みなさまこんにちは!エアークローゼットでCTOをしている辻です。
直前の連載code-graph deep dive後編で、「46リポジトリに跨るコードベースをAIにセマンティック検索できる形にした」という話を書きました。その最後に残した課題のひとつが**「動的解析の不在」**でした:
graphに乗っているのは「edgeが静的に存在する」という事実だけで、「実際にそのedgeが本番でどれくらい使われているか」は分かりません。
graphが「静的事実」を渡してくれても、本番でいま何が起きているかは別軸でAIに渡してあげる必要があります。つまり、静的解析と同じ発想を、そのまま観測スタックにも持ち込まないといけない。
今回はその話を、設計編(本記事)と実践編の2つに分けて書きます。本記事は4つの監視対象(アプリケーション / インフラ / CI / LLM)を、それぞれの問いの性質に合わせて違う形でObservableにする設計判断の話。
4つの観測対象を別々の形でObservableにする
code-graph連載で得た一番大きな教訓は、「AIに渡す前にデータを正しい形にしてあげる」必要がある、ということでした。46リポジトリ分のソースコードをそのまま投げてもcontext windowは足りないしハルシネーションも起きる。だから静的解析でグラフ化して、境界ノードに意味を載せて、SAME_ENTITYで繋いで、とObservableにしてから渡す。
観測スタックも全く同じ構造の問題を持っています。本番の生ログをそのままAIに渡しても、
- ログの量でcontextが埋まる
- どこがerrorでどこが正常なlogかAIには区別がつかない
- メトリクスとログとトレースが断絶している
- そもそも「いま何にいくらかかってるか」の答えは生ログには載っていない
= AIに渡せる形でObservableにする必要がある、という同じ問題。
ここで重要なのは「Observableにする形」はAIが何を答えるべきかで変わる、という点です。cortex(社内AIプラットフォーム)では、監視対象を4つに分けて、それぞれ別の問いに対応した形で乗せています:
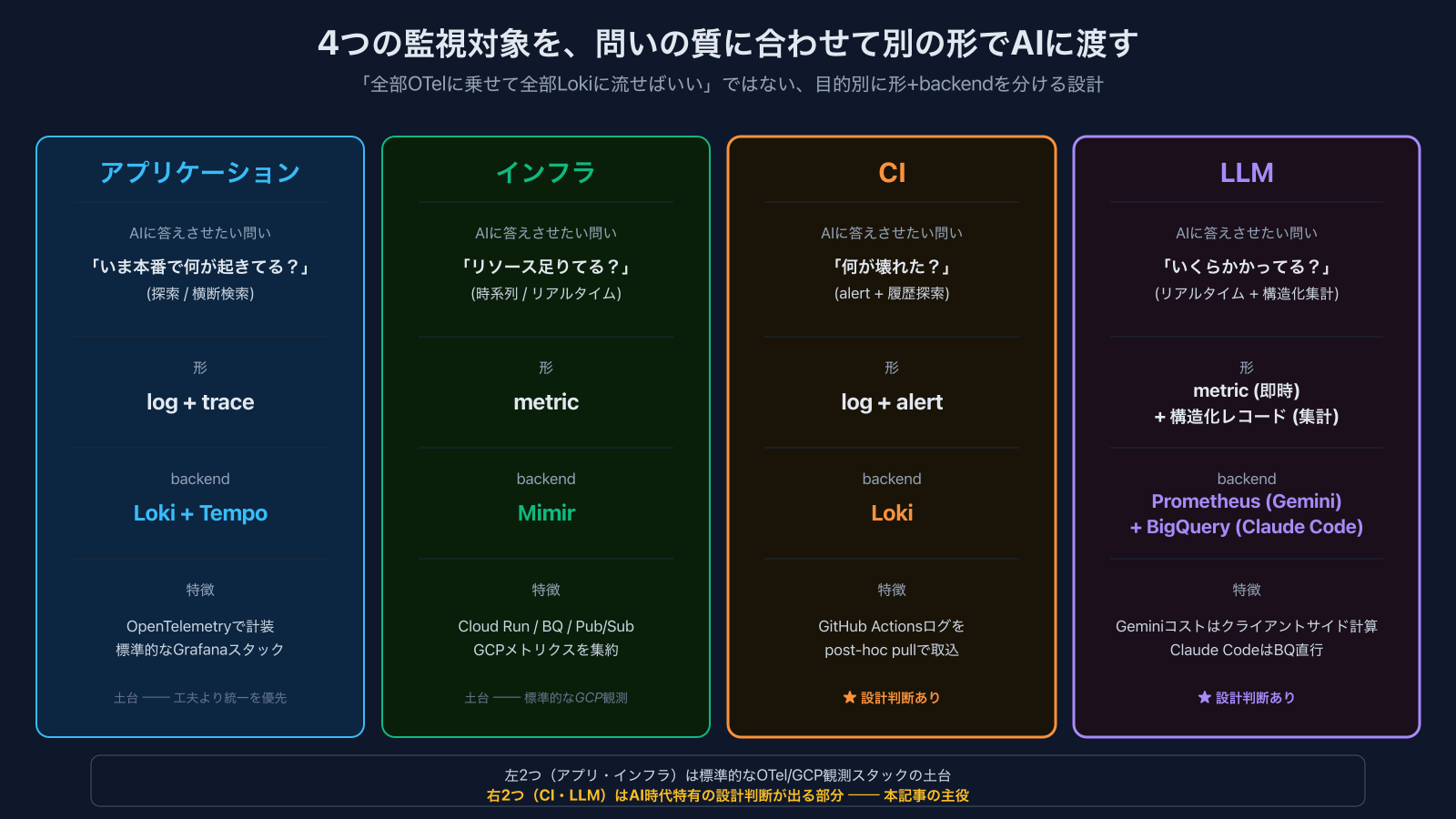
| 監視対象 | AIに答えさせたい問い | 形 |
|---|---|---|
| アプリケーション | 「いま本番で何が起きてる?」(探索) | log + trace |
| インフラ | 「リソースは足りてる?落ちてない?」(時系列) | metric |
| CI | 「何が壊れた?いつから壊れてる?」(alert + 履歴探索) | log + alert |
| LLM | 「いくらかかってる?誰がどれだけ使った?」(リアルタイム + 構造化集計) | metric + 構造化レコード |
「全部OTelに乗せて全部Lokiに流せばいいじゃん」という選択肢は確かにあります。でもそうすると、「リアルタイムの『今いくら』」と「『先月の累計をteam別に集計』」のような質的に違う問いを1つのbackendで答えようとして、どこかが苦しくなる。ここを目的別に分けたのがcortexの選択です。
以下、4つの軸を順に書きます。アプリケーションとインフラは「土台」として簡単に触れ、CIとLLMはAI時代特有の設計判断が出るので深掘りします。
アプリケーション ── OTel + Loki + Tempoの標準スタック
土台はシンプルです。cortexの各アプリケーションはOpenTelemetryで計装していて、traceはTempo、logはLoki、metricはMimirに流す ── というGrafana Cloudの標準形。
ここは特別な工夫はしておらず、重要なのは「全アプリが同じ形でログとトレースを出す」という統一だけです。これがあるから、後でMCP経由でAIが {app="<service>"} |~ "error" のようなLogQLを投げて横断的に調査できる。
具体的な計装方針は別記事AI Harness連載Part 4 (Self-Healing)で触れたので、本記事では深掘りしません。「標準的なOTelスタックがちゃんと敷かれているか」が、この後のAI駆動運用の前提になる、とだけ書いておきます。
インフラ ── Cloud Run / BigQuery / Pub/SubのmetricをMimirに集約
cortexはGCP上で動いていて、Cloud Run / Cloud Run Job / BigQuery / Pub/Sub / Cloud Tasks等を組み合わせて使っています。各GCPリソースのmetric (CPU / memory / 実行回数 / レイテンシ / queue滞留時間等)は、Cloud Monitoring経由でMimirにexportしています。
ここも特別な工夫はしてなくて、標準的なGCP metricをGrafana CloudのMimirに集約しているだけ。ただ「全インフラmetricが1ヶ所に集約されている」状態を作っておくと、AIが「先週、一番CPU使ってたserviceは?」「queueが詰まってるworkerある?」みたいな問いに自然に答えられるようになる ── これも後でMCP経由で効きます。
ここまでが「土台」です。一般的な観測スタックの話なので、詳しくはGrafanaやOpenTelemetryの公式ドキュメントを当たってください。
ここから先(CIとLLM)がAI時代特有の設計判断が出る部分です。
CI ── webhook pushではなくpost-hoc pullでLokiに流す
cortexはGitHub ActionsでCIを回していますが、CIのログをそのままGrafana Lokiに流しています。
「Github ActionsのログはGitHub UIで見られるじゃん」という疑問は当然あって、ただこれには明確な理由があります:
- GitHub ActionsのAPIはAIから検索しづらい
- 別レポジトリのCI結果も、アプリログも、全部1つのLokiに乗ってると横断クエリできる
- LogQL alertで失敗を構造化された判定にできる
- AIが「先週から壊れてるテストある?」みたいな問いを自然言語で投げられる
ただし送信の仕方が普通と違います。cortexの選択は:
CI実行中にログをpushするのではなく、完了後にGitHub APIからpullする

具体的には:
- Testジョブが終わると
workflow_runイベントが発火 - ログ送信用の別workflowが起動される
- そのworkflowがGitHub API (
/repos/.../actions/jobs/.../logs)からログを取得 - 構造化されたJSON (job / status / ref / pr / commit / output等)としてOTLP
/v1/logsでGrafana Cloudに送信
{service_name="ci", ref="main", status="failure"} でフィルタすると、mainブランチでのCI失敗だけが綺麗に拾える。
なぜpush方式じゃなくpull方式か:
- CI実行とobservabilityを切り離せる。逆に送信だけリトライ / 再実行も可能
- PR由来コードがkeyに触れる経路自体が存在しない:
workflow_runでトリガーされる別workflowはデフォルトブランチのcontextで実行され、fork PR側のコードではなくbase repoのsecretを使う。つまりテスト本体はGrafana API keyにそもそも触れない構造的保証 - 送信失敗の検知が独立できる、送信が壊れた時に観測スタックが沈黙して気付けない。分離していれば、ログ送信workflowの成否それ自体が観測対象になるので、そこにalertを貼れる
そしてmainブランチでfailureが出た瞬間にLogQL alertが発火し、Slackに通知される ── これが実践編で扱うSelf-Healingの起点になります。
LLM ── GeminiとClaude Code、2つの違う形
最後の軸がLLMの利用観測です。cortexはGemini APIとClaude Code (Anthropicの公式CLI)を両方ヘビーに使っていて、どちらもコストが発生する。両者でbackendを分けている根本的な理由は計装地点(instrumentation locus)の違いにあります:
- Geminiは呼び出し元のコードを自分で握っているので、共通wrapperでinline emitできる → metric (Prometheus)が自然
- Claude Codeは外部CLIでwrapperでラップできない。利用ログは事後レコードとして降ってくる → 構造化保存先(BigQuery)が自然
「リアルタイムで見たいか / SQL集計したいか」という問いの性質は、この計装地点の違いから派生的に決まります。以下、順に深掘りします。
Gemini ── Prometheusで「いま、何が高い」を即時可視化
cortexはGeminiをdb-graphのテーブル説明文生成、code-graphのフィールド型推論、各種コンテキスト生成 ── 至るところで叩いています。ここで答えたいのは「いま、何が高い」を遅延なしに見ること。暴走promptや暴走batchが走った時に、翌朝のbillingまで待ちたくない。
そこで、全Gemini呼び出しを共通のwrapper (traceGeminiCall)で包んで、呼び出しごとに4本のメトリクスを出力する設計にしています:
gemini.tokens.total── 累積トークン(labels:model/service/type=prompt|completion)gemini.requests.total── リクエスト数(labels:model/service/status)gemini.request.duration── レイテンシヒストグラムgemini.cost.usd── 推定コスト(labels:model/service)
ここで設計判断が分かれるのが、「コストを誰が計算するか」です。選択肢は2つ:
- A. Google Cloud Billing APIから後追いで取得する ── 正確、でもbilling反映まで数時間〜1日のラグ + タスク単位のコスト粒度がない
- B. 呼び出し直後にトークン数 × 単価表でクライアントサイド計算する ── 即時 + タスク単位の粒度を自前で付けられる、でも単価表のメンテが要る
採用したのはBです。単価表は GEMINI_PRICING という定数で持っていて、Googleが値段を変えたら手動で更新する。gemini-3-flash や gemini-3-pro ごとにinput / output単価を持っているだけの素朴な表。
なぜAを捨ててBを採ったか。本命の理由はタスク単位のコスト粒度です:
- 何にどれだけかかったかが分からないとチューニングしようがない。Cloud Billingは「Vertex AIで合計X円」までしか答えてくれない。でも実際に削りたいのは「db-graphのテーブル説明文生成にいくら」「code-graphのフィールド型推論にいくら」「あのpromptひとつにいくら」というサブ単位。クライアントサイドでwrapperを通せば、service / model / 呼び出し元コンテキストをラベルとして付与できるので、後でPromQLで好きな軸で集計できる
- 副次的に、「いま、何が高い」が即時に見える ── 暴走promptやbatchを1日待たずに気付ける
- 単価表のメンテ頻度が低い(Googleも値段はそうそう変えない) ── 負債としては小さい
- Cloud Billing APIの認証・取得・正規化・再分配のパイプライン自体がそれなりに重い
そしてPrometheusの累積カウンタとして gemini_cost_usd_USD_total に出すと(OTel側のmetric名 gemini.cost.usd + unit USD がPrometheus exporterで合成された形)、GrafanaのPromQLでそのまま sum(increase(gemini_cost_usd_USD_total[1h])) のような形で「直近1時間でいくら使った?」が答えられる。これを**$1/hour超えたらinfoアラート**でSlackに飛ばすシンプル設計。
リアルタイムの「いま」を答えるのは、Prometheusがいちばん向いてる形です。
Claude Code ── BQに溜めて構造化集計に強くする
社内の開発者は全員Claude Codeを使っています。これも当然コストが発生する。誰がどれだけ使ったか、どのリポジトリでどれだけトークン消費したかを把握したい。
ここで設計が分かれた質問:「Claude Codeの利用ログもLokiに流すべきか?」
答え: NO、BQに溜める。
なぜか。Claude Code利用ログは本質的に構造化された帳簿だからです:
email── 利用者repository── どのリポジトリでの利用かtimestamp── いつinput_tokens/output_tokenscache_creation_input_tokens/cache_read_input_tokens── prompt-cacheの効きを含む
これを引きたい問いはこんな形:
- 「先週、チームAのメンバーが累計でいくら使った?」
- 「リポジトリXの編集に1ヶ月でいくらかかってる?」
- 「prompt-cacheのhit ratioはチーム間でどれくらい差がある?」
全部SQL集計向きの問いです。LokiのLogQLではaggregationもjoinも辛い。一方BigQueryならDAYパーティション + emailを主キーに普通に書ける。
そこでClaude Code → BQパイプラインを4段階で組んでいます:
- Emit ── Claude Code側に組み込んだanalyzerが
UsageInput(email無しのtoken情報のみ)を社内エンドポイントにPOST - Auth proxy ── Cloudflare Edge Router workerが
CORTEX_API_KEYを検証して、そこで初めて利用者emailをX-Cortex-User-Emailとして付与 - Ingest ── Cloud Run受信APIがdedupしてPub/Subにpublish
- Persist ── Cloud Run workerがPub/Subからpull、schema検証、BQにstreaming insert
設計的に効いているポイントを2つ:
- identity authorityをEdge Routerに集約 Routerでしかやらない。emit側(Claude Code)はemailを持たない。これでクライアント側のid詐称や、social engineering系の経路を構造的に閉じる
- Pub/Subでasync分離: ingestとworkerを分けて、worker側で詰まってもingestの応答時間に影響しない。失敗時はPub/Sub DLQで最大5回retry
そしてBQに溜まったものは、実践編で扱う社内ポータルから「誰がどれだけ」を毎日見られる状態にしています。実物がこれです:
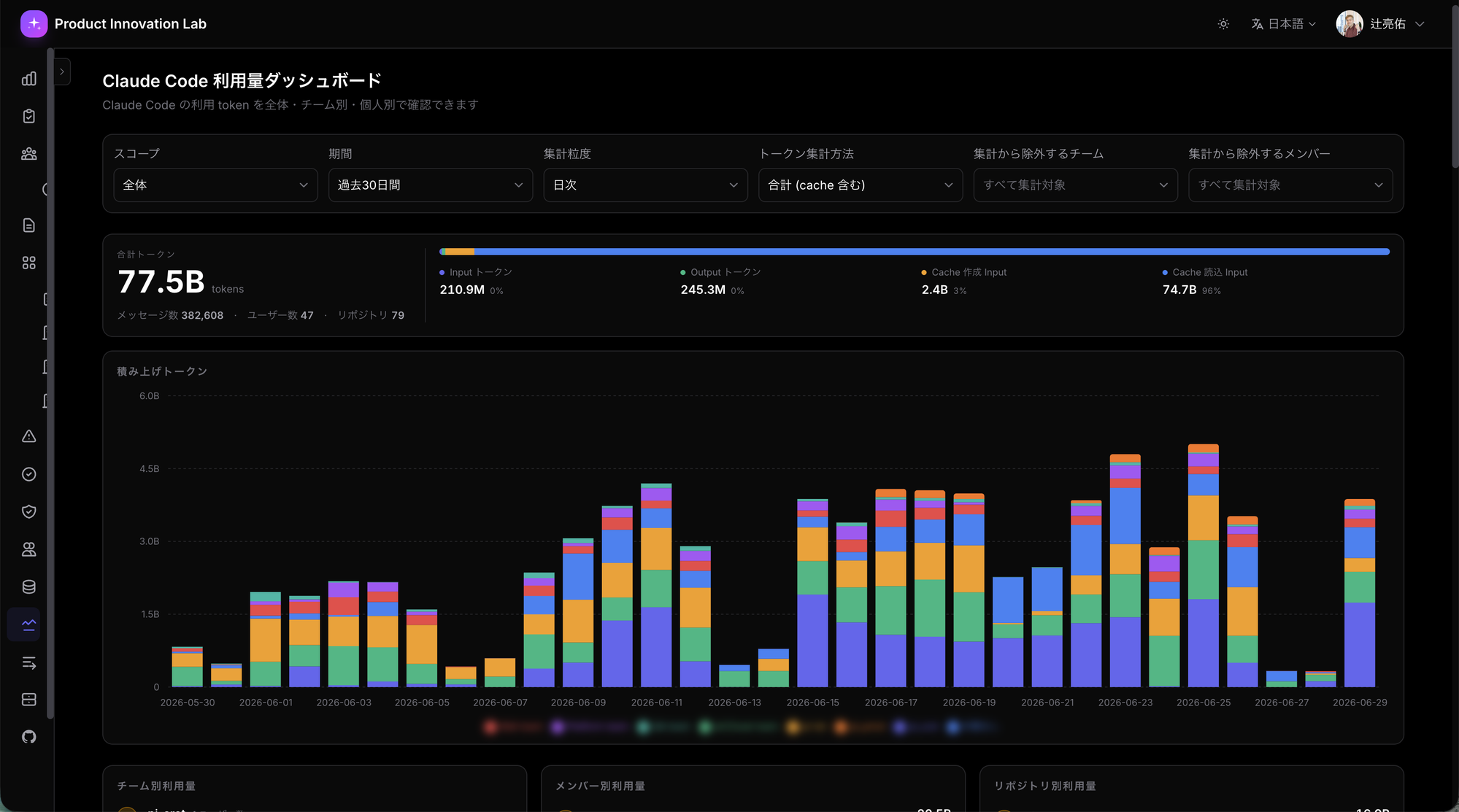
数字が興味深いので軽く触れておくと、過去30日で77.5Bトークン / 382Kメッセージ / 47ユーザー / 79リポジトリ。そして注目すべきはCache読込Inputが74.7B(全体の96%)という点です。これはprompt-cacheが劇的に効いていることを示していて、cache読込のトークン単価は標準input単価の約1/10なので、cacheなし仮定との比較ではinput実効単価ベースで全体で7倍前後コストが下がっている計算になります。「集計の質的な性質に合わせたbackend」という設計判断のおかげで、こういう実運用上の重要な指標が自然にSQLで引けて毎日見える状態になっています。LogQLで同じことをやろうとしたら大変です。
ちなみにMCPの利用ログも似た形でBQに溜めています(cortex.mcp_tool_calls)。こちらはOTelですらなく、各MCPサーバーが直接BQにレコードを書き込む構造。前回の連載で「annotation graphのMCPが約50,000回 / 約73人に使われている」と数字を出したのは、全部このテーブルから取っています。
「全部OTel」教義に寄せきらず、集計の質的な性質に応じて道具を分けているのがこの層の核心です。
つづく
ここまでで4つの監視対象(アプリケーション / インフラ / CI / LLM)と、それぞれの設計判断を書きました。観測スタックの書き込み側の話としては一旦完結します。
ただ、「Observableにしただけ」では話は終わらない。観測スタックには本番データが流れる以上、PIIとAIの検索性をどう両立させるかという問題が必ず出ます。そして全部繋がると、自動修復(Self-Healing)の本当の駆動源が観測スタック側から見えてくる ── というのが実践編の話です。
長文をお読みいただきありがとうございました。1週間後に実践編「AI時代のObservability設計 - PIIとAIの検索性を両立させ、自動修復する」を公開予定です。
comments (0)
まだコメントはありません。