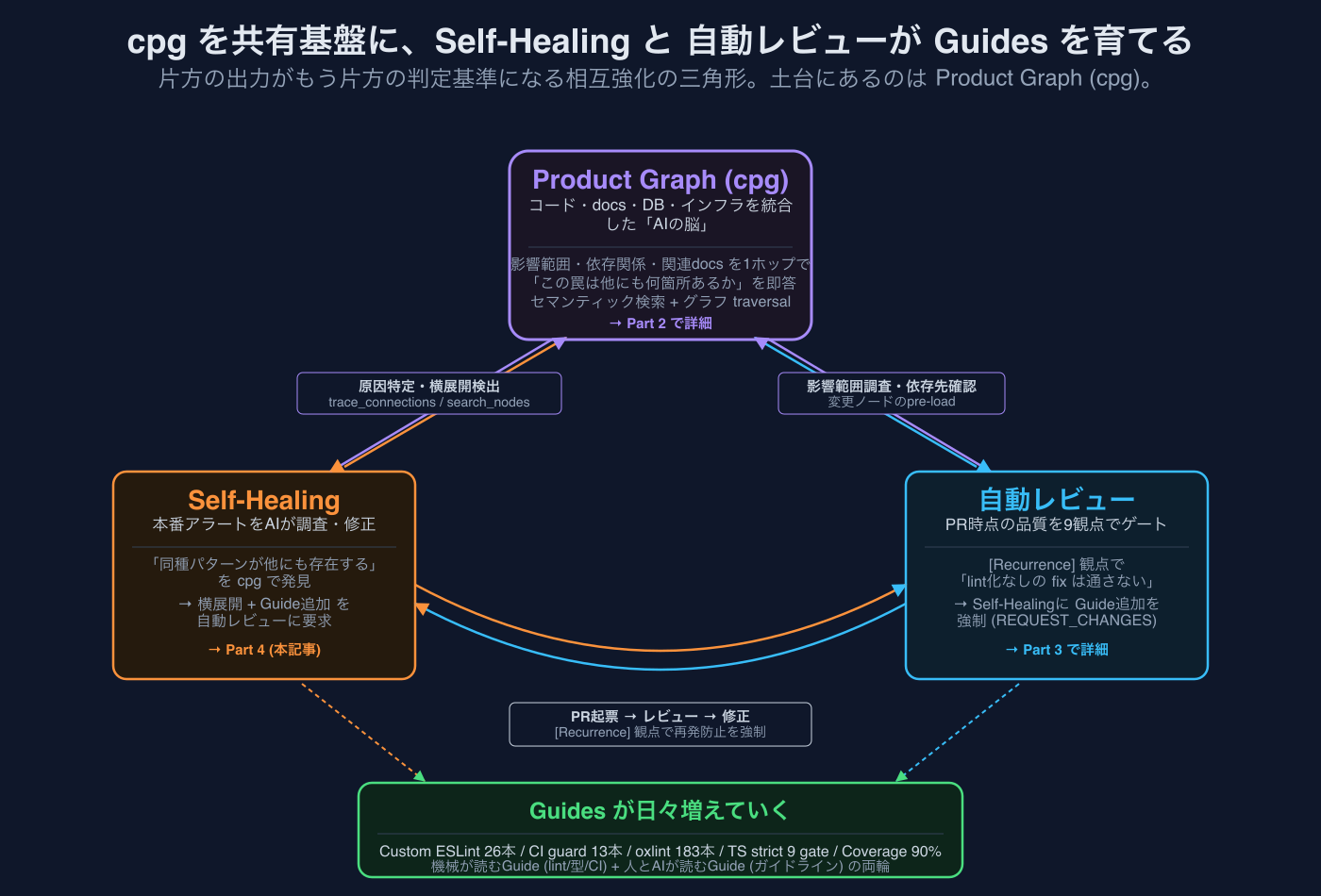
そしてSensors側のSelf-Healingと自動レビューが動くたびに、このGuidesを互いに増やしていく構造になっています:
- Self-Healingが原因調査で「同種パターンが他にも存在する」と発見 → 横展開+lint化(新Guide追加)を要求
- 自動レビューが
[Recurrence]観点で「lint化なしのfixは通さない」と弾く - どちらもcpgで影響範囲を見渡せるからこそ可能
cpgがあるからAIは「この罠は他にも何箇所あるか」を見られる。Self-Healingと自動レビュー(= Sensors)はcpgを共有基盤として、出力のたびにGuidesを1段階厚くする関係です。
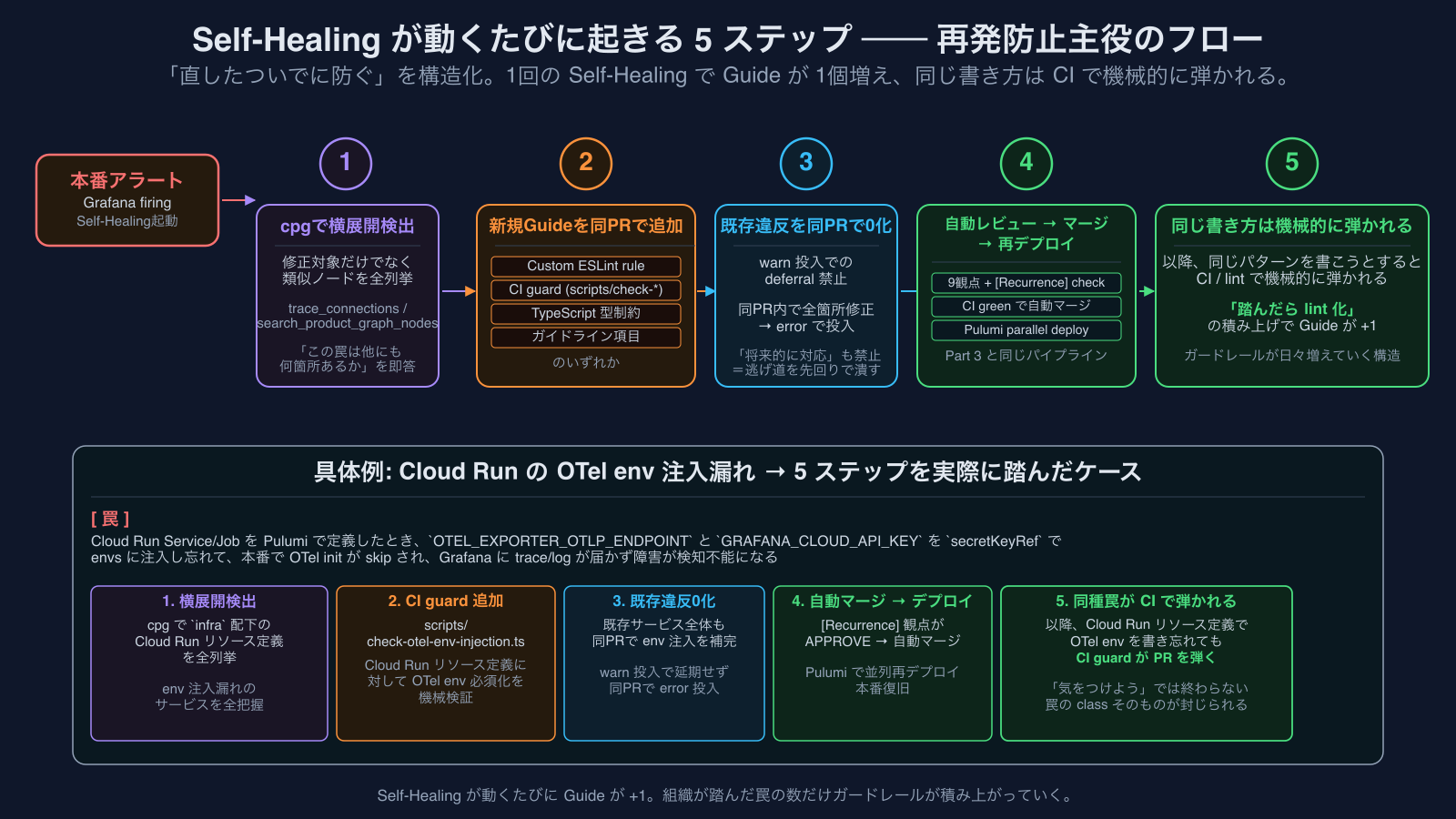
Self-Healingが動くたびに何が起きるか(再発防止主役のフロー)
Self-Healingが起票するfix PRは、自動レビューで[Recurrence]観点もチェックされる。判定マトリクスはこう:
| 状況 | 必須アクション | 形式 |
|---|---|---|
| 同じ罠を2回以上踏んだ | lint化を必須(custom ESLintルール / 型制約 / CI guard) | 機械化(Guide追加) |
| パターンが他にも存在しうる | 横展開を必須(cpgで類似ノード走査、既発見箇所も同PRで修正) | 調査+修正 |
| 機械検証不能だが原則として価値あり | 既存ガイドラインに項目追加 | ガイドライン追加 |
| 単発・原則化価値なし | 何もしない(bug fixのみ) | — |
「同じ罠を2回以上踏んだ」状況では、修正PRに新規lintも含めないとマージされない。結果として、Self-Healingが動くたびに以下が起こります:
- 同種パターンをcpgで横展開検出 ── 修正対象だけでなく、類似ノードを全列挙
- 新規Guideを同PRで追加 ── ESLint custom rule / 型制約 / CI guard / ガイドライン項目のいずれか
- 既存違反は同PR内で0にする ──
warn投入でのdeferral禁止、errorで投入 - 自動レビュー → 自動マージ → 自動再デプロイ ── Part 3の通常パイプライン
- 以降、同じ書き方をしようとするとCI / lintで機械的に弾かれる ── 同種パターンの再発を構造的に塞ぐ
「直したついでに防ぐ」が、Self-Healingを起点に自動で回り続ける構造です。
「将来的に対応」「warnで導入」は禁止
ガイドラインに明文化されている重要なルール:
- 「将来的にlint化を検討」「次回リファクタリング時に検討」「別PRで対応」── すべて禁止。対応可能なら同PRで対応する
- 「既存違反が残るため
warnで導入し、後段でerrorへ昇格」── 採用しない。これは事実上のdeferralで、warnをerrorに昇格する責務が宙に浮いて陳腐化する - lintルールを追加するなら同PRで既存違反も0にして
errorで投入する
これも結局はPart 3で書いた「降格禁止ルール」の系譜で、典型的な逃げ方を先回りで潰すという発想です。
「踏んだらGuide化」の系譜(実例集)
cortexに積み上がっているcustom Guideの実例:
graph/no-silent-catch(ESLint)── 冒頭の「上振れ」の元凶。catchブロックで例外を握り潰すパターンを禁止- stacktrace消失防止のガイドライン(
docs/guidelines/observability.mdでMajor違反として規約化、自動レビューが捕捉)──logger.error(err.message)のようにstacktraceを捨ててmessage文字列だけ残すログを禁止。errフィールドにserializeError(error)の戻り値を入れてname/message/stackを構造化保持することを強制。Observabilityは命なので、stack情報を消すログは存在自体が罪扱い cortex-quality/require-fetch-timeout(oxlint^[oxlint = Rust製のJS/TS lint。ESLint互換のルールセットを動かしつつ、Rust実装ゆえESLintより数十倍高速。cortexでは標準ルールはoxlint、AST情報が必要なcustomルールはESLintという棲み分けで併用しています。])── 外部APIへのfetchにsignal: AbortSignal.timeout(...)必須。timeout無しfetchがhangしてCloud Tasks再配信ストームを引き起こした事例からgraph/no-bq-string-timestamp-param(ESLint)── BigQueryのクエリパラメータでTIMESTAMPをstringで渡すと、serializerバグでNULL化してINSERT全失敗する事例からgraph/require-firestore-ignore-undefined(ESLint)── Firestoreのnew Firestore()にignoreUndefinedProperties: true必須化。NULL行で同期batchが100%失敗した事例からcheck-otel-env-injection(CI guard)── 後述のCloud Run OTel env注入漏れの再発防止- TypeScriptの型定義の強化(型レベル)── 関数シグネチャをstricterにする / 取り違え防止のbranded type追加 / discriminated unionで網羅性を強制 等。lint化できないがtype gateで弾けるパターンは型側で潰す
これらは全部「事前に教科書で習える」のではなく、「踏んでから機械化した」もの。組織が踏んだ罠の数だけGuideが積み上がっていきます(ESLint / oxlint / CI guard / 型定義の4層で)。
AIはどうやってlintルールを壊さず書くのか
「AIがlintルール自体をどう壊さず生成しているか」── ここを支えているのは以下の構造です:
- 既存ルールがテンプレート: customルール用のディレクトリには26本の既存ルールが
.ts+.test.tsのペアで並んでいて、AIは新規ルールを書くとき「同じ形」を踏襲できる。AST操作のboilerplateを毎回ゼロから書かない - テストが先: 違反パターン / 合格パターンの最小fixtureを
.test.tsに書き、TDDで実装を埋める。テストカバレッジ閾値90% をPart 3の自動レビューがgateするので、テスト無しのlintはmergeできない - lint / 型 / CI guardは同じ「機械化バケット」:
recurrence-prevention.mdの判定マトリクスはlint・型制約・CI guardをひとまとめに「lint化必須」(= 機械化)として置いていて、3者の中での選択(lintとして書くか / 型側で表現するか / 別途CI guardでチェックするか)はAST操作量と副作用依存度に応じてAIに判断させる構造。AST走査が必要だがruntime semanticsに依存して判定しきれない罠は、custom lintよりも型制約(branded type / discriminated union / 関数signature tightening)に倒すケースが多い
つまり「AIにlintを書かせる」のは 既存ルール群 + テストハーネス + 機械化バケットの選択基準 の3点で支えられていて、AIがESLint APIを生で書き起こして事故るルートは構造的に閉じている、というのが運用の実感です。
具体例: Cloud RunのOTel env注入漏れ → CI guardへの昇格
過去に複数サービスで「Cloud Run Service/JobをPulumiで定義したとき、OTEL_EXPORTER_OTLP_ENDPOINTとGRAFANA_CLOUD_API_KEYをsecretKeyRefでenvsに注入し忘れて、本番でOTel initがskipされ、Grafanaにtrace/logが届かず障害が検知不能になる」という罠を踏みました。
普通なら「気をつけよう」で終わる。cortexでは:
- 障害発覚 → Self-Healingが修正PR起票(該当サービスにenv注入を追加)
- 自動レビューの
[Recurrence]が「同じ罠を踏んだ → lint化必須」と判定 - 同PRに
scripts/check-otel-env-injection.ts(CI guard)を追加 ──infra配下のCloud Runリソース定義に対してOTel env必須化を機械検証 - 既存サービス(全体)も同PRでenv注入を補完
- マージ → デプロイ → 以降、同じ罠はCIで弾かれる
これが「Self-Healingが動くたびにガードレールが増える」の具体パターン。罠は「踏んだら機械検証」される。
Guidesの現在地(数で見る)
直近のcortex repositoryのGuideインベントリ:
| カテゴリ | 数 | 補足 |
|---|---|---|
Custom ESLintルール(@cortex/eslint-plugin-graph) |
26本 | no-silent-catch / require-firestore-ignore-undefined / no-bq-string-timestamp-param等 |
CI guard(scripts/check-*.ts) |
13本 | check-otel-env-injection / check-cloudscheduler-oidctoken-audience等 |
Standard oxlintルール(error設定) |
183本 | base configで一律errorで投入 |
| TypeScript strict系(baseline) | 9 gate | strict / noImplicitAny / strictNullChecks / noUncheckedIndexedAccess等 |
| TypeScript型定義の強化(per-recurrence) | 都度追加 | branded type / discriminated union / 関数シグネチャtightening等。lint化できないがtype gateで弾けるパターンを型側で潰す |
| テストカバレッジ閾値 | statements + branches 90% | 全packageで一律 |
| Prettier | 1 config | フォーマット自動修正 |
| ガイドライン | review-guidelines repository全文 | 自動レビューの判定基準 |
このうちCustom ESLint / CI guard / 型定義の強化が、[Recurrence]観点を通じてSelf-Healingと自動レビューが動くたびに右肩上がりで増えていく部分。ガードレールは時間とともに育つ ── これが強化層の本質です。
全体ループの俯瞰
3層を組み合わせると、こうなります:
[本番異常] → 観測層 (OTel/Loki/Grafana) → Alert firing
↓
Event Relay → SSE
↓
[Self-Healing mode script]
- claude -p in worktree
- cpg + Loki + git blame で原因特定
- 修正コミット
- (該当すれば) 新規lint/型ゲートも追加
- gh pr create
↓
[自動レビュー(Part 3)] ── 9観点を順にチェック、特に[Recurrence] で
再発防止アクション(lint化 / 横展開 / ガイドライン追加)を必須化
↓
APPROVE + CI green
↓
[自動マージ → Turborepo build → Pulumi parallel deploy]
↓
[本番復旧 + 同じ書き方は以後機械的に弾かれる]このループは人の介入なしで一周まわる。修復だけでなく、修復のたびに品質ゲートが育つ ── これがcortexの「自動回復+自動強化」の中身です。
ただし冒頭でも書いた通り、このループが成立するのはcpgとObservabilityがあるからです。cpgが影響範囲の横展開を可能にし、Observabilityが本番異常を構造化データとして拾う。この2つが土台にあって初めて、AIが「修復」「強化」を回せる側に立てる。Self-Healingは単独で立つ仕組みではなく、cortexのGuides(cpg + Observability + lint + ガイドライン)の上に乗っているSensorです ── ここが本記事の一番伝えたいところです。
数字で見るSelf-Healing
冒頭の数字をもう少し分解しておきます。
主な発火カテゴリ
直近30日にSelf-Healingが起動したカテゴリ(冒頭2bucketとの対応も併記):
| カテゴリ | 含まれるbucket |
|---|---|
| Service Error Log Detected(最頻) | 本番ランタイム系(61本側) |
| Pipeline Failure ── データパイプラインの一定回数連続失敗 | 本番ランタイム系(61本側) |
| Generator Failure ── AI生成系ジョブ(embedding / annotation等)の失敗 | 本番ランタイム系(61本側) |
| Deploy Failed ── デプロイ失敗(Pulumi up / Cloud Run revision failed) | デプロイ段階(54本側) |
アラート発火から本番復旧までの時間
中央値で30分〜1時間程度。内訳は概ね:
- アラート発火 → AI調査開始: 1分以内(Event Relay+SSE)
- AI調査・修正・PR起票: 3〜8分
- 自動レビュー(Part 3で書いた平均10.8回のreview-fix loopを含む): 20〜45分
- 自動マージ+デプロイ: 3〜10分
人が起きる前に終わっているケースも多いです(早朝発火 → 出社時にはSlackに ✅ 通知だけ)。
何が変わったか / Bridge to Part 5
ここまでで、Part 1〜4を通したcortexの全体像がほぼ揃いました:
- Part 1: cortex全体像とハーネスエンジニアリングの位置取り
- Part 2: Product Graph(cpg)── AIの「脳」
- Part 3: 自動レビュー ── PR時点の品質を守る
- Part 4(本記事): Self-Healing+Observability+自動lint追加 ── 本番時点の品質を守りつつ、品質ゲート自体を育てる
エンジニアの役割は、ここ半年で「書く」「見る」「直す」「マージする」「デプロイする」「障害対応する」のすべてから、システム全体を上から見て調整する役回りに移っています。human-on-the-loop、Policy層で運用する立ち位置。
ただし、これはcortexという社内AI基盤で完成した型。実際のtoCサービス(複数サービス・複数stack・複数チーム)に同じ型を持ち込もうとすると、いくつか変えないといけない部分・新規に必要な部分が出てきます。
次回Part 5では、ハーネスが「誰が書くか」のレイヤーまで波及している話を書きます。中心は業務要件を一番把握している人(事業マネージャー / PMO等の非エンジニア)が本番に直接PRを出せるようになった動線で、+1,742行 / 41ファイルの大型機能を非エンジニアが書いて、人間レビュアー0でmergeまで通った実例も具体に紹介します。品質を担保しているのはこの連載で積み上げてきたハーネス側 ── 「書く人は変わっても、品質の担保はハーネスが受け持つ」というのがPart 5の位置取りです。
toCサービスへの展開構想についても末尾で方向感だけ触れますが、本格的な実装話は別記事に切り出す予定です。
そして最後のPart 6は連載全体の総括です。中心はそもそもどういう思想でこれをやっているのか ── 何を捨てて何を取ったか、なぜこういう設計を選んでいるのか、という土台の話。あわせて、ここまでの記事では「うまく回っている結果」を中心に書いてきたので、その裏で踏んできた失敗・つまずきも振り返って、思想と実装のあいだのギャップも整理したい。自分自身の振り返りでもあり、同じようなことを始めようとしている人にとっての参考にもなれば、と考えています。
comments (0)
まだコメントはありません。