みなさまこんにちは!エアークローゼットでCTOをしている辻です。
今回は、複数サービス合計46リポジトリに跨る本番システムのコードベースを、静的解析で1つのナレッジグラフに統合した話です。
社内ではcode-graphと呼んでいて、今年の1月から3月にかけて構築しました。
書き残しておきたい論点が3つあります。
- なぜ「コードを読ませる」だけでは足りなくて、リポジトリを跨いだ繋がりまで取りに行く必要があったのか
- 46リポジトリに散らばる多種多様なフレームワーク(jQuery / AngularJS / Express / NestJS / TypeORM / Redux Axios ...)の境界をどう抽出していったか
- 3ヶ月の試行錯誤の結果、何が解けて何が解けなかったか
本記事は前編で、code-graph自体の構築と苦労、そして残った課題までを書きます。後編では、code-graphをbaseにしつつ別レイヤーで補強したservice-product-graph(SPG)の話を予定しています。
何のために作ったか
長年積み上がった本番システムのコードベースは、ふつう、次のような状態になります。
- 複数サービス・複数チームが触る
- 各時代のフレームワークが時代ごとに混在している
- API・DB・Eventによるリポジトリ間の依存が、1複雑に絡み合っている:
- 同じAPIを複数のリポジトリから叩いている (= 呼び出し元が複数のn)
- 同じDBテーブルへの書き込み / 読み込みがn
- Eventは発行側を見ても購読側をどこまで網羅できているか、そもそも追いきれない
このコードベース全体に対してAIに「影響範囲を見てほしい」「ここを変えたら何が壊れるか調べてほしい」と頼みたい、というのが出発点でした。
ここで素直に考えると、「AIに全リポジトリのコードを丸ごと渡して解析してもらえばいいんじゃないか」 となります。
ただ、それは2つの理由で無理です。
- コンテキストウィンドウ: 46リポジトリ × 長年積み上がったコード量を、AIにそのまま渡せるサイズではない
- ハルシネーション: 仮に渡せたとしても、AIが「全体を読んで関係性を抽出する」 のは推論ベースの作業で、見落としや誤りが入る。本番システムの影響範囲調査としては使えない
そこで、まず考えついたのが「外側から静的解析でナレッジグラフを作る」 というアプローチでした。これがcode-graphの出発点です。
規模感: 46リポジトリ
対象は2つのgraphに分かれています。
- air-closet graph(37リポジトリ): airClosetや、Men's、WMSなど複数サービスを横断するgraph
- mall graph(9リポジトリ): airCloset Mall系
合計で46リポジトリ。
ポイントは、これが「1サービスで」 ではなく複数サービスの集合でこの規模になっている、という点です。サービス境界そのものを跨ぐ依存関係をクロスリポジトリのedgeとして見えるようにしているのが、このあと出てくる境界ノードの話に繋がります。
なぜ境界ノードが重要なのか
ここがこの記事の中心です。
AIにコードを理解させるとき、目の前にあるコードや、その横にあるコードを「読ませる」のは、別に難しくありません。grepして該当ファイルを開いて読ませる、これで十分機能します。
ただ小規模なコードベースならそれだけでも十分ですが、大規模なコードベースで同じことをしても、前述のコンテキストウィンドウやハルシネーションの問題が発生します。きっとこれを読んでいる多くの方も共感するのではないでしょうか。
これを改善する一つの方法として、コードベースを静的解析し、ナレッジグラフに変換してMCP経由でAIに供給するという手法をとっています。
そのまず第一歩目として行ったのが、tree-sitter(ソースコードを構文木にパースするOSSライブラリ。多くの言語に対応していて、VS Code等のエディタの構文ハイライトでも使われている)を使った静的解析でした。このツール自体は非常に有用なので、似たようなことをしたい方には非常におすすめなのですが、tree-sitterだけでは解決できないこともあります。
それはAPIやデータベース等の境界をまたいだ関係性の追跡です。tree-sitterはプログラミング言語の変数や関数等の処理の関係性を解析し抽出することはできますが、そういった境界を抽出することはできません。
しかし実際に人でもAIでも躓きがちなのは、こうした境界をまたいだコードの繋がりです:
- 同じAPIを叩いている処理が、別のリポジトリにもあるかもしれない
- フロントエンドのA repoと、夜間バッチのC repoが、同じ
/api/v1/users/meを叩いている可能性 - 片方のrepoだけ見ていても、AIには絶対に分からない
- フロントエンドのA repoと、夜間バッチのC repoが、同じ
- 同じDBテーブルを参照しているコードが、バッチにあるかもしれない
- サービス側の処理を修正したいときに、別の場所のバッチが同じテーブルを読み書きしている可能性
- 影響範囲を取り違えると、データ不整合が起きる
- このイベントを購読しているsubscriberが、把握しきれていないかもしれない
- Pub/Subのような分散通信で、emit側を見るだけではsubscribe側を網羅できない
- 知らない場所で別の処理が走る
要するに、「境界の先にあるコード」をAIにハルシネーションを起こさせずに把握させること。これが目的です。
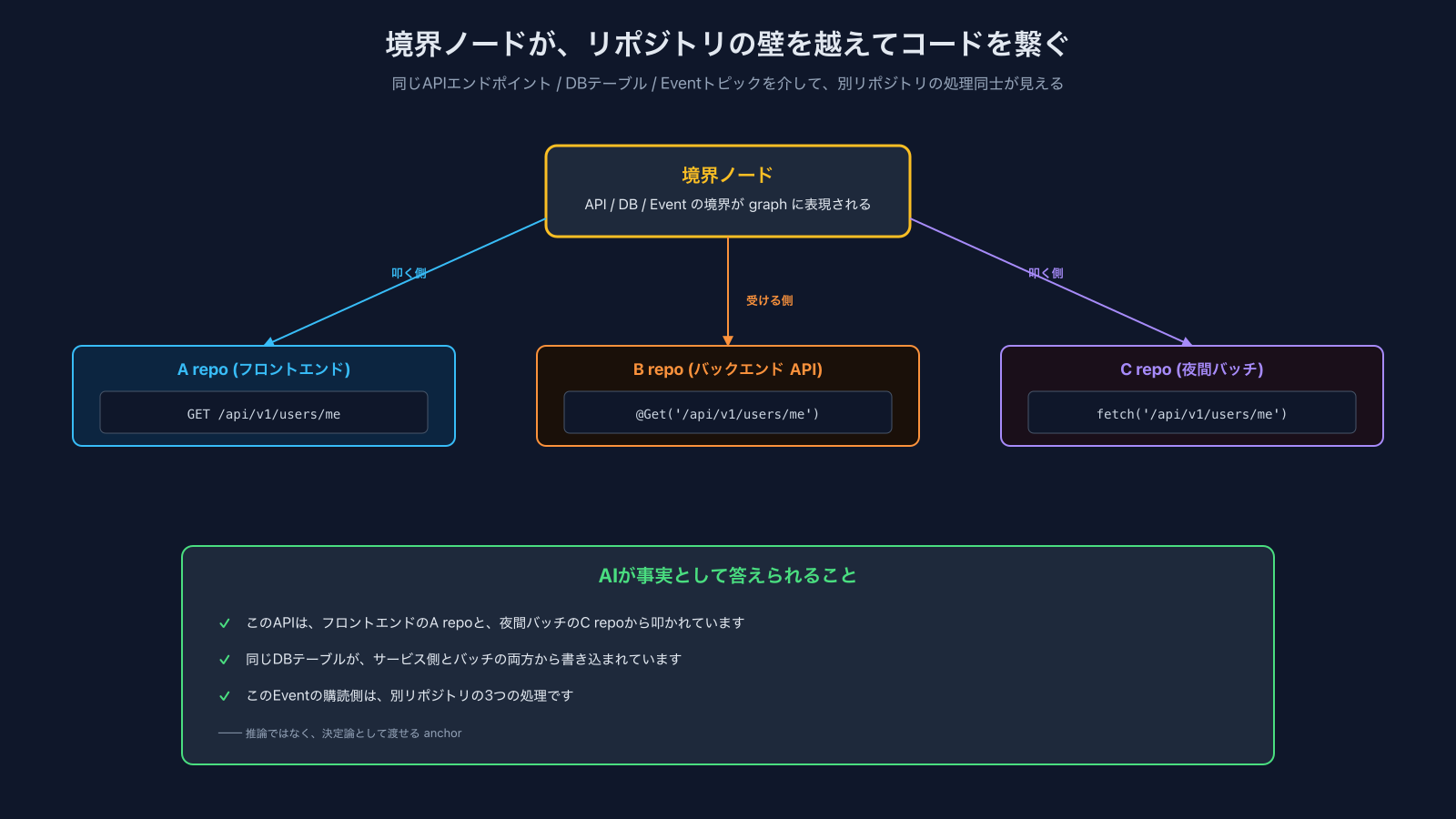
境界ノードを取れていれば、AIは「このAPIは他にも〇〇 repoで叩かれています」と事実として答えられます。AIに推論させるのではなく、事前に解決済みの事実として渡せるわけです(抽出時にはTypeScript CompilerやGeminiで推論が入りますが、その結果はgraphに確定値として保存され、後述する境界分析の日次cronでドリフトを翌朝検知できる状態にしています。AIが消費する時点では、検証された事実だけが渡る形になります)。
AIは「分からないこと」を「分からない」と返すより、見えている範囲で何かしら返してしまう傾向があります。ここで起きるのが、サイレントなハルシネーション。AI自身も、それを受け取る人間も気付かない誤答です。境界ノードは、これを物理的に塞ぐ事実の拠り所になります。
構築: tree-sitterベース、必要なところでTypeScript CompilerとGeminiを併用
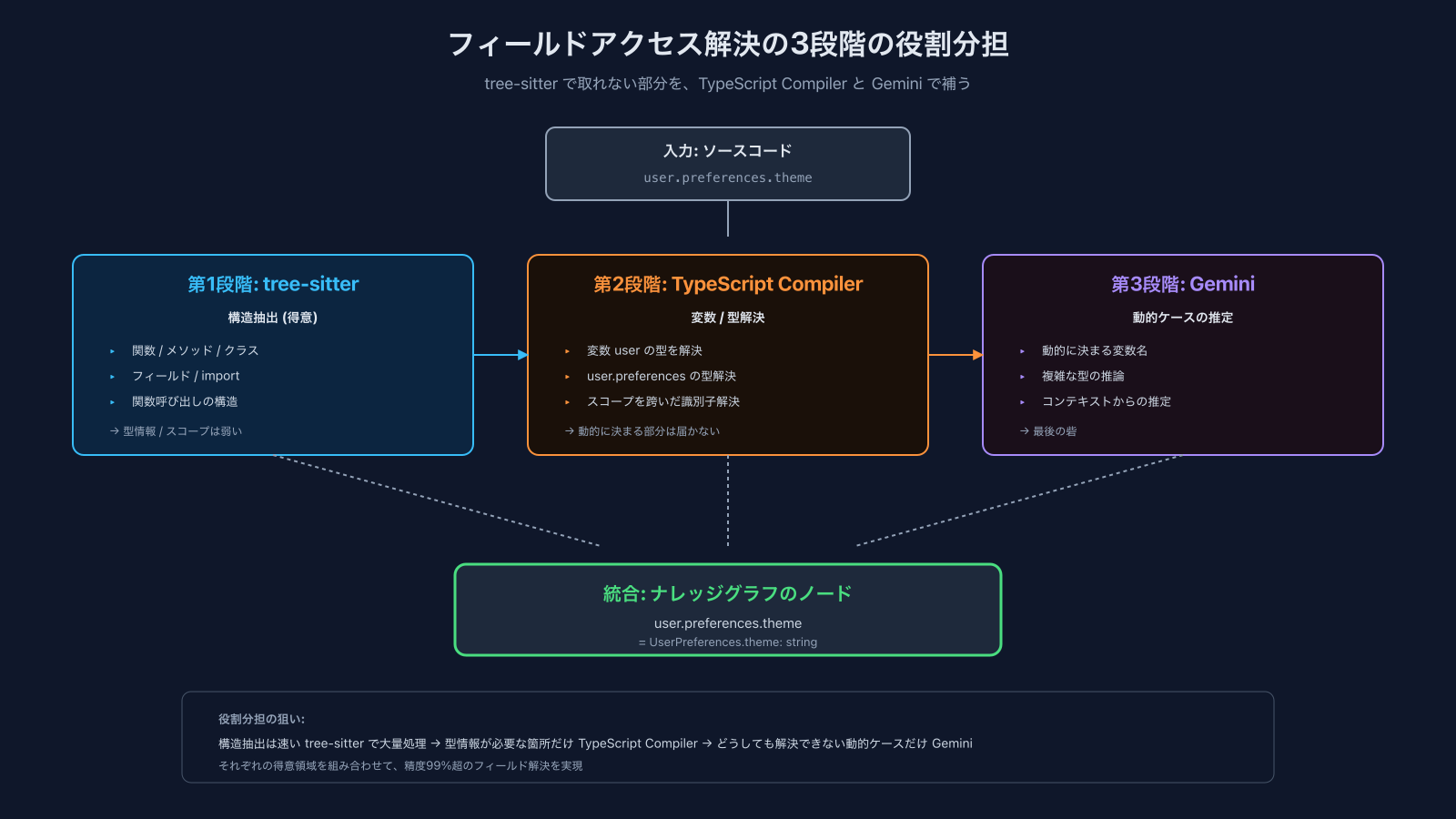
通常のコード(関数呼び出し / クラス継承 / import関係)は、tree-sitterで比較的簡単に取れます。ASTを辿って関数 / メソッド / クラス / フィールドをノードにして、参照関係をエッジで結ぶ。これは粛々とやるだけです。
ただ、tree-sitterは構文木を作るのは得意ですが、型情報やスコープ解析は弱い。フィールドアクセス(user.preferences.themeのようなチェーン)を正確に追うには、変数userがどの型でどう定義されているかを解決する必要があります。これはtree-sitter単体だと手が届かない。
そこで、フィールドアクセスの解決にはTypeScript Compiler APIとGeminiを併用しています。tree-sitterで構造を抽出 → TypeScript Compilerで変数や型を解決 → それでも解決しきれない動的なケースはGeminiで推定、という役割分担で精度を上げています。
エッジは21種類定義してあります。
CALLS(関数呼び出し)/EXTENDS(継承)/IMPLEMENTS(interface実装)など、tree-sitterで取れる基本的な構造CALLS_API(caller側)/HANDLES_API(handler側)── API境界EMITS_TO(emitter側)/SUBSCRIBES_TO(subscriber側)── Event境界WRITES_TO/READS_FROM── DB境界- などなど
本当の戦いは、境界エッジ(CALLS_API / HANDLES_API / EMITS_TO / SUBSCRIBES_TO / WRITES_TO / READS_FROM)を取りに行くところからです。
境界ノードの抽出と接合の苦労: 1月〜3月の試行錯誤
通常のコードと違って、境界(APIエンドポイント / DBテーブル / Eventトピック)は、フレームワーク・言語・技術領域・ライブラリ・リポジトリ・書いた人によって、書き方がバラバラです。
同じ「APIエンドポイントを定義する」という意味の処理でも、Expressで書くか、NestJSの@Get()デコレーターで書くか、Fastifyのrouteで書くかで、まったく違うAST形になる。さらに、同じリポジトリの中でも複数パターンが混在することがある。
そして、苦労するのは抽出だけではありません。抽出した境界をgraph上で接合するのもまた面倒です。同じAPIパスやDBテーブル名でも、
- camelCase / snake_case / PascalCaseなどの命名規則の揺れ
- スラッシュの有無 (
/users/me/users/me) - 境界名そのものが変数化されているケース (
${baseUrl}/users/me)
といった揺れが混在します。これらを統一した形に正規化して、callerとhandler、emitterとsubscriber、書き込み側と読み込み側を正しく繋ぎ合わせるのが本当に大変でした。
これを46リポジトリ×多様なフレームワークすべてに対して取りに行く必要がありました。
実際に当時のgit履歴を覗くと、毎週のように新しいparserやdetectorが足され、ノイズフィルタが追加され、概念整理が入っています。ここに1月から3月にかけての主要なcommitを時系列で並べてみます (commit prefixは当初の graph-rag (= ナレッジグラフ + RAG として LLM に供給する基盤、という発想のスタック名) で始まって、2月15日に code-graph に統一されています)。
1月: スタート、そしてtree-sitterだけでは足りないと気付く
- 2026-01-15 ─
feat(graph-rag): add TypeScript parser with tree-sitter── ここからスタート - 2026-01-15 ─
feat(graph-rag): add graph builder with BigQuery storage── BigQueryに書き込む形に - 2026-01-19 ─
feat(graph-rag): add TypeScript Compiler-based variable resolution for field extraction── tree-sitterだけでは変数の型解決ができないことが見えて、TypeScript Compiler APIも併用する形に変更
2月: 多様なフレームワークへの対応とノイズとの戦い
- 2026-02-02 ─
feat(graph-rag): add frontend parser for jQuery/Vanilla JS codebase── jQuery / Vanilla JSのフロントエンドコード - 2026-02-03 ─
feat(graph-rag): add AngularJS Page detection for frontend BFS── AngularJSのページ検出(古いフレームワーク、まだ現役で動いている) - 2026-02-15 ─
refactor(code-graph): consolidate 18 MCP tools into 5 with deep subgraph traversal── ツールが18個に膨らんでいたのを5個に整理(このタイミングでcode-graphという名称に統一) - 2026-02-18 ─
fix(code-graph): reduce graph noise by filtering Type nodes, external lib CALLS, and Storybook files── ノイズ削減: Typeノード / 外部ライブラリのCALLS / Storybookファイルをフィルタ - 2026-02-19 ─
fix(code-graph): extract path aliases from tsconfig paths in addition to make-symlink+fix(code-graph): resolve @alias path imports for CommonJS symlink patterns── path alias解決の苦労: tsconfig pathsとmake-symlink、さらにCommonJSのsymlinkパターン、3通りの仕組みに対応 - 2026-02-19 ─
feat(code-graph): add stop_at=boundary option to trace_connections── 境界で停止するオプション(走査範囲の明示制御 / ノード爆発対策) - 2026-02-21 ─
feat(graph): add typeORM JOIN detection, NestJS decorator parsing, Fetcher API detection── TypeORMのJOIN / NestJSのデコレーター / Fetcher API対応 - 2026-02-21 ─
fix(graph): pass fullFileCode to Redux Axios variable resolver for scope-based extraction── Redux Axiosのvariable resolver修正
3月: 概念整理と細かな精度向上
- 2026-03-08 ─
refactor(code-graph): rename __external__ to __boundary__── 概念整理: 「外部リソース」ではなく「境界ノード」という呼び方に統一 - 2026-03-16 ─
refactor: remove db-dictionary from code-graph stack── DBスキーマ辞書 (テーブル・カラム定義を引けるレイヤー) を別graphとして独立進化 - 2026-03-24 ─
fix(code-graph): infer table names from dynamic variable names── 動的変数名からのテーブル名推定 - 2026-03-24 ─
feat(code-graph): add orphan boundary node cleanup script── 孤立した境界ノードのクリーンアップスクリプト
このタイムラインから見える話
毎週、新しいフレームワークやパターンへの対応が入っています。「境界ノードを取りに行く」という作業は、要するに多種多様な書き方それぞれにparserを足していく作業です。
具体的に登場したフレームワーク / 仕組みだけ並べても、こうなります。
- tree-sitter(TypeScript / JavaScript / Go / Dart (Flutter))
- TypeScript Compiler(variable resolution)
- jQuery / Vanilla JS
- AngularJS
- Express / Koa / Fastify
- NestJS(デコレーターparsing)
- TypeORM(DBのJOIN検出)
- Fetcher API
- Redux Axios(variable resolver)
- path aliasの3通り(tsconfig paths / make-symlink / CommonJS symlink)
単に「TypeScript / JavaScript / Go / Dartなどの静的解析」と言って収まる話ではありません。air-closet系のコードベースは長く動いてきた本番システムの集合体で、各時代のフレームワークが共存しています。それぞれの時代の「ここにAPIエンドポイントがある」「ここでDBを叩いている」「ここでEventを購読している」という意味を、ASTから拾い上げる必要がありました。
なぜそこまで精度にこだわるか
90%の精度では、まったく使い物になりません。
たとえば「このAPIを叩いている処理を全部出して」という用途で90%の精度しか出なければ、10%の処理はAIから見えない。影響範囲を調査するためにcode-graphを使う場合、この見えなかった10%が事故を起こします。
しかも、graphを辿る用途では、ホップごとに精度が累乗で下がります。1ホップで0.9なら、2ホップで0.81、3ホップで0.729、5ホップで約0.59、10ホップで約0.35 ── 数ホップ辿っただけで結果は半分以下です。一方、99%にまで持っていけば、2ホップで0.98、5ホップで0.95、10ホップでも約0.90を保ちます。実用に耐えるかどうかは、まさにこの一桁の差で決まります。
新しい境界パターンが見つかるたびに独自パーサーを書き足し、境界の接続率を99%以上に保つことを目標にしてきました。「全境界」という分母を持てない以上、抽出網羅率を直接測ることは難しいので、実際に毎日測れる指標としては「caller側とhandler側がgraph上でちゃんと繋がっている割合」 = 接続率を使っています。次のセクションでその監視の仕組みを書きます。
境界分析の運用 ── 今も毎日動いている
ここまで作ったcode-graphは、今も毎日動いています。
具体的には、毎日JST 7
境界分析のcronが動いています。やっていることは:- API境界:
CALLS_API(caller側)とHANDLES_API(handler側)を対応付けて、リポジトリを跨いだ接続率を集計 - Event境界:
EMITS_TO(emit側)とSUBSCRIBES_TO(subscribe側)を対応付け - DB境界:
WRITES_TOとREADS_FROMが異なるリポジトリから同じテーブルを参照しているケースを集計(= リポジトリ間の暗黙的なDB依存)
集計結果を毎日比較して、接続率が前回比5%以上劣化していたら、Grafana経由でアラートを上げます。
これは「境界ノードを取れている前提」で初めて成立する運用です。「取れている境界の質」そのものを日次で監視している、というメタな仕組みになっています。接続率で拾える種類のドリフト ──「parserが新しいパターンに対応できておらず境界の一部が見えなくなった」「リポジトリの構成が変わってpath aliasが解決できなくなった」── は、翌朝には検知できる状態になっています。一方で接続率では拾えないドリフト(caller 側 parser のリグレッションで caller がまるごと消えた場合、handler は残っている他の caller と「繋がっている」 ように見えてしまい、消えた caller は静かに落ちる)は別軸で、リポジトリ / パターン別の絶対ノード数を日次比較してカバーしています。
それでも残る課題
ここまでやっても、いくつか根本的に解けない課題が残ります。
1. セマンティック検索ができない(入口の問題)
検索MCPツールは、LIKEによる文字列部分一致のみです。
開発中で「いま自分が見ている関数の繋がりを辿りたい」ような場合は、その関数名やファイル名で直接引けるので、これでも問題ありません。
問題になるのは、本番のバグやお客さまからの問い合わせを調査するときです。関連するコードのファイル名や関数名なんて、最初は分からない。「会員のサブスク料金計算が間違っているらしい」という入力から関連コードを辿りたいときに、自然言語クエリでgraphを引けないと、そもそも入口が見つけられない。
「コードベース全体をgrepで検索するのではなく、graph RAGで関連性を辿れる」という目論見だったのですが、入口でgrepして推論せざるを得ない構造になっています。
2. ノード爆発
tree-sitterでASTを素直にグラフ化すると、builtin functionや無名関数、内部utilityまで全部ノードになります。実用上は不要な「このmap呼び出し」「この内部helper」まで全部ノード化されてしまう。
ある起点ノードから関連ノードを辿る走査をかけると、数ホップでhelperや型やprimitiveを巻き込んでノード数が爆発します。「関連性で絞る」ための軸が、グラフ構造の中にありません。
走査を境界ノードで止めるような明示制御で運用上は逃げていますが、根本対処ではありません。
3. 関数の中身は結局ファイルを見ないと分からない
graphで「ここに何かある」「ここから別のrepoの処理を呼んでいる」までは分かります。でも「この関数が具体的に何をしているか」は、結局ファイルを開いて読まないと分からない。
graph単体では時間がかかります。後に作ったコードベース調査ツールでは、graphから候補ファイルを絞った上でGit Server MCP経由で実際のファイルを読ませる、という形で逃げていますが、graph単体での解像度の限界はそのまま残ります。
4. 新しい境界パターンが出るたびにparserを書き足す運用負荷
フレームワーク / ライブラリが新しく入るたびに、「そのフレームワークでは境界をこう書く」を学んでparserを書き足す必要があります。
すでにparserディレクトリには10個以上の独自detector / extractorが並んでいます。維持と拡張のコストが下がる兆候はなくて、新しい技術スタックがコードベースに入ってくるたびに同じ作業を繰り返すことになります。
補足: 別の場所では別の判断 ── cortexの話
ここまでcode-graphの話を書いてきましたが、補足として、自分は別途、cortexという社内AIプラットフォームを1から作っているプロジェクトを持っています(今は100+ appsの1モノレポ)。
そちらでも最初はcode-graphと同じアプローチを試したのですが、早い段階で見送って、アノテーションベースのナレッジグラフに倒しています。
- 自分が組み立てているモノレポなので、アノテーションを一斉に振る前提が置ける
- JSDocタグでコード自体に意図を書き込み、それをgraph化する設計
- 上記の意図をベクトル化してノードに格納することで、セマンティック検索ができるようにしている
この「意図をコードに書き込んでgraph化する」という判断と、その判断に至るまでの試行錯誤については、別連載で詳しく書いています。興味があれば: AIハーネス連載Part 2(AIのAIによるAIのためのナレッジグラフ)
本番システム側にはアノテーションベースは現実的ではない
そして、今回code-graphで扱っている本番システム側に同じアプローチが取れるかというと、これは無理です。
- 46リポジトリ全てにアノテーションを一斉に振るのは、現実的ではない
- 長年動いている本番システム、複数チームが触っている、フレームワークもバラバラ
- 「コードにアノテーションを入れる」という前提が成立しない
だから、code-graph(静的解析ベース)をbaseにしつつ、別レイヤーで補強する方向に進化させる、という選択を取りました。
この課題をどう解決しようとしているかは、後編で別途説明します。
つづく
前編はここまでです。後編では、上記の課題をどう乗り越えようとしているかについて書く予定です。
「捨てた」のではなく「進化させた」、というのが本当のストーリーです。
長文をお読みいただきありがとうございました。
comments (0)
まだコメントはありません。