みなさまこんにちは!エアークローゼットでCTOをしている辻です。
これまで社内MCP群の全体像、DB Graph MCP、Biz Graph、Sandbox MCPと、社内向けに作っているMCPサーバーを順に紹介してきました。
今回はその運用の中で見えてきた、自作MCPサーバーのトークン消費を減らすコツの話を書きます。
困りごと:MCPは意外とトークンを食う
MCPでAIエージェントを拡張するとき、最初に遭遇するのがトークン消費が想定より多いという現実です。
MCPのツール呼び出しは、結局のところJSON-RPC over HTTPです。AIが送る引数も、ツールが返す結果も、そのままAIの会話コンテキストに乗ります。素直に実装すると、
- ファイル丸ごとを引数で送る → 数千行のソースコードがコンテキストに張り付く
- DBクエリ結果を全件返す → 数千行 × 数十カラムの表がコンテキストに張り付く
ということが頻繁に起きます。Claude Codeであれば、1ツールコールで簡単に数万トークン消費し、セッションが圧縮対象になる。
それだけならまだしも、行数が一定を超えるとそもそもエラーで返ってこないこともあります。MCPのレスポンスサイズ上限に引っかかって失敗するパターンです。
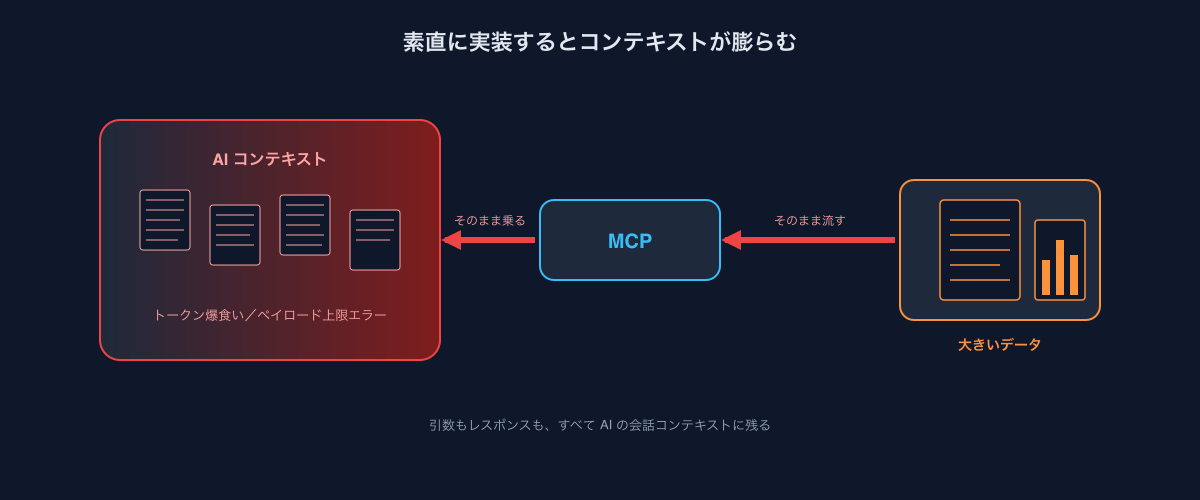
社内でMCPを増やしていた当初、この「ちょっとしたミスマッチ」がツール体験を確実に悪くしていました。
基本パターン:大きいデータは別の場所に退避し、キーだけ流す
解決策は身も蓋もないシンプルさです。
大きくなりがちな部分をMCPの通信路から外し、参照用のキー(またはURL)だけを流す。
リクエスト側もレスポンス側も同じ発想で対処できます。
| 方向 | 何を外すか | どこに退避するか |
|---|---|---|
| リクエスト | 大きいファイル / ソースコード | GitHubやDriveなどのオブジェクトストア |
| レスポンス | 大きい一覧データ / クエリ結果 | Spreadsheet / GCS / BigQuery |
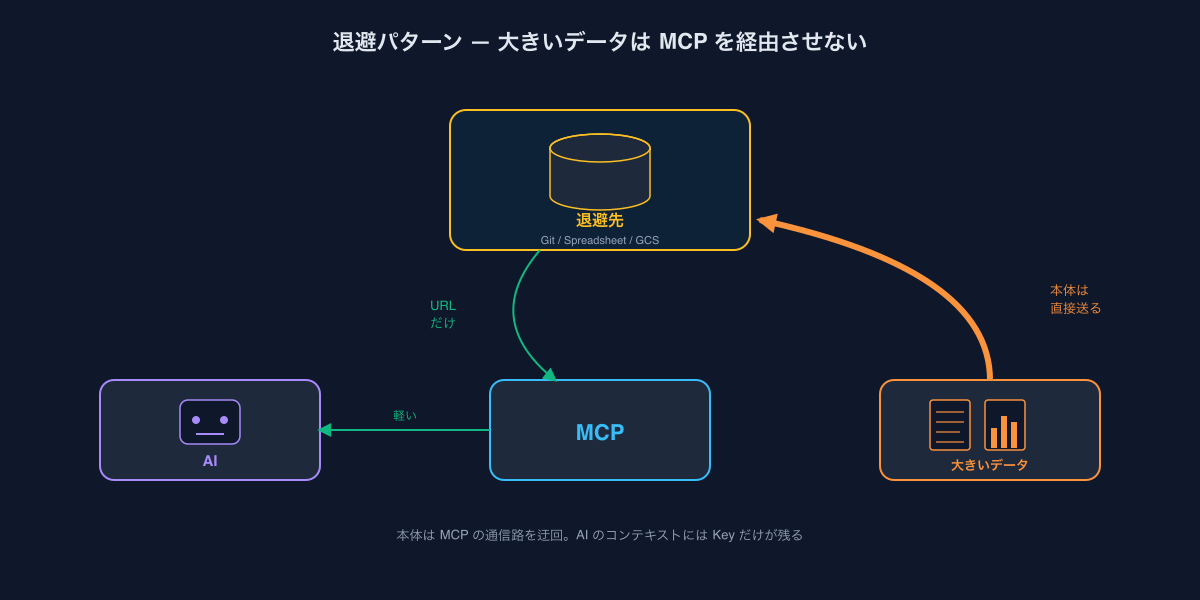
エアークローゼットでの実例を2つ紹介します。
例1:リクエストを軽くする ── Sandbox MCP × 自前Git Server
Sandbox MCP(非エンジニア向けにアプリを社内公開できるプラットフォーム)は、最初はMCPツールでファイルを送る設計でした。
sandbox_write_file(app_name: "todo-app", path: "index.html", content: "<html>...")
sandbox_write_file(app_name: "todo-app", path: "app.js", content: "import ...")
sandbox_publish(app_name: "todo-app")ところがアプリの規模が少し大きくなった瞬間に破綻しました。
- チャンク分割が頻発: ペイロードサイズ上限に引っかかり、AIが「ファイルAの前半 → 後半 → ファイルBの前半 → ...」を繰り返す
- トークンが燃える: ソースコード全体がそのまま会話コンテキストに乗る。数千行のアプリ1回のデプロイで数万トークン
- リトライで悪化: AIは「念のため確認」と言って
sandbox_read_fileで同じファイルを読み返す。書く・読む・書くのループ
そこで、MCPではURLだけを返し、実体はgitプッシュに逃がす方式に変えました。
# 1. MCPはgit URLを返すだけ(ペイロードに実体は乗らない)
sandbox_init_repo(app_name: "todo-app")
# → https://mcp-sandbox.example.com/git/sandbox/ryan/todo-app.git
# 2. AIが裏でgitコマンドを実行(MCPは介在しない)
git init && git add . && git commit -m "init"
git remote add sandbox <返されたURL>
git push sandbox main
# 3. デプロイ指示だけMCPで送る
sandbox_publish(app_name: "todo-app")gitプッシュは
- ファイルサイズ制限なし
- 差分転送なので2回目以降は速い
- ソースコードがMCPの会話コンテキストに乗らない
の三拍子で、トークン消費の観点では本質的に異なります。AIから見れば「git URLというキーを受け取り、それに対してプッシュするだけ」です。
ちなみにGitHubの組織アカウントは使っていません。社員全員にGitHubのシートを発行するのはコスト・運用ともに割に合わないし、すでに別目的で社内Git ServerをGCE上で運用していたので、そこに sandbox-apps リポジトリを1つ足しただけで成立しました。「退避先」は、自前で建てる必要すら必ずしもありません。
例2:レスポンスを軽くする ── DB Graph MCP × Spreadsheet
DB Graph MCPは社内991テーブルを自然言語で検索・クエリできるMCPです。
ここで地味に厄介なのが、「全件出して」系のクエリです。
SELECT * FROM service_main.user WHERE created_at >= '2026-01-01'これ、結果が数千〜数万行になると、
- 数百万トークンを消費してMCPが即セッション圧縮を呼ぶ
- ペイロードサイズ上限を超えてエラーになる
のどちらかor両方が起きます。AIの側で「LIMIT 100だけ取って分析する」のが正しい振る舞いではあるんですが、ユーザーの本来の要件が**「リストをCSVで欲しい」**だったりすると、それでは話が進みません。
そこで、DB Graph MCPには**「SpreadsheetにエクスポートしてURLだけ返す」モード**を組み込みました。明示的に指定もできますし、結果が一定行数を超えたらMCP側で自動的にこのモードへフォールバックします。AIが LIMIT を付け忘れて1万行返ってきそうになっても、サーバー側で「これはインラインで返したらまずい」と判断してSpreadsheetにエクスポートし、URLを返してくれる。
// 概念コード(実装はMCPツールのdescriptionに明記)
sql_query_database({
query: "SELECT * FROM ...",
output: "spreadsheet" // ← 明示指定するとエクスポートモードに
})
// 一方、output未指定でも閾値(例: 500行)超えで自動フォールバック
sql_query_database({
query: "SELECT * FROM ..."
})
// → サーバー側で行数判定 → Spreadsheet出力 + URL返却
// どちらの場合もレスポンスは同じ
{
url: "https://docs.google.com/spreadsheets/d/{...}/edit",
rows: 12483,
columns: ["id", "email", "created_at", ...],
exported_reason: "row_count_exceeded" // 自動フォールバック時
}レスポンスはURL+メタデータだけ。実データはコンテキストに乗りません。**「気をつけて使えば軽くなる」ではなく「うっかり使っても勝手に軽くなる」**のが、運用上の安心感に直結します。
このパターンが効くのは、現実のユースケースの**かなりの部分が「データを別媒体に出力したいだけ」**だからです。AIと会話して分析したいわけではなく、
- スプレッドシートに保存して後でじっくり眺めたい
- 別チームに共有したい
- VLOOKUPで別シートと突き合わせたい
といった用途。これだったら、MCPの役割は「クエリを書いて、然るべき場所に置く」までで十分なんです。
もちろん、AIに分析させたい場合は結局のところデータ自体をコンテキストに入れる必要があります。その場合は LIMIT 100 で取得してサンプル分析、結論が見えたら output: spreadsheet で全件エクスポート ── という二段構えでAIに運用させるのが定石になっています。
どれくらい効いたか
エアークローゼットで提供しているMCPは、すべてツール呼び出しのログを取っています。これらのパターンを順次入れていった結果、全ツール合算でのトークン使用量が70〜90%削減されました。
おまけ:Google Workspace OAuthがかなり相性が良い
「退避先」を選ぶときの話なんですが、MCPの認証にGoogle Workspace OAuthを採用していると、この設計が一気に楽になります。
なぜかというと、MCP自体の認証(誰が使っているのかを特定する)と、Workspaceアプリへの認可(Spreadsheet / Drive / Gmail / Calendarに対する操作権限)を、同じOAuthフローで一石二鳥に取得できるからです。MCPのログインさえ済んでしまえば、退避先に書き込むための権限は追加で何も要求する必要がない。
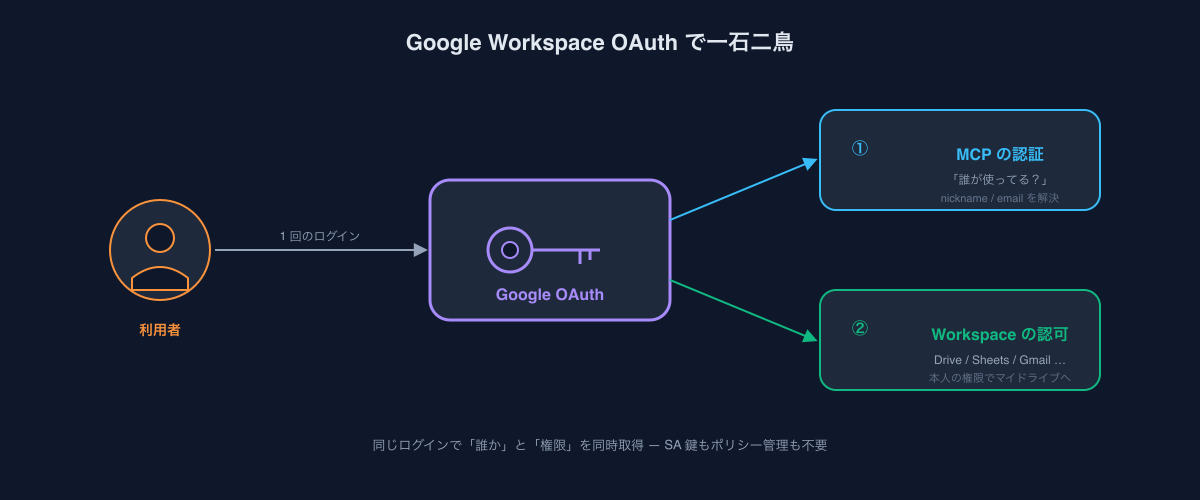
これによって、
- AIエージェントを操作しているユーザー本人の権限で
- そのユーザーのマイドライブに
- ファイルを保存できる
という構図が作れます。サービスアカウントが共有ドライブに置くのではなく、ユーザー自身のドライブに置く。これだけで「不用意に全社公開してしまった」「権限を渡すべきでない人にも見えていた」といった事故が物理的に起こらなくなります。
別途Google Cloudのサービスアカウントを発行する/そのキーをどこかに安全に置く/権限ポリシーを別管理する ── みたいな運用コストもゼロになるので、本当に「タダ」で手に入る安全策です。
ただしこのパターンには注意点が1つあります。
AIエージェント側が、返ってきたSpreadsheet URLからデータを抽出できる必要がある
URLを返しただけでは、AIはその先のデータにアクセスできません。Claude Code等の標準ツールにはSpreadsheetを直接読む機能はないので、別途Workspace操作用のMCPを用意する必要があります。
エアークローゼットではGoogle WorkspaceのAPI(Drive / Sheets / Gmail / Calendar)をラップした専用MCPを別途立てていて、これと組み合わせることで「結果をSpreadsheetに書き出し → 必要に応じてそのMCPで読みに行く」というフローが完結します。
DB Graph MCP → Spreadsheet出力 → URLを返す
↓
Workspace MCP ← AIが「内容も見たい」と判断したら呼ぶユーザーの体験としては「とりあえずスプレッドシートに出して、必要なときだけAIに分析させる」が自然に成立します。
まとめ
自作MCPサーバーのトークン消費を抑えるコツとして、
- 大きくなりがちな部分はMCPの通信路から外す
- 退避先(Git Server / Spreadsheet / GCSなど)に置いてキー / URLだけを流す
- 退避先にはGoogle Workspace OAuthとの相性が良い場所を選ぶと安全性も担保しやすい
- 退避先のデータをAIに読ませたいなら、Workspace系MCPをセットで用意する
を紹介しました。設計としては地味ですが、やる前と後でMCPの使用感がガラッと変わるくらい効きます。
自作MCPサーバーを社内で運用していてトークン消費に困っている方は、ぜひ試してみてください。
comments (0)
まだコメントはありません。