みなさまこんにちは!エアークローゼットでCTOをしている辻です。
Part 1(総論)で、cortexのハーネスが組み上がってきた結果、エンジニアではないメンバー(事業サイドのマネージャー、PMOなど)も本番リポジトリにPRを出せるようになってきた話を書きました。ここで言うハーネスはAIを本番で動かすための土台で、Part 1-4で順に解説してきたナレッジグラフ / Auto Review / Self-Healing / 再発防止の組み合わせのことです。
Part 5はその続きで、そのハーネスが「誰が書くか」のレイヤーまで波及している話です。
「いやでも、品質をAIレビューに任せきって本当に大丈夫なのか」「結局エンジニアが事後にチェックしているんでしょう」と思う読者が多いはずなので、本記事はまず実例を1つ詳細に見せるところから始めます。
Part 5では、
- どんなPRが実際にマージされているか(代表的な2件の中身を具体に)
- 何ができて、何ができないか(既存のアプリの土台(stack)の上に乗せる作業と、stackを立ち上げる仕事の境界線)
- なぜ非エンジニアでもこれが成立するのか(Part 1-4で積み上げてきた仕組みとの関係)
- その先 ── cortexを超えて本番toCサービスへ(サービス側ナレッジグラフ構想 + 品質水準の違い)
を実例ベースで整理します。詳細なtoCスケール側の実装話は別記事に切り出す予定なので、本記事では構想と方向感まで。
連載一覧
| # | テーマ | キーシーン | 記事 |
|---|---|---|---|
| 1 | 総論:cortexのハーネス | PRが無人マージ / 障害が気づく前に治っている | ai-harness-intro |
| 2 | Product Graph (cpg) | コード・ドキュメント・DB・インフラを1グラフに統合 | cortex-product-graph |
| 3 | AI PRレビュー | webhook → AIレビュー → 自動修正 → squash merge | cortex-auto-review |
| 4 | Self-Healing + Observability + 自動lint追加 | アラート → AI調査 → 修正PR + 新規lint/型gate → 自動再デプロイで同じ書き方を機械的に弾く | cortex-self-healing |
| 5 | 改修フェーズの民主化 | 業務要件を把握している人が本番に直接PR、ハーネスが品質を担保 | 本記事 ←現在地 |
| 6 | 連載総括・最終章 | 根底にある思想(何を捨てて何を取ったか / なぜこの設計か)と失敗の振り返り | cortex-philosophy |
いきなり1つのシーンから
社内ダッシュボードのWebアプリに +1,742行 / 41ファイル のPRが立ちます。タイトルは「PL dashboard ver.2」。内容は、複数部門のマネージャー / チームリーダーが自部門・自チームの案件をスコープに絞って閲覧できる機能の追加。共有型定義パッケージへのSSoT追加、APIサーバー側の新ルート + SQL(INNER JOIN + LEFT JOIN)、Webアプリ側の新ページ + 表示制御 + 個人設定 ── ひと通り入っています。
注目してほしいのは、これが「タイポ修正」でも「文字列の差し替え」でもない、ということ。entity / repository / APIルート / 画面 / フィルタ / 個人設定 ── 普通の機能追加で触る層は一通り触っています。スケール感としては1人のエンジニアが数日かけて書くサイズのPR。
レビュー往復はこんな感じで進みます。
- PR open(+1,742 / 41 files)
- auto-review 1回目: Major指摘(権限スコープのfall-through ── 自部門以外の不要な情報まで見えてしまう経路)+ Minor数件
- author bot修正push: scope fall-throughを塞ぐ + Minor対応
- auto-review 2回目: Nit残り、追加でlint (
no-empty-function)を発見 - author bot修正push: lintも解消
- auto-review 3回目: まだ細部にCOMMENTED(まだAPPROVEしない)
- author bot修正push(iteration 2): loading skeletonの強化 + 不要だったJSDoc修正のrevert
- auto-review 4回目: APPROVED → CI green + APPROVEが揃った瞬間にauto-merge → 本番反映
PR openからmergeまで レビュー往復4回 / 修正push 3回、その間に人間レビュアーは1人も介入していません。レビューは全部AI(auto-review bot)、修正はPR作者が起動している自動レビュー対応エージェント(author bot)が対応、最終的にAIがAPPROVEをsubmitしてauto-mergeスクリプトが拾ってmerge → デプロイ。テストは共有型定義パッケージ(Type SSoT)56/56・API 2,284/2,284・Web 1,113/1,113・lint 0 errorsの状態で本番反映しています(cortexでは汎用検査をoxlint、@graph-* 等の独自ルールをeslintのcustom pluginで分担しています)。
特に2番目のレビューで返ってきた指摘 ── 「scopeのfall-through」── はやや専門的で、権限スコープに穴があって自部門以外のデータまで見えてしまうという問題でした。社内ダッシュボードなので外部漏洩のインシデントではないですが、「必要なものだけ見える」が成立しないと不要な情報がノイズになってツールの価値が落ちるので、これも品質ゲートで弾く対象です。これを初回レビューで自動的に検出して、PR作者側に修正を要求できているのが、ここで起きていることの本質に近い。非エンジニアがコードを書いても、AIレビューがMajor級の指摘を返して直させる ── この往復が回ってないと、ここまでのスケールのPRを非エンジニアに任せるのは無理筋です。
そして、このPRの作者はエンジニアではない。事業サイドのメンバーがClaude Codeに「こういう画面を作りたい」と要件を渡して、社内ナレッジグラフ(Part 2参照)で関連コードを取得しながら、+1,742行の機能を実装した結果が、上の4往復です。
これが本記事の主旨につながります ── 業務要件を一番把握している人が、要件を整理してエンジニアに依頼するのではなく、自分でClaude Codeを使って本番まで通す。
念のため言葉の定義を一つ置いておきます。本記事で「書く」と言うとき、それはエディタで1行ずつタイプする意味ではありません。業務要件をClaude Codeに渡し、出てきたコード差分とAIレビューの指摘を業務知識で判断しながら、本番マージまで持っていく行為を指しています。実際の差分の大半はClaude Codeが書きますし、レビュー対応もauthor botが応える。人間が担うのは「何を作りたいか言語化する」「途中の判断(この機能でよいか / ここは違う)を業務知識で下す」「最終的にmergeできる状態かを認める」── この3つで、技術的な実装作業ではない、という意味で「書く」と呼んでいます。
もちろんClaude Codeへの指示の出し方や、どこから情報を引いてくるかには多少の慣れが必要ですが、プログラミングを覚える必要は無い ── 必要なのは「何を作りたいかを言語化する力」であって、syntaxやフレームワークの知識ではありません。
そのうえで品質はハーネスが担保するので、+1,742行 / 41ファイルの規模でも成立している、というのが上のシーンです。
必要になったタイミングで、自分で直せる
本記事で言いたいのは、
必要になったタイミングで、必要な修正をエンジニアに依頼せずに自分でできる
という能力が業務側に成立した、ということです。これが成立すると、
- ダッシュボードに新しい指標を足したい
- 集計の絞り込み条件が業務実態と合っていない
- 自分用の業務支援機能を本番アプリの一部として欲しい
といった業務側で発生する細かな要求が、エンジニアの優先順位待ち行列に詰まらず、その場で解決される。
従来の動線を思い出してみてください。業務側にちょっとした修正の必要が生じたとき、まず誰かが要件をテキストに起こして、エンジニアにSlackやチケットで依頼します。エンジニア側は他の本筋タスクの合間で見る必要があるので、優先順位の中で何日か待たされる。実装が始まっても要件の解釈が業務の認識とズレていて差し戻しが入り、レビューが入って、最終的に本番にデプロイされるまで、ちょっとした修正でも実時間で数日から1週間程度かかる、というのが普通でした。
これは業務理解とコードの間に翻訳レイヤーが挟まるから起きていることで、しかもエンジニアの本筋タスクが詰まっているほどこの遅延は長くなります。事業側の改善サイクルが、エンジニアの忙しさに左右される構造になっていた、と言い換えてもいい。
業務要件を把握している人が自分で書けるようになると、上の翻訳レイヤーと待ち行列が丸ごと消えます。
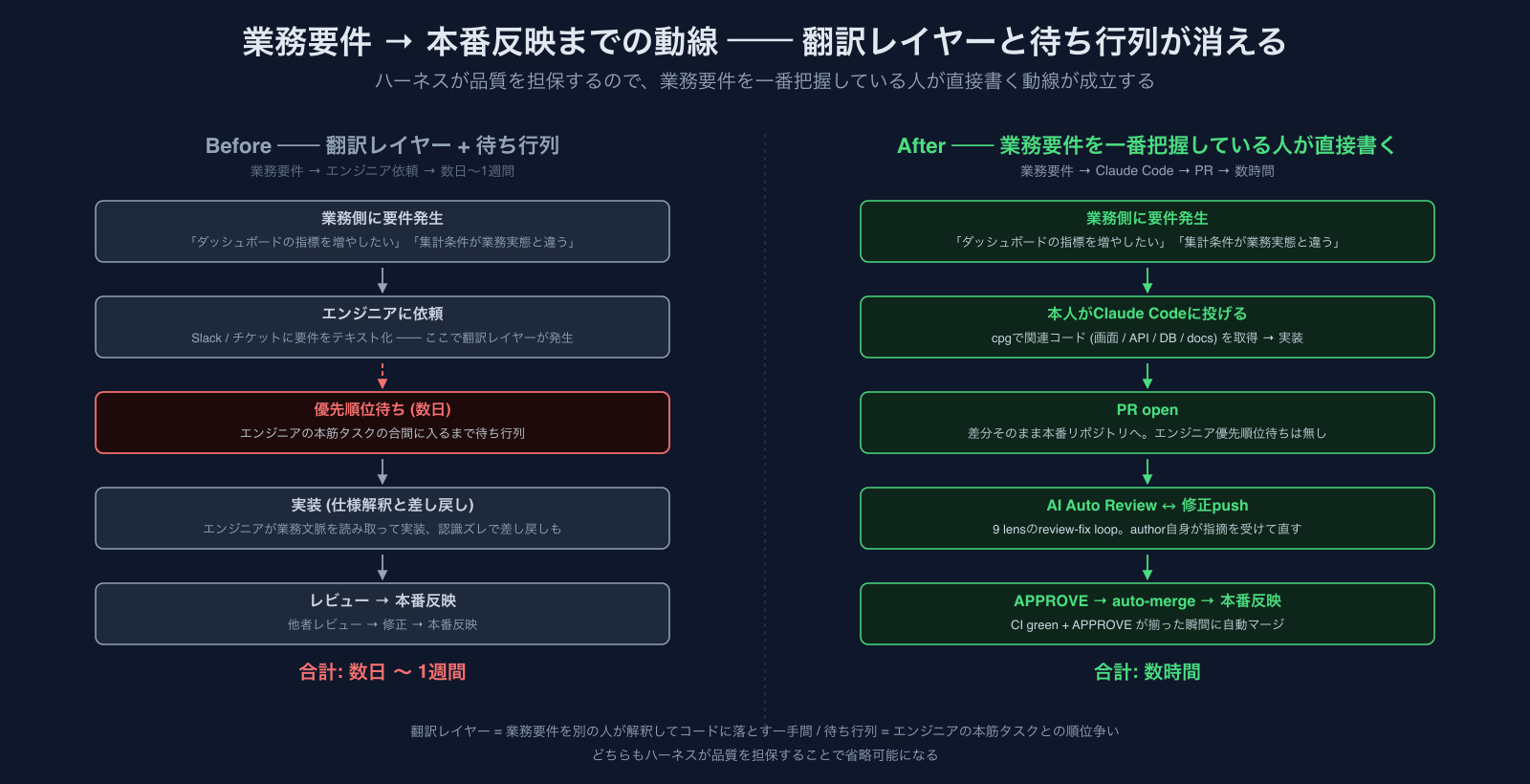
以下、その能力が成立している実例を見ていきます。
実際にマージされた非エンジニアPR ── 代表的な2件
| PR | 種別 | 規模 | 内容 |
|---|---|---|---|
| PR① | バグ修正(深い) | +348 -177 / 7 files | ダッシュボードの実績数値が目標を不当に超える問題を修正。原因は集計対象チームの定義が目標側と実績側で非対称だったことで、対象チームの共通リストを新規ファイルに切り出して両側を揃えた。testも併せて追加 |
| PR② | 既存stackへの大型追加 | +1,742 -227 / 41 files | 冒頭シーンで取り上げたPLダッシュボードv2。API + UI + entity + repositoryまで一通り実装、ただしWebアプリ自体(stack)は既存で、その上に重ねた追加 |
性質が違う2件 ── 一方はデータ整合性に対する深い修正、もう一方は1,742行追加の大型機能実装。どちらも非エンジニアが書いてmergeまで持っていったPRです。
PR① ── 深い根本原因修正
「数字がおかしい」という事業側の気づきから、データ整合性レベルの根本原因に降りていったPRです。表面的な現象は「ダッシュボードの実績数値が目標を不当に超えていて、達成判定が誤って101%と表示される」。普通なら数字を合わせる係数を足してお茶を濁すか、表示側でクランプするかで済ませてしまいそうな話です。
ところがPR作者は集計クエリまで掘っていって、根本原因を以下のように特定しました。実績側の集計と目標側の集計が別のテーブルを参照していて、「どのチームを集計対象にするか」の定義が非対称になっていた。目標値を持たないチーム(デザイナー / PMO等)は目標側の集計には出てこないのに、実績側には算入されていたため、実績だけが分子に乗って目標を超過していたわけです。
修正は症状ではなく構造のほうに当てています。「集計対象とするチームの共通リスト」を1ファイルに切り出して、目標側も実績側も同じリストを参照するように直しました。今後同じ非対称を組まないよう、共通定数経由で縛るところまでやっています。
集計に乗らないデータの扱いと、目標 / 実績の対称性 ── これはエンジニアでも見落としやすい論点です。それを非エンジニアが根本原因まで降りて構造レベルで直しているのが、このPRの特徴です。
PR② ── 既存stack上の大型機能実装
冒頭シーンで詳しく取り上げたPRです。+1,742行 / 41ファイル / entity / repository / API / UIまで揃った機能追加で、一般的な「改修」イメージよりはるかに強いスケール感です。
ただし重要なのは、Webアプリ自体(stack)は既に立っていること。新しいアプリを立ち上げるのではなく、既存の社内ダッシュボードに「PLダッシュボードv2」という新しい機能を1つ足している、という位置取りです。Pulumi / Cloud Run / Dockerfileに手を入れる必要は無く、新しい依存パッケージを追加する必要も無く、既存ディレクトリ構造の中で、新しいルートとページを追加して既存のrepository patternに乗せただけ。
このstackの上に乗せる範疇に収まっているからこそ、非エンジニアでも書ける。「改修」と呼んでいるのは、こういう位置取りに収まっていることを言いたいからです。次節で線引きをきれいに整理します。
補足: 本記事で「改修」と呼んでいるのは、一般的な「既存ロジックの細かい修正」よりかなり強い範囲を指します。新しいentity / 新しいendpoint / 新しいページの追加までこちらに含めていて、stackを立ち上げる作業との対比で線を引いています。
何ができて、何ができないか
線引きの原則: stackの追加は難しい / stackがあれば追加はできる
非エンジニア開発の境界線は「改修vs新規」よりも、「既存stackの上に乗せる作業か / 新規stackを立ち上げる作業か」で引いた方が実態に近い。
- 新規stackを立ち上げる(= インフラから構築する必要がある仕事。例: 新しいWebアプリを1つ立ち上げる / 新規でCloud Run等をDockerfileから定義する / 新しいBigQuery pipelineを1から組む)→ エンジニアの仕事
- 既存stackに追加する(= 既にあるアプリに新しいページを作る / 既存APIにendpointを足す / 既存pipelineに新しいデータ取得を加える)→ 非エンジニアでも可能
直前で見た2件は両方とも 既存stackの上に乗せる作業 に収まっています。stackそのものは既に自分が作ってあるものなので、その内側で動ける。逆にstackを0から立ち上げる側は今のところ非エンジニアが触っていない領域です。
別の言い方をすると、「家が建っている上での内装変更や部屋追加」は非エンジニア可、「家自体を建てる」はエンジニアです。家の構造(柱や梁の配置、配線、配管)が間違っていると後から取り返しがつかないのと同じで、stackの設計には事故の波及範囲が大きい判断が含まれていて、ここはまだAIに任せきれていません。
エンジニアが残るのは「レールを敷く側」── stack立ち上げと、ハーネス自体の整備
逆に言うと、レールを敷く側 ── stackを立ち上げる作業と、ハーネス自体を設計・拡張する作業 ── は今のところ非エンジニアが触っていない領域です。どちらも、そこには別領域の知識が要るからです。
- インフラ知識: コンテナ / IaC / クラウドサービスの構成や運用の常識。Cloud Runのリソース上限、コールドスタート、Pub/Subのat-least-once保証、BigQueryのpartition / cluster設計、Pulumiでのスタック分割 ── このあたりを把握しないと、たとえ動くものを作っても、本番の負荷や障害耐性で破綻します
- 外部と接続する認証の設計: OAuth / webhook / APIキーの取り回しと、それをSecret Manager等にどう寄せるか。1ヶ所間違えると認証情報がリポジトリに混入したり、webhookで意図しないコマンドが発火したりする領域です
- セキュリティの常識: 何を露出させない / どこでサニタイズする / どの境界で権限を切る、を間違えると本番事故になる領域。SQLインジェクション、XSS、SSRF、認可漏れ ── このあたりは「動くからOK」では済まない部分です
- ハーネス自体の設計・拡張: Auto Reviewの観点を増やす / Self-Healingのロジックを変える / 新しいlint rule(
eslint-plugin-graph等)を作る / ガイドラインの構造設計。フライホイール全体がどう繋がっているかを把握した上での判断が要る、最もメタな仕事
最後の「ハーネス自体の設計・拡張」は地味に重要な含意があって、非エンジニアが本番にPRを出せる状態を維持し続けるためには、誰かがハーネスを進化させ続けないといけない。Part 4で書いた再発防止のループは罠ごとにlint / CI guard / ガイドラインを増やす自動運動でしたが、ハーネスそのもののアーキテクチャ ── 観点の構成 / 9観点の判定基準 / Self-Healingのフロー設計 / ナレッジグラフの構造 ── は別のメタ層で、ここはエンジニアの判断が要る。
具体例で言うと、いま9つあるAuto Reviewの観点([Graph] / [Architecture] / [Security] / [Test] / [Doc] / [Impact] / [Observability] / [AI-Antipattern] / [Recurrence])の枠組み自体は、過去の事故と修正パターンを観察した結果として誰かが設計したものです。10個目の観点が必要になったとき ── 例えば「依存パッケージのアップグレード時のbreaking changeチェック」のような新軸が必要になったとき ── 既存の観点との責務分担をどう切るか、判定の閾値をどう決めるか、というのはハーネス全体の構造を見ながらの判断になります。これがエンジニアの残された仕事の代表例です。
ハーネスが提供しているのは「逸脱しないレール」であって、レール自体を敷く仕事 ── インフラを立てる側も、レール(= ハーネス)そのものを設計する側も ── は別の仕事として残ります。レールを敷くのはエンジニア / レールの上を走るのは誰でもできる ── これが現状の境界線です。
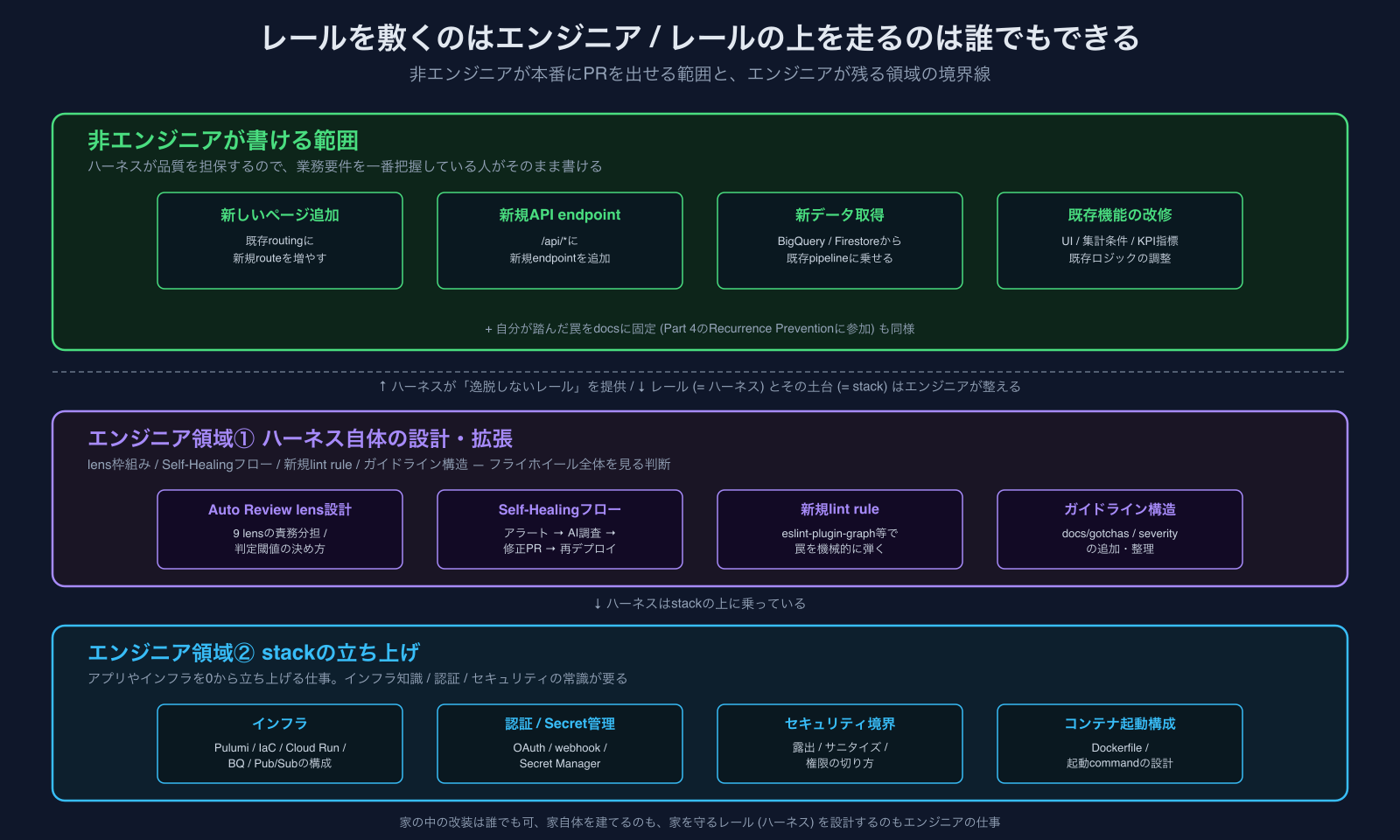
なぜ非エンジニアでも本番にPRが出せるのか
ここはPart 1-4で書いた要素がそのまま効いてくるので、復習として簡潔にまとめます。4つの仕組みが互いに強化し合うフライホイールになっているから、非エンジニアでも既存stackの上で安全に手を入れられる、というのが結論です。
① ナレッジグラフが「やりたいこと」から関連コードを引いてくれる
Part 2で書いたコード・ドキュメント・DBスキーマ・インフラ定義を1つに統合したナレッジグラフ(実装名
)がここで効きます。非エンジニアが関数名やリポジトリ構造を知らなくても、自然言語で「ダッシュボードの指標カラムを増やしたい」とClaude Codeに投げれば、ナレッジグラフがセマンティック検索で関連ノード(画面 / API / DB / docs)を1〜2ホップで取得します。技術用語を知らなくても入口に立てるのが大きい。
冒頭シーンのPR②を例にすると、PR作者は「PLダッシュボードv2で、PMO / チームリーダーが自部門・自チームの案件を絞って見られるようにしたい」という要件をClaude Codeに投げて、ナレッジグラフが既存の/projectsルート、project-repository.ts、FilterHeaders.tsx、ProjectTable.tsxといった関連ノードを引いてきています。PR作者は「どのファイルを編集すべきか」を最初から知っている必要が無い。これが翻訳レイヤーを抜く土台になっています。
② Auto Reviewが品質を機械的に強制する
Part 3で書いた9観点の自動レビューが次の層です。[Graph] / [Architecture] / [Security] / [Test] / [Doc] / [Impact] / [Observability] / [AI-Antipattern] / [Recurrence]の9つの観点で漏れをREQUEST_CHANGESとして返し、author botが直すまでループする ── 冒頭シーンの4往復がその実例です。
ここの含意は「初回PRで完璧である必要がない」こと。PR作者は最初からセキュリティ穴を埋めた完成形を書く必要が無く、初回PRさえ出せばあとは自動レビューとauthor botの往復で仕上がります。author botが指摘の解釈を誤って「無限に直し続ける」ような迷走に陥らないのは、ナレッジグラフがコードベース全体のコンテキストを保持していて、修正範囲を構造で把握した上で対応できる設計になっているからです。
③ Self-Healingが事故ったときの後処理を持つ
Part 4で書いたSelf-Healingが3つ目の層です。
万が一productionで異常が出ても、AIがアラートを起点に原因調査 → 修正PR → 自動再デプロイで完結します。非エンジニアが踏んだ事故も人手を介さず復旧できるので、本番にPRを出す心理的ハードルが大きく下がる。
これは「非エンジニアでも書けるから安全だ」という主張ではなく、「書いた後に何か起きてもハーネスが拾う」という事後の安全網があることが、入口を広げられる前提になっている、という話です。失敗の可能性をゼロにする方向ではなく、失敗してもダメージを最小化する方向で設計してある。Part 4の3層構造(Observation → Repair → Strengthening)が、この事後安全網の中身です。
④ 再発防止のループで罠が増えない
最後に、Part 4の後半で書いた再発防止のループ。
一度踏んだ罠は同じPRの中で固定化されるので、次に同じパターンを書こうとしても弾かれる。固定化の手段はパターン次第で、機械的に判定できるものはlint / CI guard、機械化が難しいものはガイドライン文書(docs/gotchas やseverity文書)に書いてAIレビュアーが拾う ── どちらの形でもmerge前に検出されます。非エンジニア自身も、自分が踏んだ罠をdocsに追記する形でこのループに参加できる構造になっています。
これが効いてくると、ハーネスのレールは時間とともに細かくなる。最初は「ここを通っちゃダメ」という大まかな線しか無かったところに、事故を踏むたびに「ここも、ここも、ここも」と細い線が追加されていって、結果として「迷い込みにくいレール」ができていく。非エンジニアにとっては、レールの密度が高いほど安全に走れる ── という構造になっています。
→ この4つは独立したパーツではなく、互いの出力が互いの入力になる設計です。Part 1のGuides + Sensorsのフライホイールの話そのまま。詳細はそれぞれの記事に書いてあるので深入りしませんが、非エンジニアが本番にPRを出せている現象は、この4輪が同時に回っているから初めて成立しています。1つでも欠けると、書く側に求められる前提知識が一気に増えて、すぐに崩れます。
その先 ── cortexの外へ、本番toCサービスへ
cortexは社内AI基盤なので、ここまでの仕組みは本番toCサービスにそのままは持ち込めません。最大の論点は品質基準の違いです ── toCはユーザー影響が出てから検知 → Self-Healingで修復、では遅すぎる。事故が起きないこと、起きるとしても事前に検証とレビューが済んだ状態で人間がsign-offしていることが要件になります。
ただ、ハーネスの型 ── ナレッジグラフでコンテキストを揃え、9観点AIレビューを通し、author botが指摘に応える ── は同じ構造で持ち込めます。違うのは最終ステップだけで、cortexのauto-mergeを「AI下準備 + 人間sign-off」に変形する。AIに任せる範囲を縮めるのではなく、AIが前段(テスト作成 / テスト環境構築 / テスト実行 / 9観点レビュー)を整え終わった上で、人間が最終APPROVEを押す形にすればいい。「人間がsign-offするならエンジニア時間は減らないのでは」と思われるかもしれませんが、従来エンジニアが時間を使っていた「実装 + テスト書き + 環境準備 + 自己レビュー + 他者レビュー対応」のうちsign-offは最後の小さな部分。AIが前段の大半を担う分だけ、エンジニアの仕事の中身は実装作業から品質判断側にシフトします。
なお、コンテキスト解決のためにナレッジグラフを必要とするのはコードベースが大規模になってからです。AIが1コンテキストにコード全体を読めるサイズなら横断グラフは不要で、cortex (100+ apps)や本番toC (40+ repos)のスケールだからこそ効く話です。
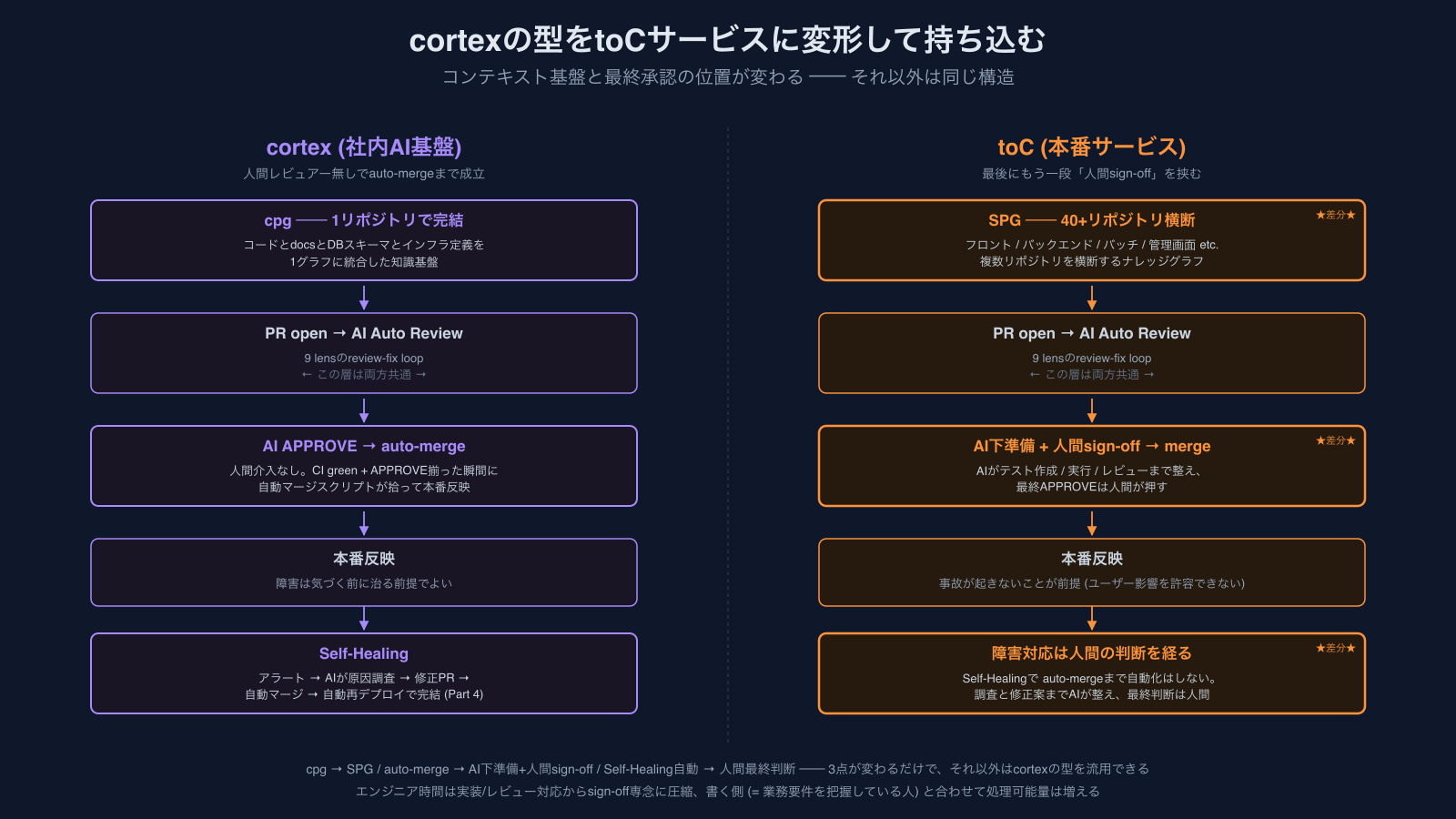
具体的な構想は進めていて(cortexのナレッジグラフをtoC側40+リポジトリに横断展開する、AI下準備のフロー設計、等)、詳細は別記事を切る予定です。
まとめ
- 業務要件を一番把握している人が、要件を整理してエンジニアに依頼するのではなく、自分でそのまま書く。品質はハーネスが担保するので、書く側に求められるのは業務理解とAIに投げる力で足りる。結果、業務側の細かな要求がエンジニア待ち行列に詰まらず事業速度が上がる
- それを支えているのはPart 1-4の4つの仕組み(ナレッジグラフ / Auto Review / Self-Healing / 再発防止)のフライホイール。初回PRで完璧である必要がなく、間違っても勝手に直る設計
- 境界線は「レールを敷くのはエンジニア / レールの上を走るのは誰でもできる」。インフラ / 認証 / セキュリティを要するstackの立ち上げ、それからハーネス自体の設計・拡張(lint ruleの追加 / Auto Reviewの観点設計 / Self-Healingのフロー改善 等)は依然エンジニアの仕事
- この型を本番toCサービスに広げる場合、コンテキストはサービス側のナレッジグラフ(40+リポジトリ横断)で解決できるが、品質水準が違うのでauto-mergeではなく「AI下準備 + 人間sign-off」に変形して持ち込む。詳細は別記事
次回 Part 6 は連載全体の総括です。中心はそもそもどういう思想でこれをやっているのか ── 何を捨てて何を取ったか、なぜこういう設計を選んでいるのか、という土台の話。あわせて、ここまでの記事では「うまく回っている結果」を中心に書いてきたので、その裏で踏んできた失敗・つまずきも振り返って、思想と実装のあいだのギャップも整理したい。自分自身の振り返りでもあり、同じようなことを始めようとしている人にとっての参考にもなれば、と考えています。
comments (32)
the harness as guardrail is what makes non-engineer PRs viable. without it you're just hoping. curious what breaks first when a PMO touches a prompt that's load-bearing for 3+ workflows downstream.
The scenario shouldn't be reachable by design — load-bearing prompts (Auto Review dimension prompts, Self-Healing triage prompts, etc.) live in the "harness itself" layer, not the "build on top of the harness" layer that non-engineer PRs operate in. Same boundary as the post (stack vs. on top of), applied at the prompt layer. If a PR did cross that line, the Auto Review's impact dimension would catch it via the knowledge graph — it traces the prompt's downstream usage and refuses the merge until a human design review approves the change to the harness layer itself.
the knowledge graph tracing impact is the part that operationalizes the boundary - you can't rely on convention when non-engineers are authoring. Auto Review blocking a merge that crosses layer boundaries is the right enforcement mechanism, not documentation and code review.
Right — and the dependency on the knowledge graph here goes deeper than enforcement. Without it, you can't even tell whether a given prompt is load-bearing across multiple workflows in the first place. Convention-based review (docs + human eyes) collapses well before the prompt layer; nobody can hold "this prompt feeds three downstream workflows" in their head reliably. The graph is what makes "load-bearing" a checkable property at all, and the enforcement (Auto Review blocking on impact) just rides on top of that. Without the graph, there's nothing for the gate to check.
yeah load-bearing prompt detection is the right frame - a prompt feeding three workflows looks identical to an isolated one until something breaks. the graph surfaces that dependency before it becomes a production incident. without it you are doing blast radius analysis by memory, which does not scale past 5 workflows.
Right — "looks identical until it breaks" is exactly the failure mode that makes convention-based review useless at scale. The 5-workflow ceiling matches what I've seen too; once a codebase has more than a handful of cross-references between prompts and downstream consumers, nobody can hold the dependency graph in their head, and blast radius decisions degrade from "informed" to "guessed." Surfacing it before incident is the part that turns the graph from a debugging tool into a gating mechanism — it stops being something you query after the fact and starts being something the merge can't proceed without.
nobody can hold that graph mentally past 5-6 connections - it collapses the same way any undocumented API dependency graph does. explicit tooling is the only fix that scales.
Agreed — "any undocumented API dependency graph" is a useful generalization. Explicit tooling at the gate is the only fix that holds across that class.
right, though a static gate only covers known topology — agents hit new tool connections mid-run that weren't visible at entry. gate + runtime check is the full pattern, not just gate.
This works when the harness turns intent into reviewable structure. A non-engineer can author a change, but the system still needs hard gates around tests, ownership, and risky surfaces. Otherwise “anyone can author” becomes “no one owns the failure.”
Exactly the right framing. The harness in cortex separates authorship from failure ownership: anyone (PMO included) can author the change, but the failure ownership sits at the system layer, not the PR layer. PR-level correctness is owned by Auto Review + the test / lint gates you mentioned. System-level reliability — "did this keep running in production" — is owned by the engineers who designed the harness, backed by Self-Healing for routine fixes and human escalation for what Self-Healing can't crack. "Anyone can author" only works because "someone owns the system" is true one layer up.
Exactly. "Anyone can author" only works when ownership moves to the right layer. The harness can let more people express intent, but the system still needs clear engineering ownership for reliability, gates, escalation, and production behavior. Otherwise low-code authorship becomes unowned execution, which is where the risk shows up.
Agreed, and that's the exact architecture the post describes. Ownership never moves away from engineering here. Engineers own the harness, the infrastructure, and the failure path, and the only thing that moved to non-engineers is authorship on top of those rails. So when an authored change misbehaves in production, that's not the author's failure, it's a hole in the harness, which means it's an engineering failure. "Unowned execution" is precisely the state the whole design exists to make impossible.
The four-mechanism flywheel is convincing, and the scope fall-through catch is a great example of the gate doing real work. The open question for me is the one you flag yourself: the harness still needs engineers to extend it, and those engineers got their judgment from years of exactly the implementation work you're now routing around non-engineers. So who lays the rails in ten years? The harness buys huge leverage today but quietly depends on a generation of engineers it doesn't reproduce.
Sharp question — and one I keep coming back to. My current bet: the rails-laying side stays engineering work for a long while, and the next generation of engineers grows by doing exactly that. The implementation work isn't going away; it's moving up one level, from "implement this feature" to "design the gate that catches the next class of bug like this." That's still hard, still requires years to mature, still builds the same muscle in a different shape. Engineering doesn't reproduce by accident — it reproduces by doing real work, and there's plenty of real work at the harness layer. Whether the shape of that judgment ends up identical to today's, I doubt — but the path isn't broken either.
The harness idea is the important part. If the workflow has strong constraints, tests, and review points, more people can author safely without pretending every author is also an engineer.
Exactly. "Without pretending every author is also an engineer" is the line — that pretense is what breaks down at scale. The harness is what lets the same workflow safely accept changes from very different authors without lowering the quality bar.
That is the right boundary. The harness should make contribution safer, not flatten everyone into the same role. A non-engineer can bring domain taste, examples, constraints, and edge cases; the harness translates that into checks the system can actually enforce. That is a much better model than asking every author to become half-engineer just to participate.
Beautifully put — "the harness translates that into checks the system can actually enforce" is exactly the design problem. The series wrap-up I have coming next week is almost entirely about that translation work, which I've come to think of as the whole job. You named it cleaner than I did.
That translation work feels like the real product. The hard part is not giving non-engineers a prettier text box; it is turning domain intent into enforceable constraints without making the author learn the machinery. Looking forward to the wrap-up. That boundary between expression and enforcement is where these systems either become empowering or quietly dangerous.
"Translation work feels like the real product" is exactly how I've come to think of it. And the "prettier text box" trap is real — you can ship a sleek interface on top of the same untranslated mess, and it just routes the failure further downstream. The hard work isn't in the surface, it's in turning intent into something the system enforces while the author keeps thinking in their own language. Your "empowering or quietly dangerous" framing — I'd phrase it slightly differently: this is fundamentally about the quality of the harness design itself. A well-built harness empowers; a sloppy one becomes a hazard. That's an old systems-engineering truth, not AI-specific — what's new is the kind of author we're handing the harness to, not the principle.
That is a fair correction. The harness quality is the real variable. The AI-specific part is the surface area of delegation: more people can now express intent into systems they do not fully understand. So the harness has to carry more responsibility for constraint, feedback, and safe failure than a normal UI would.
Yes — "surface area of delegation" captures the AI-specific part well. A regular UI exposes a bounded set of operations; the user picks among them. An AI harness accepts open-ended intent and has to translate it into system operations the author never wrote. So the harness ends up owning much more of what used to be the author's responsibility — constraint, feedback, safe failure, exactly as you said. The consequence I've come to accept is that harness engineering ends up being harder than the development it routes around, not easier. The author's job gets simpler; the harness builder's job gets more demanding.
Exactly. The hard tradeoff is that the harness has to make complexity legible without dumping it back on the author. My current test is: can the harness explain what it refused to do, what assumption it made, and what artifact changed? If it can do those three things, the author gets leverage without needing to become the engineer of the whole system.
That's a sharp test. Mapping it onto how I've built mine: "what it refused to do" shows up as lint + CI gates + review REQUEST_CHANGES with the rule cited; "what assumption it made" comes back as the knowledge-graph facts it pulled into the decision; "what artifact changed" is just the PR diff plus the auto-generated review summary. None of those are AI-novel — they're plain old observability of the harness. But none of them come for free either; designing those exposures intentionally is exactly the demanding part I meant by harness engineering being harder than the development underneath.
That breakdown is exactly what I would want to see from a mature harness. The interesting part is that none of those signals are magical, but the combination changes the trust model. A refusal with the rule cited tells you the boundary is active. The assumption list tells you what context the agent believed. The diff/review summary tells you what actually changed. Together they make the harness inspectable instead of mysterious. I think that is where a lot of teams underinvest: they spend time on the agent’s capabilities, but not on the evidence surface around those capabilities. Without that surface, even a good harness feels like a black box.
Honestly, my sense is sharper: to me, the whole job of the harness is taking the context handed to AI and pushing it from inference toward determinism — that's what confines hallucinations. Once you've actually done that, the evidence surface isn't a separate layer you bolt on; it's already there as the byproduct of the determinism. Refused / assumed / changed are just what the deterministic work looks like from the outside. So a "good harness without the surface" isn't really a picture I can hold — if the surface is missing, the determinism wasn't really done.
I like that framing. "Evidence surface" should not be a reporting layer added after the harness works; it is the external shape of the harness doing its job. If the harness really made the work deterministic, then it should be able to show the constraints, inputs, refused paths, assumptions, and changed artifacts without extra storytelling. When that surface is missing, the system may still be useful, but it is asking humans to trust an invisible process. That is the difference between "the AI helped" and "the team can safely delegate this class of work again."
Well put. That's a clean place to leave it — appreciated the thread.
Yes. That is also where the evidence surface becomes useful to humans, not just to the harness. If the harness can show which assumption failed, which artifact changed, and which check produced confidence, review becomes much less ceremonial. The worst version is a green/red badge with no chain behind it. The better version is a small audit trail that lets someone decide whether the result deserves trust.
standing up a stack is hard, building on top of one isn't 😀
Yes, exactly. The harness is what makes the "building on top of one" half safe enough to hand off. Without the harness, even that side stays engineering work.