みなさまこんにちは!エアークローゼットでCTOをしている辻です。
Part 1(総論)で、cortexというプラットフォーム上でAIがPRレビューや障害対応を回している話を書きました。そのflywheelの中心にいるのがProduct Graph(実装名: cortex-product-graph、以下cpg)です。
Part 1では「コード・docs・DBスキーマ・インフラ定義が1つのナレッジグラフに統合されていてセマンティック検索できる」という抽象だけ書きました。今回はその中身 ── どう作ったのか、なぜこの設計に落ち着いたのか、何が変わったのかを書きます。
連載一覧
| # | テーマ | キーシーン | 記事 |
|---|---|---|---|
| 1 | 総論:cortexのハーネス | PRが無人マージ / 障害が気づく前に治っている | ai-harness-intro |
| 2 | Product Graph (cpg) | コード・ドキュメント・DB・インフラを1グラフに統合 | 本記事 ←現在地 |
| 3 | AI PRレビュー | webhook → AIレビュー → 自動修正 → squash merge | cortex-auto-review |
| 4 | Self-Healing + Observability + 自動lint追加 | アラート → AI調査 → 修正PR + 新規lint/型gate → 自動再デプロイで同じ書き方を機械的に弾く | cortex-self-healing |
| 5 | 改修フェーズの民主化 | 業務要件を把握している人が本番に直接PR、ハーネスが品質を担保 | cortex-non-engineer-prs |
| 6 | 連載総括・最終章 | 根底にある思想(何を捨てて何を取ったか / なぜこの設計か)と失敗の振り返り | cortex-philosophy |
いきなり1つのシーンから
「KPIダッシュボードに出てる "バグ発生率" の計算ロジックを変えたい。どこにあって、何か壊れる?」── 実装に入る前に、こんな問いが立ったとします。
AIにこの問いをそのまま投げると、関数名もファイルパスも与えていないのに、AIはcpgをセマンティック検索で叩いて関連ノードを一気に拾います。返ってくるのは関数だけでなく、該当するBigQueryテーブルやAPIエンドポイントまで含めた候補リスト。レスポンス末尾の「次のアクション候補(Runbook)」を見て、AIは書き込み / 読み取りの両方が集まっているBQテーブルを起点にトレースを打ち直します。
最終的にAIが返してくる答えはこんな感じです:
- 計算箇所:
calculateRatePer100pt/calculateBugCount── どちらも純粋な計算関数で、外部I/Oは持たない(変更しても直接の副作用はない) - 書き込み側(上流):
syncKpiMetrics/writeKpiMetrics/backfillKpiMetricsがkpi_bug_rate_per_100ptテーブルに書き込み。これが集計バッチの本体 - 読み取り側(下流): BigQuery経由で
BigQueryKpiRepository.getSummaryByDateが読み、/kpi/bugsAPI → KPIダッシュボードPageに繋がる - 関連docs:
docs/generator/kpi.mdにバグ発生率の定義あり。コードを変えるならdocsも同時更新が必要
「じゃあdocsを併せて変更して、デプロイは集計バッチが動いていない時間帯にする」と判断できる。
もちろん私自身は、この計算ロジックも関数もBQテーブルも全部知っています。書いたのが自分だから。でも逆に言うと、私以外の人はここを触れない。誰かが「バグ発生率を変えたい」と思ったら、結局私を捕まえに来る以外なくなる ── というのが3ヶ月前までの状況でした。
今では、上のような調査と判断をPMOのメンバー(非エンジニア)がcpgを使って自分でやっています。grepでも設計書でも届かなかった「コードに何があって、何が壊れるか」が、自然言語の問い1つで取れるようになった結果です。
これを実現しているのがcpgです ── コード・docs・DBスキーマ・インフラ定義をひとつのナレッジグラフに統合したもので、関数名を知らなくても「やりたいこと」の自然言語から関連情報を1〜2ホップで辿れる。ツールの返却値そのものが「次に叩くべきツール」を示すRunbook構造になっているので、AIが起点ノードを自分で選び直して深掘りできるのもポイントです。
ここからは、これがどう作られているかの話です。
静的解析だけのcode-graphでは届かなかった
cortexのプラットフォームは、別途静的解析でコードベースをグラフ化するシステムを持っています(詳細は別記事で書く予定なので、ここでは触れる程度)。社外向けの本番リポジトリ群を対象に、JS/TSのコードをAST解析して、関数の呼び出し関係、APIエンドポイント、DBアクセス、イベント発行・購読といった依存関係を自動抽出する仕組みです。
これは静的解析として正確で、社外向けリポでは現役で使っています(後述)。ところがcortex自身に対してこのアプローチを適用すると、「思い描いていた成果」には届きませんでした。
具体的に届かなかった点は3つです:
- コンテキストがない ── ノードはあるけど、「このAPIが何のためにあるか」「なぜこのテーブルにこのカラムがあるか」といった意味がgraphに乗っていない。AIに「KPIのバグ率を計算しているコードはどこ?」と聞いても、関数名や引数名がたまたまそれっぽくないとヒットしない。
- 進入点がない ── 目的のファイルパスや関数名を既に知っていないと検索が始められない。「ちょっと探してくる」が成立しない。
- 数ホップでバースト ── 起点ノードから1〜2ホップ進むだけで関連ノードが指数的に膨らみ、AIが一度に処理できるサイズを軽く超える。トレースの結果が長すぎて使えない。
要は、**「機械的に正確だが、意味の重みづけがない」**グラフだった、という話です。AIが活用するには、もう一段「何が重要か / なぜ繋がっているか」が必要でした。
一方、DB graphはうまくいっていた
ちょうどその頃、別アプローチで作っていたDB Graph MCPは、期待通りに動いていました。
DB Graphは、cortex内の15スキーマ・991テーブルにアクセスするMCPサーバーで、テーブルやカラムをAI生成の説明文付きでセマンティック検索できます。たとえば「返却処理の確認に関するテーブル」のような自然言語クエリで、テーブル名に "返却" が含まれていなくても意味で繋がるノードが返る。
何が違ったのか、しばらく考えてからわかりました。DB graphには「カラム説明・テーブル説明」というビジネスコンテキストが各ノードに付いていて、それがEmbeddingに乗っている。これが「意味で繋がる」を支えている本体だった、というのが本質でした。
静的解析のcode-graphには、それがなかった。型と呼び出し関係はあっても、「なぜこの関数があるか」は誰も書いていない。
仮説 ── DB graphのエッセンスをcode graphに持ち込めれば
ここからの仮説はシンプルでした:
「ノードごとにビジネスコンテキストが書かれていて、それがembeddingに乗っている」── これだけがDB graphがうまくいっているエッセンスなら、code graphに同じことをやれば、静的解析の限界を構造的に超えられるはず。
問題は、どこに「ビジネスコンテキスト」を持つかでした。
選択肢を全部並べると、こうなります:
| 持ち場所 | 例 | 問題 |
|---|---|---|
| 外部ドキュメント | 設計書 / wiki / Notion | コードと別管理。すぐズレる。誰もメンテしない |
| 外部メタデータ | sidecar YAML / *.meta.json |
ファイルが二重管理。リネーム時に簡単に壊れる |
| 専用グラフDB | Neo4j / Neptuneに注釈を直接持つ | ソースとDBで二重管理になる。PR diffに出てこないのでレビュー不能 |
| TypeScript decorator | @GraphNode({...}) をコードに付ける |
トランスパイルに乗る = ランタイム依存が増える。AST解析だけでは取りきれない |
| DSLファイル | 独自記法 .graph ファイル |
新しい記法を学ばせるコストが高い。エディタ補完も自前 |
| JSDocコメント | @graph-business / @graph-connects |
コード本体と物理的に同じ場所。ASTだけで拾える。ランタイムゼロ依存 |
特にdecoratorではなくJSDocを選んだのは意図的です:
- ランタイムゼロ依存: decoratorはトランスパイル後のコードに残るので、ランタイム挙動に影響する可能性がある。JSDocはコメントで実行意味を持たず、production buildでコメントを除去すればビルド成果物にも残らない
- コード以外にも同じ形式で広げられる: 同じ
@graph-*表記をinfra/のPulumi定義やdocs/のmarkdown frontmatterに展開できる。decoratorはTypeScript文法に縛られる - AST解析だけで全部拾える: ts-morphで宣言を巡れば、コードもJSDocも1回の走査で取れる。decoratorだと型情報の解決が要る場面が出てきて、ビルドが重くなる
- PR diffに自然に出る: JSDocはコードの直上に書くので、コードを変えるPRには関連JSDocの変更が必ず同じファイルに乗る。レビュアーが見落とさない
- 読み手(人もAIも)にとってのドキュメントとして同時に機能する: JSDocは元々IDEのホバー表示やAIエージェントが読むコンテキストとして使われる場所。
@graph-businessをその場所に書けば、コードを読む人には宣言の意図がその場で読めて、コードを書くAIにとっても周辺関数の意味を把握する手がかりになる。グラフ用のメタデータが、二次的にコードリーディング/編集の補助情報にもなる二重の働き
なお、この設計の本質は「コードに付随する解析可能な注釈をSSoTにする」という構造で、TypeScript / JSDocはあくまでその一実装です。Pythonならdocstring + ast、Goならコメント + go/ast、Rustなら /// + syn のように、同等の組み合わせがあればどの言語でも同じパターンで実装できます。重要なのは「注釈をどこに書くか」ではなく「コードと物理的に同じ場所に、AST解析だけで取れる形で書く」という不変条件です。
同じく、cortexがmonorepoだからこのパターンが成立する、というわけでもありません。むしろ、リポジトリが分かれていてAIにコードを追わせづらい状況でこそ真価を発揮します。monorepoならAIもgrep / file readで何とか追えますが、multi-repoだとリポをまたいだ呼び出しやデータフローを追うこと自体が困難。各リポで同じビルドを走らせてノード / エッジを吐き、中央のグラフに集約してしまえば、リポ境界を越えた繋がりがAIから1ホップで見えるようになります。実際、社外向け本番リポ群(multi-repo構成)に対しても同等のナレッジグラフを別途運用しています(詳細はまた別の機会に)。
アプローチ ── 「コードからの推論」を捨て、JSDocをSSoTにする
code graphの問題は「意味がないこと」でした。なら、答えは単純です ── 意味そのものをコードに埋め込んでしまえばいい。
cortex内のcode graphでは、コードだけから意味や接続を推論する方針を完全に捨てました。代わりに、
すべての宣言(関数 / クラス / メソッド / API / Page / Cron / etc.)に専用のJSDocタグを書く。グラフはそこから組み立てる。
という方針に振り切りました。
これが何を意味するかというと、ビジネスコンテキストのSSoT(Single Source of Truth)がコード自身になるということです。docsとcodeの間にギャップがあるのではなく、コードに書かれているJSDocがそのまま正本。ドキュメントが古いからAIも間違える、みたいな構造的問題がここで一段解消します。
同じソースコードから取れる「コードからの推論だけで作ったグラフ」と「JSDocをSSoTにしたナレッジグラフ」を並べると、ノードに何が乗っているかの違いがはっきりします:
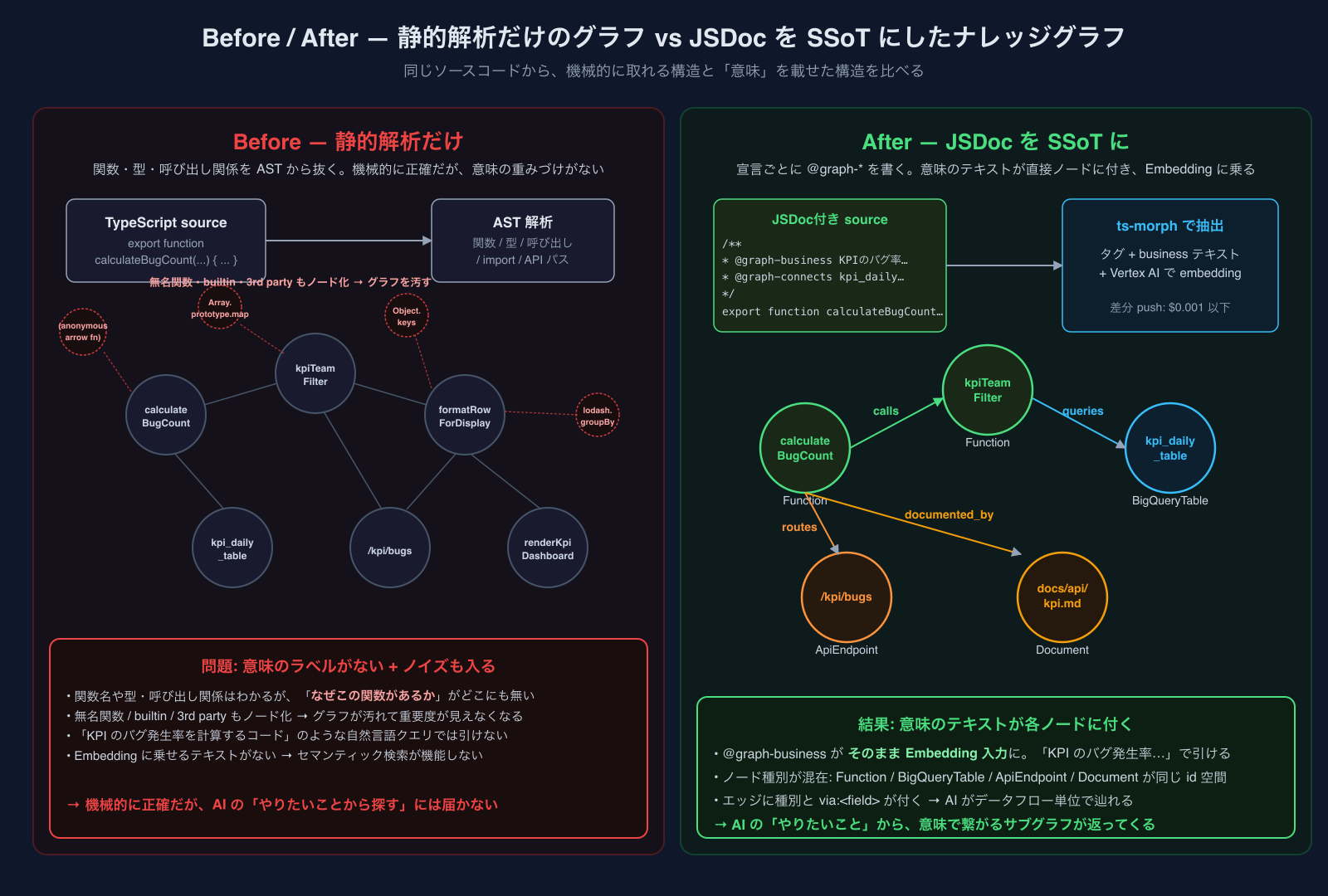
具体的なタグはこんな感じです(cpg自身のコードから一例):
/**
* ノードにembeddingを設定(in-place)
* BQの既存データと比較し、textForEmbedding が変わったノードのみ再生成
*
* @graph-stack product-graph
* @graph-domain Engineering
* @graph-business 既存BQノードのtextForEmbeddingハッシュと比較し、変更があるノードのみembedding再生成。未変更ノードはBQのembeddingを再利用
* @graph-connects cortex.product_graph_nodes [queries, via:id] 既存embedding読み込み
* @graph-connects vertex-ai-embedding [calls] 変更ノードのembedding生成
*/
export async function generateEmbeddings(
nodes: ProductGraphNode[],
options: { force?: boolean } = {},
): Promise<void> { ... }タグの役割を整理すると:
| タグ | 役割 |
|---|---|
@graph-node |
ノード種別を明示(省略時はFunction) |
@graph-stack |
この宣言が属するinfra stack名 |
@graph-domain |
ビジネスドメイン(カンマ区切りで複数可) |
@graph-business |
この宣言が何をやるかの固有説明(Embedding入力の本体) |
@graph-connects |
接続先(複数可、 via: でパラメータレベル追跡、none で接続なし明示) |
@graph-business がEmbeddingテキストの入力になるところがミソです。ノード名でなく、自然言語の一文がAIの検索に効く。実際にこの一文を書いているのはほぼAIで、cpgの場合は普通にコードを書いていく流れの中でAIがJSDocも一緒に書いてくれます(後述のESLintで漏れたら落ちるので、AIも書き忘れない)。
書き漏らしを物理的に許さない
ただし、この設計は書き漏らしを許すと一発で崩れます。1つでも @graph-business のない関数があれば、その関数は意味検索でヒットしない。1つでも @graph-connects のない関数があれば、その関数を起点 / 終点とするデータフローがgraphに乗らない。
なので、書き漏らしを物理的に許さない仕組みを組みました:
- ESLintプラグイン5本 ── タグの存在検証、構文検証、命名規則(stack / domainのallowlist)、
@graph-connects必須化、@graph-connects noneの誤用検知(外部サービス呼び出しのコードにnoneを書いた疑いを検知) - 自動PRレビュー(Part 1 ③)── タグ漏れを
[Graph] Criticalで指摘、docsとの乖離を[Doc] Criticalで指摘
結果として、**「コードを書いた瞬間、ビジネスコンテキストが必ず一緒に書かれている」**状態が成立します。新しい関数を足すと、その関数の意味と接続先も必ずJSDocに書かれる。
ここで本音を書いておくと、「すべての宣言に5タグを書け」というルールを人間に強制したら、たぶん3日でレビューが荒れます。1関数足すたびに @graph-business を一文ひねり出して、@graph-connects を漏れなく列挙して、命名規則のallowlistを参照して、と——これを毎回やるのは普通にしんどい。
これが成立しているのは、コードを書くのが基本AIだからです。AIにとって必須4タグ(+ 省略時に Function default になる @graph-node を必要な時だけ)を書く労力は、コード本体を書く労力に対して誤差みたいなものです。ESLintや自動レビューがフィードバックループに入っていればAIは漏れなくタグを書きますし、人間レビュアーは「タグが事実と合っているか」を見るだけで済む。
ハルシネーションの起こる場所が変わる
ここで起きていることを別の角度から見ると、ハルシネーションの位置が変わっているという話でもあります。ハルシネーションをどこに閉じ込めるかは、AIハーネス設計の基本だと考えています。
別記事(Agentic Graph RAG)でも書いたように、AIとgraphを組み合わせるシステムでは「ハルシネーションは消えるわけではなく、起こる場所が変わる」だけです。cpgの場合、その位置はこうなっています:
- graph構築 / 参照フェーズ: 新たな LLM 生成は無い。レビュー済みのメタデータがgraphに載った後は、ts-morphによるAST解析、BigQueryへのMERGE、MCPからの参照、いずれも決定論的に動く
- JSDoc記述フェーズ: ここがハルシネーションの入口。
@graph-businessが事実と合っているか、@graph-connectsの列挙が漏れていないか、はAIが書く以上、間違える余地がある
ただし、入口は自動PRレビューで固められている。タグ漏れは [Graph] Critical、事実誤認は [Doc] Critical でブロックされる。コードが間違っていれば、それを書いたAI自身か、別のレビュアーAIが指摘して直す。
結果として、graphに乗ったあとのデータは「レビュー済みのコードから決定論的に取り出された事実」として扱える状態が成立します。クエリのたびにLLMが新規生成した答えではないので、AIエージェントがcpgを叩いて返ってくるノードやエッジに「これは生成された嘘かもしれない」というガードを掛ける必要がない。事実だけを返すツール、として設計を割り切れる。
ビルド ── ts-morphで拾って、コンテキストごとグラフ化
JSDocがSSoTとして書かれていれば、あとはそれを拾ってgraph化するだけです。実装としては:
- ts-morphでJS/TSのコードをAST解析する ── すべての宣言(関数 / クラス / メソッド / 型 / enum / 変数 / 式文 /
export default等)を順に拾う - JSDocから
@graph-*タグを抽出 ── 必須4タグと省略可能な@graph-nodeを順に拾い、ParsedGraphTagsの構造に正規化 - ノードを生成 ──
qualifiedName = "<filePath>:<name>"をidにしてgraphノードを作る - エッジを生成 ──
@graph-connectsのエントリごとに1本のエッジ。via:/cardinalityなどのメタデータも保持 - Embeddingを生成 ──
@graph-businessテキストをVertex AI Embedding(gemini-embedding-2)に投げてベクトル化 - BigQueryにロード ── 全ノード / エッジを
cortex.product_graph_nodes/cortex.product_graph_edgesにMERGE
@graph-business をそのままEmbedding入力にしているので、自然言語で「KPIのバグ発生率を計算しているコード」と聞いたとき、関数名に "bug" や "rate" が入っていなくても、説明文の意味的近さでヒットするようになります。
全体のフローはこんな形です。apps/ / infra/ / docs/ の3系統がそれぞれパーサーを通り、generatorで1つのノード集合にマージされ、差分のあるノードだけVertex AIに投げてBigQueryに格納されます:
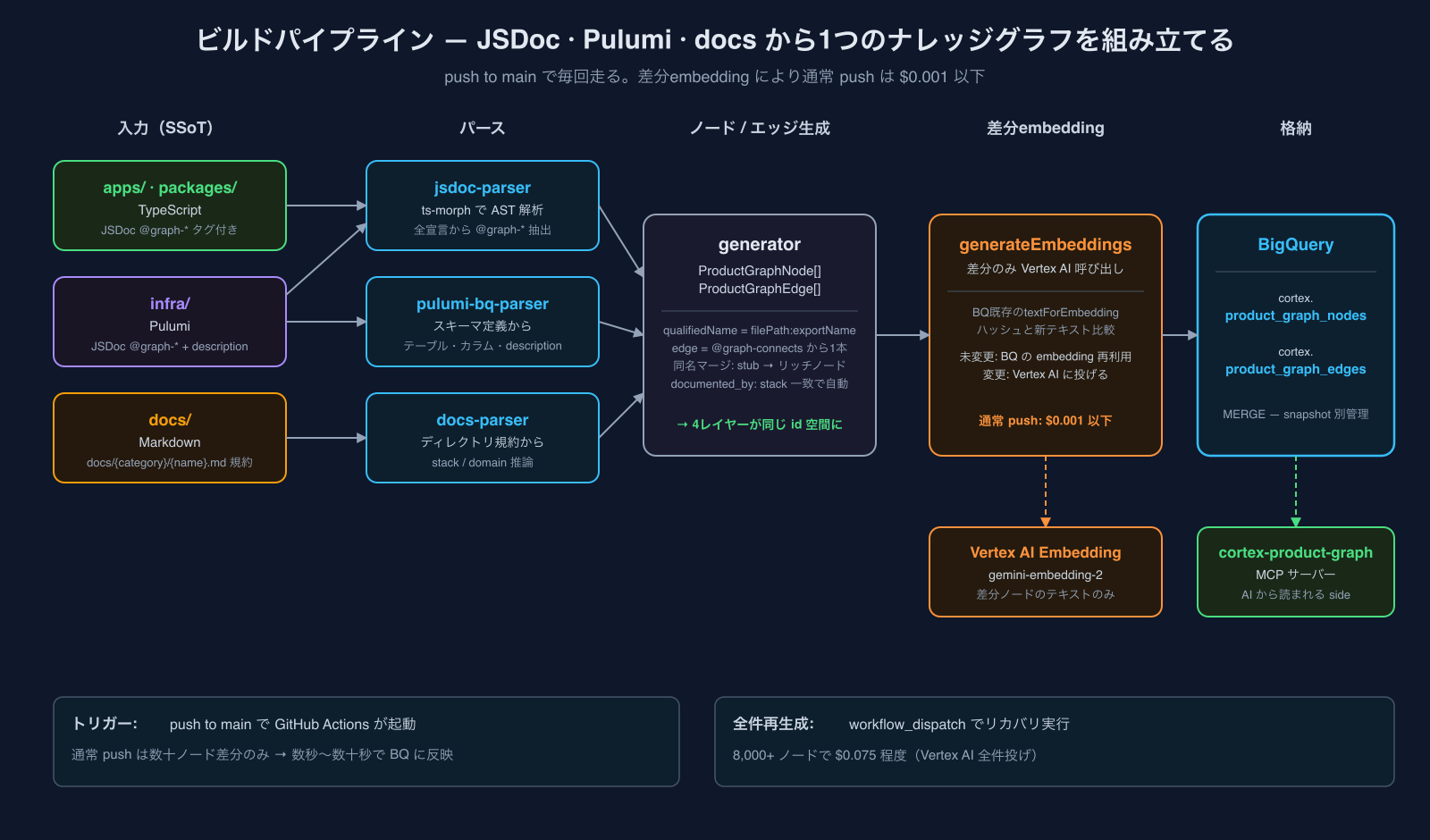
ビルドコストはほぼゼロ
ビルドはGitHub Actionsでpush to main時に自動実行しています。差分Embeddingを実装していて、
- BQの既存ノードの
textForEmbeddingと新しいテキストを比較 - 変わっていないノードはBQの既存embeddingをそのまま再利用
- 変わったノードだけVertex AIに投げる
通常のpushでは数十ノード程度の変更なので、コストは**$0.001以下**で済みます。全件再生成(リカバリ用、workflow_dispatch でトリガー)でも8,000+ノードで$0.075程度。
なぜストレージにBigQueryを選んだか
「ナレッジグラフ」と聞くと、専用のグラフDB(Neo4j、Neptune、Memgraph等)を立てる構成を思い浮かべる方が多いと思います。cortexではBigQueryに2テーブル(product_graph_nodes / product_graph_edges)を持つだけで組んでいます。理由は3つ:
- コスト構造がそもそも違う ── 専用グラフDBは「クラスタを常時立てるコスト」が下限になりますが、現在の実装ではBQはストレージ + 叩いたぶんだけのオンデマンドクエリ。AIエージェントから常時叩かれるのでクエリ料金は無視できない量にはなりますが、それでもサーバを24/7立てる構成より明確に安く済むのが大きい。
- ベクトル検索 / コサイン類似度 / SQLが同じ場所で書ける ── BQには
VECTOR_SEARCHとML.DISTANCEがあるので、@graph-businessのembeddingに対するセマンティック検索も普通のJOIN/フィルタも同じクエリの中に書けます。cpgの「セマンティック検索 + ノードプロパティで絞り込み + 隣接ノードJOIN」が1クエリで完結するのが大きい。 - Graph機能がGAしたタイミングでGQL(標準のグラフクエリ言語)へ移行しやすい ── BQはすでに Graph in BigQuery をPreviewで出していて、GA後は既存テーブルにgraph viewを被せてGQLで
MATCH (n)-[e]->(m)のような問い合わせに寄せられる見込みです。今のテーブル設計のまま将来GQLに移行できるのが地味に効くポイント。
要は「専用グラフDBの強み(GQL)を将来手に入れつつ、今は普通のBQテーブルで運用できる」という、両側の利点を取りに行った形です。一般的なRAGスタック(pgvector / Pinecone等)にグラフ用のDBを足す構成と比べると、運用するシステム数も学習コストも明確に少なくて済みます。
この部分は再現可能なサンプルとして公開しました
ここまでの「JSDocアノテーションをAST解析でグラフ化する」部分は、最小構成で再現できるはずだと思ったので、動くサンプルとして公開しました:
@graph-* を抽出して、{ kind: "node", ... } / { kind: "edge", ... } のndjsonを吐くだけの、500行弱の小さなライブラリです。pnpm run example で動くサンプル付き。クローンしなくてもサンプルの出力イメージを見たい人向けに、ビルド済みのndjsonをそのままリポジトリに置いてあります → examples/sample/output.ndjson。手元で試したい方はどうぞ。
ただしこれはあくまでコードをgraph化する部分だけです。cortexの本当の価値は、ここにdocsとDBスキーマを同じグラフに乗せるところから始まります。それを次の章で。
接続 ── docsとDBを同じグラフに乗せる(cortex固有の延長)
サンプルのndjsonを眺めると、@graph-connects users [reads_from, via:id] の users はraw stringとして targetId に入っているだけです。これを「ただの文字列」のままにせず、users テーブルのカラム定義・パーティション情報・カラム単位の説明文を持ったリッチなノードとしてgraphに取り込めると、検索の解像度が一段上がります。
cortexではこれを3つの方向でやっています。
1. DBスキーマも同じグラフのノードにする
cpgはコードだけでなく、cortex内のDBスキーマも同じビルドの中で取り込んでいます。コード側から @graph-connects users [queries, via:id] と書かれた users は、ビルド時にカラム定義・パーティション・説明文付きのリッチなTableノードに解決されます(同名のstubがあれば、idを保ったまま中身が差し替わる ── エッジは壊れない)。
ここで重要なのは、テーブル/カラムの説明文はAIに後付けで書かせているのではなく、Pulumiでスキーマを定義しているファイル内の description フィールドからそのまま吸い上げているということです。Pulumi側の見た目はこんな感じ(cpg自身のテーブル定義の抜粋):
export const productGraphNodesTable = new gcp.bigquery.Table('cortex-prod-product-graph-nodes', {
datasetId: 'cortex',
tableId: 'product_graph_nodes',
description:
'Product Graph ノード — code + DB + docs を統合したナレッジグラフ。' +
'JSDoc @graph-* タグから自動生成',
schema: JSON.stringify([
{ name: 'id', type: 'STRING', mode: 'REQUIRED',
description: 'ノード一意ID(graphId:nodeType:filePath:name 形式)' },
{ name: 'nodeType', type: 'STRING', mode: 'REQUIRED',
description: 'ノード種別 — ApiEndpoint, BigQueryTable, Function, Module, Document 等' },
{ name: 'qualifiedName', type: 'STRING',
description: '完全修飾名 — filePath:exportName 形式' },
// ...
]),
});テーブル単位のdescriptionも、カラム単位のdescriptionも、Pulumiの定義そのものがそのまま意味検索のEmbedding入力になる。つまりDB側でもスキーマ定義そのものがSSoTで、cpgのJSDocと同じ思想 ── 「説明はモノが定義されている場所に書く」 ── が貫かれています。コードのJSDocを直すと意味検索が直るのと同じで、Pulumiの description を直すと意味検索が直る。
結果として、コード側からテーブルへのエッジを1ホップ辿ると、カラム定義まで含めた本物のテーブル情報にたどり着きます。
2. docsをディレクトリ規約から自動でノード化
docs/ 配下のMarkdownファイルもgraphに乗せます。仕組みはシンプルで、ディレクトリ構造を規約化することで、各docsファイルがどのstack / domainに属するかを機械的に決定できるようにしました:
docs/{category}/{name}.md例(cpg自身のdocsで言うと):
docs/product-graph/README.md→ stack:product-graph, domain:Engineeringdocs/code-graph/README.md→ stack:code-graph, domain:Engineeringdocs/mcp/db-graph/README.md→ stack:mcp-db-graph-server, domain:Engineering
このファイルをDocumentノードとしてgraphに取り込み、codeノード側の @graph-stack と一致するDocumentを見つけて**documented_by エッジを自動生成**します。たとえば apps/graph/product/ 配下のコードは @graph-stack product-graph を付けてあるので、docs/product-graph/README.md と自動でリンクされる。コードを変更すると、関連docsが自動でリンク済みになる。
これによって、たとえばAIレビュアーが「このコードを変更したけど、関連docsは古くないか?」をgraph 1ホップで確認できるようになります(Part 1で出てきた [Doc] Critical 指摘の正体がこれです)。
3. インフラ定義もノード化
infra/ 配下のPulumiコードにも @graph-* を書きます。たとえば、cortex自身のgraph関連インフラだとこんな感じ:
/**
* @graph-node {CronSchedule}
* @graph-stack code-graph
* @graph-domain Engineering
* @graph-business graph-boundary-daily: 毎日7:00 JSTにクロスリポジトリ境界分析を実行(API・DB・Event接続の自動検出)
* @graph-connects graph-index-job [triggers] Cloud Run Job起動
*/
new gcp.cloudscheduler.Job(`${prefix}-graph-boundary-schedule`, { ... });これで**CronSchedule ノード**としてgraphに取り込まれ、トリガー先の CloudRunJob ノードと triggers エッジで繋がる。Pulumiの定義そのものがgraphの入口になるので、「このcronで動いているコードはどこ?」がgraphで辿れます。
結果: 4レイヤーが1グラフに繋がる
3つの仕組みを足し合わせると、graph上に乗るノード種別はこうなります:
| ノード種別 | ソース |
|---|---|
| Function / Class / Method | コード(JSDoc) |
| ApiEndpoint / Page | コード(JSDoc @graph-node) |
| BigQueryTable / FirestoreCollection(stub) | コードの @graph-connects ターゲット |
| Table / Column / Schema(リッチ) | Pulumiで定義されたスキーマファイルをパース |
| Document | docs/ のディレクトリパーサー |
| CronSchedule / PubSubTopic / CloudRunService | infra/ のJSDoc |
エッジ種別もそれに対応:
| エッジ種別 | 役割 |
|---|---|
| calls / queries / reads_from / writes_to / publishes / triggers | code → 他ノード(@graph-connects 由来) |
| documented_by | code → Document(stack一致で自動) |
| HAS_TABLE / HAS_COLUMN | Schema → Table → Column(DB側) |
| shares_topic | 同トピックのboundaryノード間 |
コード ↔ DB ↔ docs ↔ infraが1グラフ上で1ホップで辿れる。これが「Product Graph」と呼んでいるものの正体 ── つまりcortexのナレッジグラフです。
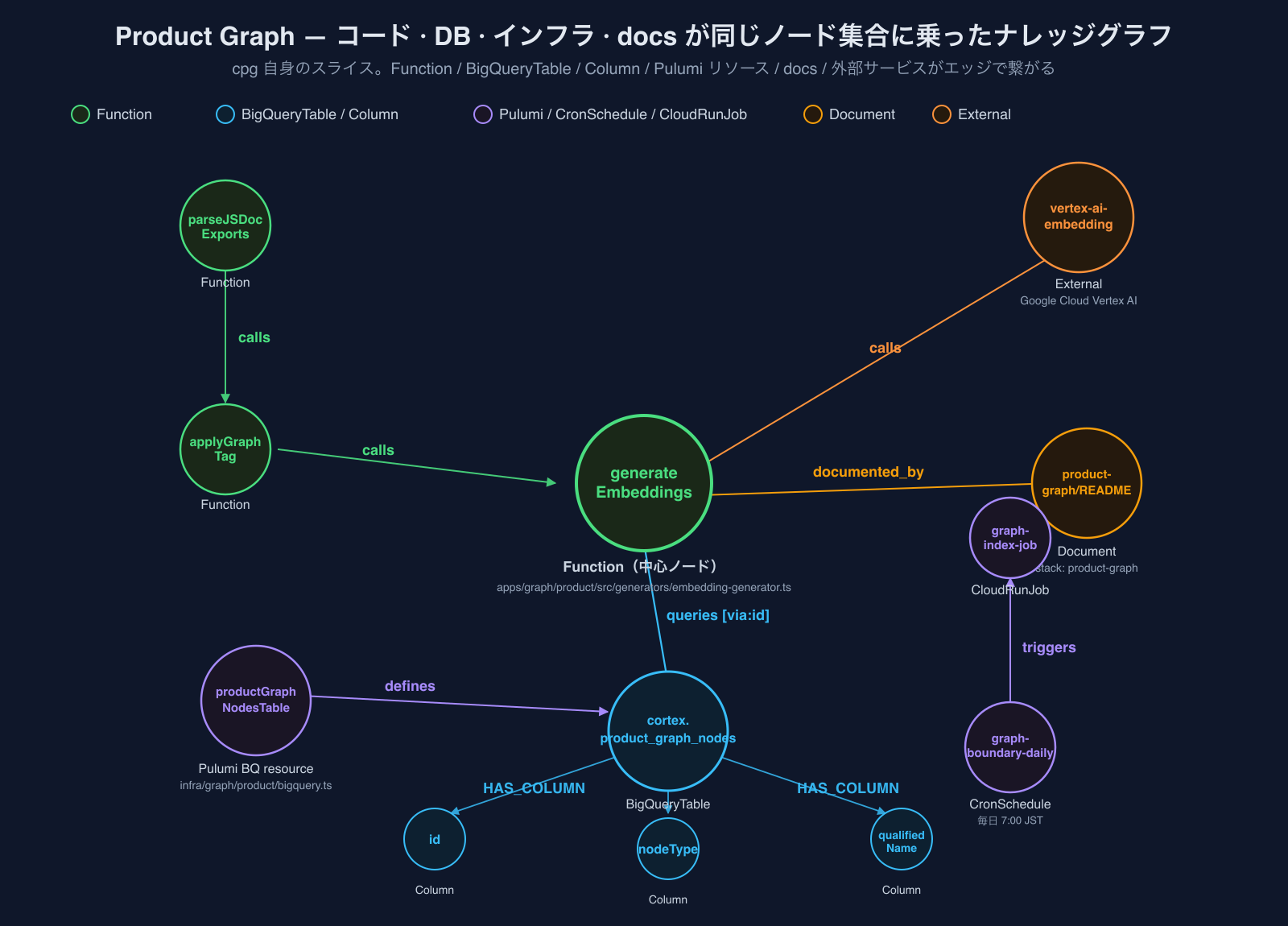
実際にcpg自身の一部を可視化したのが下図です。generateEmbeddings(コード)を中心に、cortex.product_graph_nodes(BigQueryTable)とそのカラム、Pulumiで書かれたテーブル定義リソース、docs/product-graph/README.md、Vertex AIなどの外部サービス、そして別レイヤーの graph-boundary-daily(CronSchedule)まで、全部同じノード集合の上にエッジで繋がっているのが見えると思います:
サンプルとの境界
graph-jsdoc-extractorでは意図的にここまでは入れていません:
@graph-connectsのtargetを実ノードidに解決するロジック(cortexは7段階のリゾルバーを使っているが、ルールはプロジェクトの慣例に依存する)- 同名マージ(cortexはDBスキーマ側のリッチノードでstubを昇格しているが、マージ元は各プロジェクト次第)
- docsディレクトリの規約パーサー(cortexの
docs/{category}/{name}.md規約はcortex固有) - Embedding生成(Vertex AIのセットアップは利用者次第)
これらはプロジェクトごとに正解が違う部分です。命名規則、docsの置き方、どのembeddingを使うか、stubをどこからリッチノードに昇格させるか ── どれもチームの既存資産との接続が前提になるので、サンプルライブラリ側で一つに決めてしまうとかえって使いにくくなる。なので、サンプルはJSDoc → graph化の手前までで線を引いて、その先は記事の方で「cortexではこうやった」を読んで、各自のプロジェクトに翻訳してもらう、という分担にしています。
MCPツール設計とRunbook pattern
ここまでで「グラフが組み上がる」話は終わり。次はAIがそのグラフをどう叩くかです。
cpgはMCPサーバー (cortex-product-graph) として動いていて、AIから見ると3種類のツールが見えます。これは前回のAgentic Graph RAG MCPの記事で書いた3層ツール設計(search / detail / traverse)をそのままcortexの文脈に当てはめたものです:
| ツール | 役割 |
|---|---|
search_product_graph_nodes |
進入点を探す(vector検索 + name検索) |
get_product_graph_node_detail |
IDで決定論的に詳細取得 |
trace_product_graph_connections |
BFSでサブグラフ走査(via_filter でパラメータレベル追跡) |
3層だけだと「グラフに乗っているノード」しか見えないので、グラフが指している先の実データに直接アクセスするツールも同じMCPに乗せています:
| 補助ツール | 役割 |
|---|---|
read_file |
ノードの path プロパティをそのまま渡してソース取得(Function / Class / Method / ApiEndpoint / Documentなど、コード由来のノードはどれも path を持つ) |
grep_code |
リポジトリ内パターン検索 |
git_blame |
各行の最終変更者・コミット・日時 |
query_product_graph_bq |
BigQueryを直接SQLで叩く。グラフでBQTableノードを見つけたあと、そのテーブルの実データに飛ぶ(ユーザーOAuth経由で実行されるのでBQ側のIAMがそのまま効く) |
read_firestore / write_firestore |
Firestoreコレクションの直接読み書き。グラフでFirestoreCollectionノードを見つけたあと、実ドキュメントに飛ぶ(Firestoreアクセスはユーザー / 環境のパーミッション境界に従う。cpgは入り口を提供するだけで、IAMを迂回するものではない) |
list_product_graph_stacks / list_product_graph_domains |
グラフ全体に存在するstack / domain名の一覧。検索のあたりをつける用 |
つまりcpgのMCPは「グラフで構造を辿る3層 + そこから実データ(ソースコード / BQ / Firestore)に降りる補助ツール」の二段構えになっていて、AIは「意味で探す → 構造で辿る → 実データを引く」を全部1つのMCPサーバーの中で完結できるようになっています。
Runbook pattern ── ツール返却値が次のアクションを示す
MCPのレスポンスの末尾には必ず「関連ノード(次のアクション候補)」ブロックが付きます。たとえば検索の結果が:
3件のノードが見つかりました:
- apps/generator/kpi/src/kpi-calculator.ts:calculateBugCount (Function)
- backlog_no_embedding.kpi_bug_rate_per_100pt (BigQueryTable)
- /kpi/bugs (ApiEndpoint)
## 関連ノード(次のアクション候補)
### 🛠 コード (1)
- apps/generator/kpi/src/kpi-calculator.ts:calculateBugCount → `get_product_graph_node_detail("apps/generator/kpi/src/kpi-calculator.ts:calculateBugCount")`
### 🗄 DBテーブル (1)
- backlog_no_embedding.kpi_bug_rate_per_100pt → `trace_product_graph_connections(start_node: "backlog_no_embedding.kpi_bug_rate_per_100pt", direction: "backward")`
### 🌐 API (1)
- /kpi/bugs → `get_product_graph_node_detail("/kpi/bugs")`のように、ヒットしたノード種別ごとに「次に叩くべきツール呼び出し」がコピペ可能な形で並ぶ。AIは呼ぶたびに次の選択肢が手に入るので、「次に何をすればいいか」で迷う必要がなくなります。
図にするとこの「AI ↔ MCPのループ」が一目です。MCPは検索結果に次のアクション候補を同梱して返し、AIはその中から1つを選んで次のツールを呼ぶ、を繰り返します:
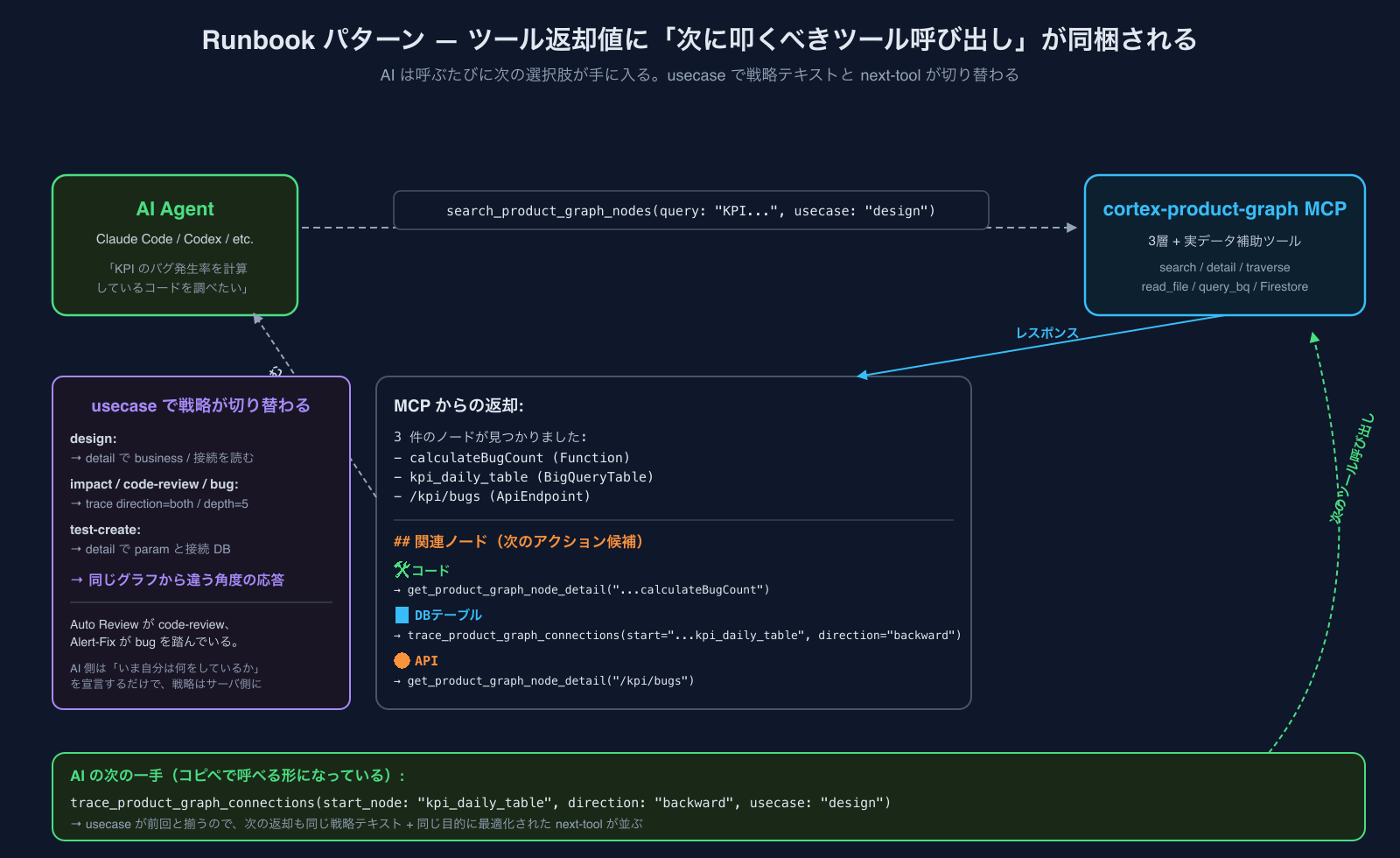
usecase パラメータでRunbookを切り替える
各ツールには**usecase パラメータ**が取れるようになっていて、AIが「いま自分は何の調査をしているか」を宣言できます:
| usecase | 戦略(cpg側で定義されている方針の要約) |
|---|---|
general |
進入点が不明な基本調査。デフォルト |
design |
既存機能の構造把握。get_product_graph_node_detail で business / 接続を読む。深いtraceは不要、Documentノードがあれば最優先 |
impact |
影響範囲を上下流とも深く追う。trace_product_graph_connections を direction=both / max_depth=5で叩く。コード + DB + インフラ + スケジュールが同じグラフ上にあるので、1走査で広範囲が見える |
test-create |
テスト設計。詳細取得でパラメータと接続DB / 呼び出し関数を読む |
test-review |
既存テストと実装の網羅率比較。対象Function / Methodの分岐構造とテスト側のcase数をクロスチェック |
code-review |
変更の影響先と @graph-business 違反検知。traceで影響先 → detailでbusiness / source確認 |
bug |
エラー起点に深く追跡。direction=both / max_depth=5で上流呼び出し元 + 下流データフローを取得 |
同じ search_product_graph_nodes でも、usecase: "code-review" で叩くと「変更の影響を確認するためのトレースを優先」、usecase: "bug" で叩くと「エラー起点に深く追跡 + ログ参照」のように、Runbookの次アクション候補が目的別に最適化されたものに切り替わります。
これが効くのは、AIに "自分が今何の調査をしているか" を宣言させることで、同じグラフから違う角度の応答が得られるからです。Auto Reviewは内部で code-review、Self-Healingは bug を投げている、という具合に、Part 1で出てきたflywheel ③ ④ がそれぞれ違うRunbookを踏んでいます。
CLAUDE.md規約 ── AIに「まずcpgを叩け」を強制する
ここまで「AIがcpgを使う」と書いてきましたが、AIが自発的にcpgを選んでくれるわけではありません。Claude Codeはデフォルトではgrep / glob / file readが手癖になっています。cortex内では、これをひっくり返すためにルートCLAUDE.mdの冒頭に以下を書いています:
Product Graph MCP (cortex-product-graph)
This is the single most important asset in this repository. cortex-product-graph MCP indexes all code, DB schemas, docs, and infra into a unified knowledge graph with business context. It knows everything about this repository.
- Always query Product Graph MCP first before grep/glob/file reads. It returns richer, contextualized results.
- If Product Graph MCP is unavailable (auth expired, server down) and you are NOT in autonomous/auto mode, stop all work immediately and ask the user to authenticate. Do not proceed with degraded grep-only investigation.
ポイントは2つあります。1つ目は「まずcpgを叩け、grepは見つからなかった場合の補完」と順番を強制していること。2つ目は「cpgが落ちている/認証切れの場合は全作業を即停止して認証を要求」と、grepへのフォールバックを禁じていること。これがないと、AIは「cpgが調子悪いからgrepで頑張るか」と勝手にデグレード調査を始めて、結果として古い情報・誤った文脈で実装やレビューを進めてしまう。
この一行があるだけで、Claude Codeはコード調査の第一手をcpgに固定します。記事執筆も、Auto Reviewも、Self-Healingも、同じ規約を踏むので、入口が全部cpgに揃う。
実例 ── cpgをcpgで調べる
抽象論ばかりだと退屈なので、実際にcpgを叩いた結果をひとつ載せます。せっかくなので、この記事で書いているcpgそのもののビルダー本体を、cpgで調べるメタな例にします。
Step 1: 「コードの注釈からグラフのもとデータを取り出す処理」をセマンティック検索
実装の関数名を知らない前提で、やりたいことだけ自然言語で投げてみます。
search_product_graph_nodes(
query: "コードに書かれている注釈から、グラフのもとデータを取り出す処理",
search_mode: "semantic",
usecase: "design"
)返ってきたノード(上位5件):
- apps/graph/product/src/parsers/jsdoc-parser.ts:applyGraphTag (Function)
- apps/graph/product/src/parsers/jsdoc-parser.ts:extractTagsFromNode (Function)
- packages/eslint-plugin-graph/src/utils/jsdoc-utils.ts:extractGraphTags (Function)
- apps/graph/product/src/parsers/jsdoc-parser.ts:parseJSDocExports (Function)
- packages/eslint-plugin-graph/src/utils/jsdoc-utils.ts:getGraphTagValue (Function)クエリには「JSDoc」も「@graph-*」も「パーサー」も入れていないのに、@graph-business の埋め込み経由で意図が伝わってヒットしています。grepでは絶対に引けない引き方。
Step 2: そのノードから下流をトレース(usecase: "design" でDocumentを優先)
trace_product_graph_connections(
start_node: "apps/graph/product/src/parsers/jsdoc-parser.ts:parseJSDocExports",
direction: "forward",
usecase: "design"
)返ってくるエッジ:
- parseJSDocExports --calls--> extractDeclarationsFromFile
- parseJSDocExports --calls--> extractTagsFromNode
- parseJSDocExports --reads_from[via:filePath]--> filesystem
- parseJSDocExports --documented_by--> docs/product-graph/README.md (Document)最後の documented_by が効きどころで、コードからDocumentノードへのエッジが自動で生成されていることが見えます。docs/product-graph/README.md を read_file で読みに行けば、この実装の背景・設計判断・タグ仕様まで一気に取れる。
Step 3: この記事自体がcpgで書かれているというメタ構造
ちなみにこの記事、文章を起こしているのは私ではなくClaude Codeで、私は方針出しとレビューだけをしています。そのClaude Codeにはcpg MCPが接続されていて、私が「ここはcpg自身のコードで例示して」「インフラ例もcpg関連で」と指示するたびに、Claudeはcpgを叩いて実物の関数名・JSDoc・Pulumi定義・docs構造を取りに行き、それを記事に落としています。
つまりこの記事に出てくる generateEmbeddings のJSDoc、Pulumi productGraphNodesTable のdescription、graph-boundary-daily のcronアノテーション、docs/product-graph/README.md への自動リンク ── どれも私が記憶を頼りに書いたものではなく、Claudeがcpgに問い合わせて引き当てた実物です。私が見ているのは「これは正しい / これは違う」というレビュー側の判断だけ。
これがcortex全体で繰り返し起きているパターンです。「人間が方針を出し、AIがcpgで裏を取って実装/文章/レビューを生成する」。Part 1の③ Auto Reviewも、④ Self-Healingも、同じ構造で動いています。記事の執筆だけが特別なわけではなく、cpgがある限り、AIが触る作業はぜんぶこの形になる。
何が変わったか / Part 3への橋渡し
ここまでが「cortex内部のcpg」の話でした。最後に、これがcortex全体にどう効いているかをまとめます。
1. 自分がgrepを打たなくなった
ファイル名やシンボル名を知らなくても、「やりたいこと」を自然言語で投げれば該当コードが返ってくる。コードベースの大きさ(apps 120+)と1人体制の組み合わせが成立しているのは、これが一番大きいです。
2. Auto Reviewが「文脈を踏まえた指摘」になっている
Part 1の③ Auto Reviewが出している [Graph] [Impact] [Doc] [Security] 級の指摘は、すべてcpgの上に立っています。コードベース全体を文脈として保ったうえでのレビューが出るのが、Auto Reviewの本質的な効きどころ。
3. Self-Healingがエラー起点から原因まで辿れる
Part 1の④ Self-Healingが、Grafanaアラート → コード → 依存テーブル → 関連docsを1ホップで辿れるのは、cpgがあるから。usecase: "bug" を踏んで、エラーから根本原因までの最短経路を取りに行きます。
4. 静的解析のcode-graphは別の場所で活きている
冒頭で「コードからの推論を捨てた」と書きましたが、それはcortex自身に対しての話です。社外向けの本番リポジトリ群(事業の中核アプリ)側では、別の方法でコンテキストを持たせて引き続き使っています。詳細はまた別の機会に。
大半のAIコーディング基盤は「変わらないrepoをAIに頑張って読ませる」方向で進化していますが、cpgは逆です。repo自体をAIが読む前提の情報構造に作り変える。これがcpgが「単なるGraphRAG」とは別物である根本的な理由です。
その意味でProduct Graphは文字通り「AIのAIによるAIのためのナレッジグラフ」です。AIが書いたコードと一緒に生成され、AIレビューで維持され、AIエージェントがプロダクトを理解するための地図として使われる。
次回**Part 3 ── 自動PRレビュー**では、cpgの上に立っている自動PRレビューの全フロー ── GitHub webhookの受信から、AIレビュー / 自動修正 / 自動merge / 並列デプロイまでを取り扱います。Auto Reviewが usecase: "code-review" を踏むときに何が起きているか、[Graph] Critical 指摘がどう生成されているか、worktreeでAIが修正をかけてpushし直す仕組みなどを書いています。
comments (0)
まだコメントはありません。