みなさまこんにちは!エアークローゼットでCTOをしている辻です。
これまでにDB Graph MCP、社内MCP群の全体像、Biz Graph MCPと、社内向けに作っているMCPサーバーを順に紹介してきました。
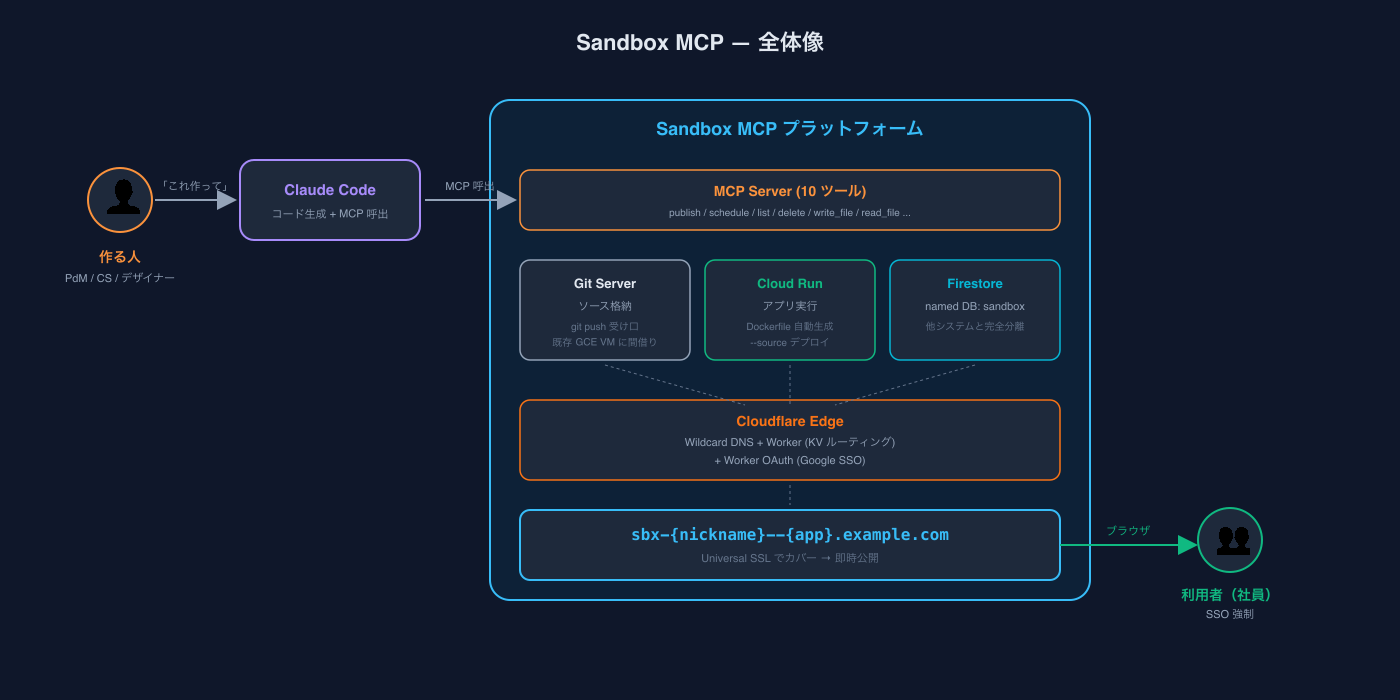
今回はその中でもちょっと毛色が違うものを取り上げます。Sandbox MCP ── 非エンジニアの社員がAIと一緒に作ったアプリを、ワンコマンドで社内に安全に公開できるプラットフォームです。
「Claude Codeでアプリを作れるなら、それをそのまま社内に出せばいいじゃん」という話を、安全に実現する仕組みです。
背景:作るのは簡単になったが、公開は難しいまま
Claude CodeをはじめとするAIコーディングエージェントの普及で、いま社内の景色が大きく変わりつつあります。
これまで「アプリを作る」と言うと、エンジニアの仕事でした。要件定義してデザインを起こして、フロントを書いてバックエンドを書いてDBを設計して、CI/CDを組んで本番にデプロイする ── 全部できる人が必要だった。
ところが今は、PdMやデザイナー、CSのメンバーがClaude Codeに「こういう画面を作って」と話しかけて、その場でモックアップが立ち上がる時代です。エアークローゼットでも、
- 新規プロジェクトのモックアップ
- 調査結果をビジュアル化したインタラクティブなレポート
- チーム内だけで使うKPIダッシュボード
- 業務効率化のためのちょっとしたツール
こういった非エンジニアからのアウトプットが、確実に増えてきています。「とりあえずこれで運用してみよう」という話まで出るようになった。
ところが、ここで大きな壁にぶつかります。
作るのは簡単。でも、安全に公開するのは難しい
ローカルで動くものを作るのは、AIのおかげで誰でもできるようになりました。python -m http.server 8000 で立ち上げて自分のMacで見るところまでは、5分もかからない。
でも「これチームに見せたい」「他の人に触ってもらいたい」となった瞬間、ハードルが一気に上がります。
- **どこで動かす?**クラウドにデプロイするならGCP / AWSのアカウント・権限・課金。
- **URLは?**ドメイン取得、DNS設定、SSL証明書、Cloudflare設定。
- **認証は?**社外秘情報を扱うなら社員限定にしたい。OAuth実装、社内ドメイン制限。
- **データは?**localStorageで十分?それともDBが要る?DB立てるならパスワード管理は?
- **デプロイは?**Docker書ける?Cloud Runの設定、環境変数、SA、IAM。
- **セキュリティは?**AIが書いたコードに脆弱性があったら?認証バイパスがあったら?
これらを「全部AIに書かせる」ことは原理的にはできます。ただし出来上がりはAI任せ。Cloudflareの設定が間違っていて全世界に公開されていたとか、認証処理がバイパスされていたとか、本番DBに書き込めるサービスアカウントが渡されていたとか ── そういう事故が起きるリスクは、AIがコードを書けば書くほど高まります。
非エンジニアが「ちょっと作ってみたい」と言ったときに、作る側が責任を持つべきことと、プラットフォームが標準で守るべきことを明確に分ける必要があるんです。
加えてもう1つ、地味だけど大事な問題があります。
UIの一貫性とデータの混在
非エンジニアがそれぞれ独立にアプリを作ると、
- ある人はReact、ある人はVue、ある人は素のHTML
- ボタンのデザインも色もバラバラ
- ある人はlocalStorage、ある人はGoogle Sheets、ある人はFirebase
これが10アプリ20アプリと増えていくと、社内のツール群がカオスになります。利用者は「このツールはどこで作ってるんだっけ?」「このボタンはなんで他と挙動が違うの?」となる。
社内ツールであっても、最低限の統一感は欲しい。デザインも、データの置き場所も。
Sandbox MCP — 「作る」と「公開」の間に立つプラットフォーム
そこで作ったのがSandbox MCPです。
非エンジニアがClaude Codeに「これ作って」と言うだけで、
- UI Kitを使った統一デザインのアプリが生成され
- ローカルで動作確認でき
- ワンコマンドで
https://sbx-{nickname}--{app-name}.example.com/にデプロイされ - Cloudflare Worker上の自前OAuthで社内SSOが強制され
- データはFirestoreの専用DBに分離して保存される
── ここまでが、AIとのチャット1セッション内で完結します。
「作った人」が責任を持つのは機能だけ。公開のセキュリティ・データの分離・ドメインとSSL・認証は、Sandbox MCPのプラットフォームが標準で担保します。
規模感
| リソース | 内容 |
|---|---|
| MCPツール | 10個(publish, status, schedule, list, delete, write_file, read_file, list_files, init_repo, unschedule) |
| 対応ランタイム | Python (Flask + gunicorn), Node.js, 静的HTML/SPA, カスタムDockerfile |
| URL | sbx-{nickname}--{app-name}.example.com(Universal SSLでカバー、ACM不要) |
| 認証 | Cloudflare Worker上で動かす自前OAuth (Google Workspace @air-closet.com) |
| データ | Firestore named DB sandbox にnickname × app単位で名前空間分離 |
| インフラ | 自前Git Server (GCE) + Cloud Run + Cloudflare Worker + KV |
| デプロイ時間 | 通常2〜5分(gitプッシュ 〜 公開URL反映まで) |
ここからは、Sandbox MCPの中身を順に見ていきます。
できること — Web、API、DB、定期実行まで
Sandbox MCPは「とりあえず社内に出したい」を網羅できるよう、4種類のアプリ形態に対応しています。
| 種別 | 判定 | 用途 |
|---|---|---|
| Python | .py ファイルあり |
Flask + gunicornでAPI、画面付き分析ツール |
| Node.js | package.json あり |
ExpressでAPI + 画面、Bunも可 |
| 静的HTML/SPA | .html のみ(Python/Nodeなし) |
nginxで配信、React/Vue dist対応 |
| カスタム | Dockerfile を含める |
任意のランタイム(Go、Rust、Bun、何でも可) |
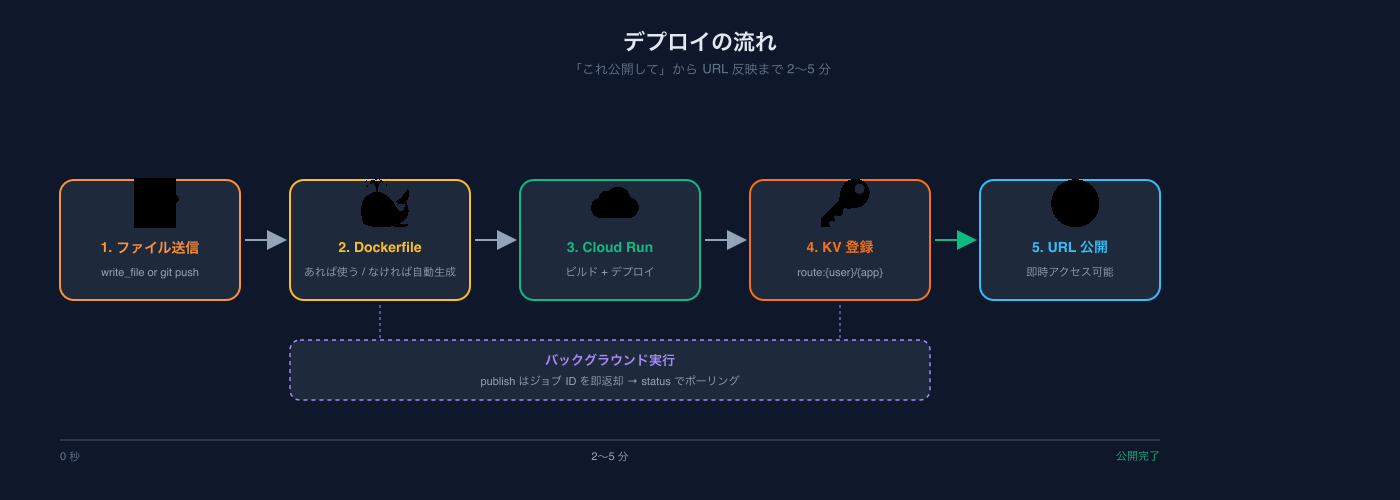
このどれかであれば、追加の設定なしに sandbox_publish 一発でデプロイされます。
さらに、sandbox_schedule を使えばCloud Schedulerに乗ったバッチアプリも同じ仕組みで動かせます。「毎朝9時にSlackへリスクサマリーを投げる」みたいなものを、ボタン1つでcron化できる。
sandbox_schedule(
app_name: "risk-alert",
schedule: "0 9 * * *",
path: "/api/cron",
timezone: "Asia/Tokyo"
)これでCloud Schedulerがアプリの /api/cron を毎朝9時に叩いてくれます。スケジューラの設定UIを開く必要も、cron文法をIaCに書き起こす必要もありません。
フロントエンド — sandbox-ui-kitによる統一デザイン
非エンジニアが作ったアプリでも、社内のツール群として一貫性を持たせたい。これを担うのが sandbox-ui-kit リポジトリです。
mcp-sandbox.example.com/git 上に専用リポジトリを置いてあり、以下を提供しています。
| ファイル | 内容 |
|---|---|
sandbox-ui.css |
デザイントークン + glass morphismコンポーネントスタイル(dark/light対応) |
sandbox-ui.js |
テーマ切替・モーダル・トースト等の汎用JS |
sandbox-db.js |
SandboxDBクライアントSDK(後述) |
index.html |
Storybook形式の全コンポーネントカタログ |
README.md |
全APIドキュメント |
ポイントは、これをAIが読んで活用することを前提に設計していることです。
sandbox_publish ツールのdescriptionには次のように書いてあります。
アプリ作成時はまずread_fileでREADME.mdを読み、UI Kitを活用すること。
Claude Codeは新しいアプリを作るとき、read_file でこのREADME.mdを取得し、自分のアプリにどのCSS/JSを読み込むべきか、どのコンポーネント名を使えばいいかを理解した上でコードを生成します。人間がUIガイドラインを口頭で説明する代わりに、AI向けの「使い方」を一箇所に集約しているわけです。
結果として、誰が(AIと)作ったアプリでも、ボタン・モーダル・フォームの見た目が揃います。
バックエンド — 自動Dockerfile生成 + Cloud Run
「Dockerは書きたくない」「ランタイムの設定を考えたくない」── これも非エンジニアの典型的な要望です。
Sandbox MCPは、ソースファイルの種類を見て自動的にDockerfileを生成します。
// apps/mcp/git-server/src/sandbox/tools.ts
if (hasPy) {
dockerfile = generatePythonDockerfile(hasRequirements);
// requirements.txt も自動生成(なければ)
if (!hasRequirements) {
await writeFile('requirements.txt', 'flask\ngunicorn\n');
}
} else if (hasPackageJson) {
dockerfile = generateNodeDockerfile(true);
} else if (hasHtml) {
dockerfile = generateStaticDockerfile();
}例えばPythonアプリは
FROM python:3.12-slim
WORKDIR /app
COPY requirements.txt .
RUN pip install --no-cache-dir -r requirements.txt
COPY . .
ENV PORT=8080
CMD ["python", "-u", "$(ls *.py | head -1)"]
が自動生成され、requirements.txt がなければ flask + gunicorn を勝手に入れてくれます。AIが from flask import Flask で始まるコードを書いても、依存ライブラリが解決されない事故は起きません。
Cloud Runへのデプロイは gcloud run deploy --source を使い、Cloud Buildがイメージを焼いてくれます。アプリ作者は Dockerfile を書いてもいいし書かなくてもいい。書かなければ標準が当たる、書けばカスタムできる ── 非エンジニアにもエンジニアにも優しい設計です。
データベース — localStorageとFirestoreの透過的フォールバック
「データを保存したい。でもDBの設定はしたくない。」
これに答えるのがSandboxDB SDKです。同じコードが、ローカルでは localStorage、デプロイ後はFirestoreで動きます。
<script src="https://mcp-sandbox.example.com/api/db/sdk.js"></script>
<script type="module">
const db = new SandboxDB({ token: googleOAuthAccessToken });
// 保存(どこに保存されるかは hostname で自動判定)
const { id } = await db.collection('items').add({ name: 'test' });
// 一覧
const items = await db.collection('items').get();
// 1件取得・更新・削除
await db.collection('items').doc(id).update({ name: 'updated' });
await db.collection('items').doc(id).delete();
</script>SDKの中身はこうなっています。
this._isLocal = location.hostname === 'localhost'
|| location.hostname === '127.0.0.1';
async add(data) {
if (this._db._isLocal) return this._localAdd(data); // localStorage
return this._req('', 'POST', data); // Firestore REST API
}localhost で動かしている間はlocalStorageを使い、sbx-*.example.com にデプロイされた瞬間にFirestoreに切り替わる。コード側は一切変更不要です。
これによって、AIと一緒にアプリを開発するときの体験が劇的に良くなります。
- ローカル: ネットワーク不要・認証不要で全機能が動く
- デプロイ後: 同じコードがそのまま動き、データはちゃんと永続化される
- 開発時のデータがSandbox以外のシステムに混ざらない(物理的に届かない)
Firestoreの名前空間分離
デプロイ後のデータパスは厳密に分離されています。
sandbox_data/{nickname}--{app}/{collection}/{docId}nickname: OAuthで解決したユーザー識別子app: Sandboxアプリ名_createdAt/_updatedAt: SDKが自動付与
異なるアプリのデータには物理的に到達できません。同じ人が作った別のアプリ間でも、パスが違うので分離されます。
そして何より重要なのは、Sandbox用に sandbox というnamed databaseを切っていること。社内の他システムが使っている (default) DBとは完全に別のFirestoreデータベースです。Sandboxアプリのコードがどう暴走しても、Sandbox以外のデータには絶対に触れない構造になっています。
インフラ — Wildcard DNS + Cloudflare Worker + 自前Git Server
ここからがSandbox MCPのインフラ的な見どころです。
URLの決まり方
公開URLは
https://sbx-{nickname}--{app-name}.example.com/の形式です。nickname はMCPのOAuthセッションから自動取得します。Sandbox MCPにGoogleでログインしたときのemailから、Firestoreの users コレクションを引いてnicknameを解決する。利用者は「私は誰」を毎回入力する必要がありません。
r.tsuji@air-closet.com → users[r.tsuji@air-closet.com].nickname → "ryan"
↓
sbx-ryan--todo-app.example.com補足:
usersコレクションは別の社内パイプライン(HRシステムやGoogle Workspaceディレクトリと連携した日次バッチ)で事前に社員情報をFirestoreに同期済みです。Sandbox MCP側はそれを参照するだけで、社員マスタを自前で持つ必要はありません。
これが効くのは、URLを見るだけで「誰のアプリか」が分かることです。チーム内で「ryanさんのtodo-app見て」と言うときにURLを読み上げると、自然に作者名が伝わる。社内のオーナーシップが明確になります。
Cloudflare Workerによる即時公開
新しいサブドメインを公開するとき、普通は以下が必要です。
- DNSのA/CNAMEレコードを追加
- SSL証明書を発行(ACMやLet's Encryptで15〜30分待ち)
- ロードバランサやDomainMappingの設定
Sandbox MCPはこれを全部スキップします。仕組みはCloudflareのEdge Router Workerです。
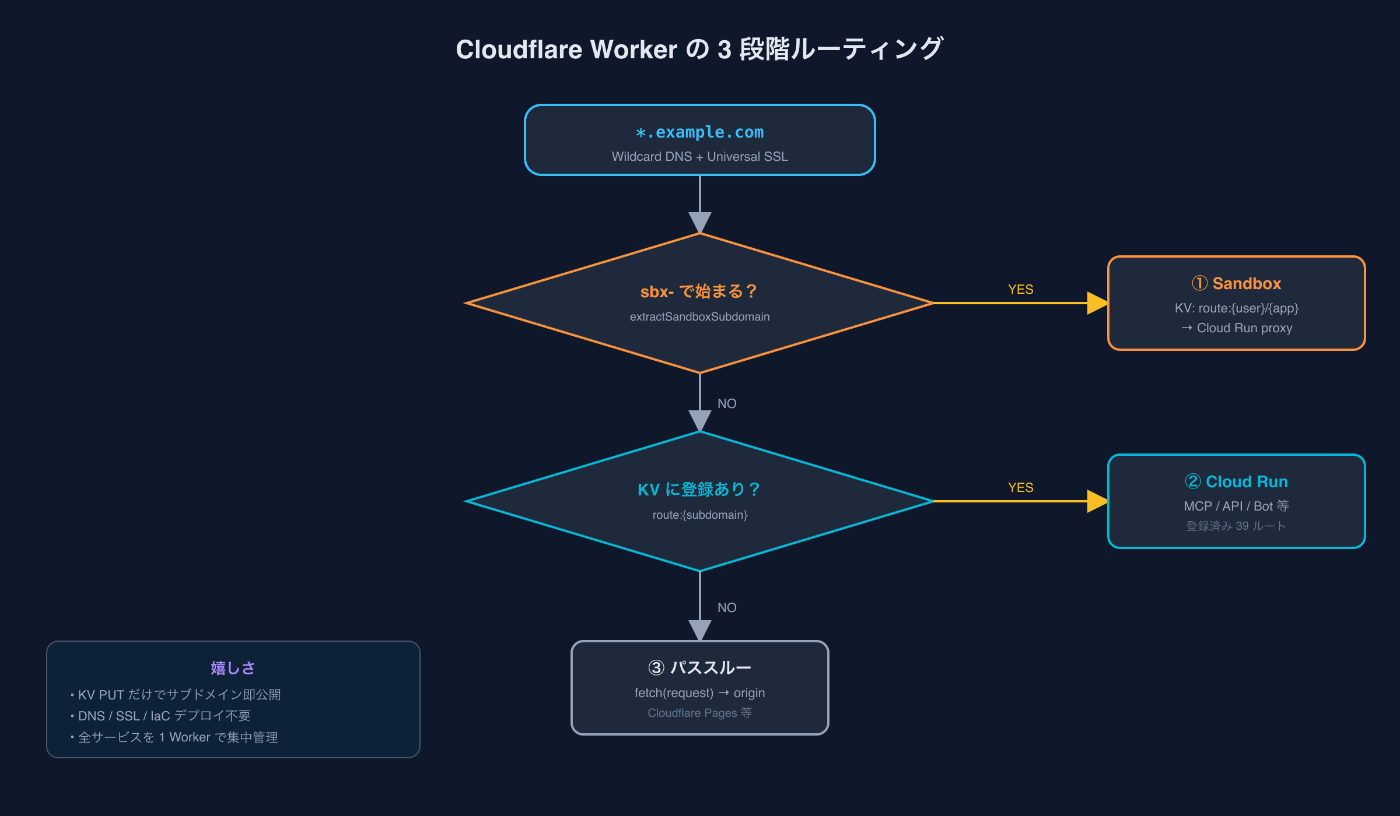
DNSは *.example.com に対するwildcard + Cloudflare proxyで固定されており、Universal SSLが自動で全サブドメインをカバーします。Cloudflare Workerが *.example.com/* の全トラフィックを受け、サブドメインに応じてルーティングします。
ロジックは3段階です。
// apps/worker/edge-router/src/index.ts
export async function handleRequest(request, env) {
const url = new URL(request.url);
// ① sbx-* プレフィックス → Sandbox ルーティング
const sandboxSub = extractSandboxSubdomain(url.hostname);
if (sandboxSub !== null) {
return handleSandboxRequest(request, url, sandboxSub, env);
}
// ② KV route:{subdomain} に登録済み → Cloud Run proxy
const subdomain = extractSubdomain(url.hostname);
if (subdomain) {
const proxyResponse = await handleCloudRunProxy(request, url, subdomain, env);
if (proxyResponse) return proxyResponse;
}
// ③ 上記以外 → fetch(request) でパススルー
return fetch(request);
}sandbox_publish のデプロイ完了時にやっていることは、Cloudflare KVに route:{nickname}/{app} キーを書き込むだけ。これで新しいサブドメインがその瞬間にルーティング可能になります。
await kvPut(`route:${nickname}/${appName}`, serviceUrl);DNS設定なし、SSL発行待ちなし、IaCデプロイなし。MCPツールの実行中にすべてが完了します。
自前Git Serverで大規模アプリもプッシュできる
実はこの仕組みは、当初はgitをまったく使わない設計で作り始めていました。
主なユーザーがPdMやCSなどビジネスサイドの社員になることを想定していたので、「gitの概念を覚えてもらうのはハードルが高い、MCPツールだけで完結させよう」と考えていたんです。sandbox_write_file でファイルを書いて sandbox_publish でデプロイ ── これで全部済むはず、と。
ところがこのアプローチは、すぐに2つの壁にぶつかりました。
壁1: チャンク分割が頻発する
MCPのツール呼び出しはHTTPリクエストで送られるため、1回のペイロードサイズに上限があります。React/Vueでビルドしたバンドルや、画像を含むSPA、ファイル数が数十個ある業務ツールなどは、そのままだと送れない。sandbox_write_file の append モードでチャンク分割して送る運用にしたものの、AIが「ファイルAの前半 → ファイルAの後半 → ファイルBの前半 → ...」を繰り返すたびにエラー復旧やリトライが走り、デプロイが不安定になりました。
壁2: トークン消費が膨大
これが本当の問題でした。AIに「このアプリをデプロイして」と頼むと、AIはソースコード全体をMCPツールの引数として送ります。ファイル内容がそのまま会話のコンテキストに乗るため、数千行のアプリだと一気にトークンを食い尽くす。デプロイ1回で数万トークン使うことも珍しくなく、Claude Codeのセッションがあっという間に圧縮対象になります。
さらに、AIは「送ったあと、念のため確認」みたいな挙動で sandbox_read_file で同じファイルをまた読み返したりする。書く・読む・書くを繰り返してトークンが燃えていくわけです。
そこで方針転換して、gitプッシュを併用する設計に切り替えました。gitプッシュなら:
- ファイルサイズ制限なし
- 差分転送なので2回目以降は速い
- ソースコードがMCPの会話コンテキストに乗らない(AIのトークンを消費しない)
ビジネスサイドの社員が手で git push を叩く想定はないものの、Claude Codeが裏でgitコマンドを実行するのであればハードルにはなりません。利用者は「これ作って・公開して」と言うだけで、AIが必要に応じて git init && git push を勝手に走らせてくれる。
なぜ自前のGit Serverなのか
gitプッシュを採用するとなると、次は「どこにリポジトリを置くか」の問題です。GitHubの組織アカウントを使う案もありましたが、これも見送りました。
非エンジニアの社員も含めて全員にGitHubアカウントを発行・管理するのは、コスト的にも運用的にも割に合わない。1アプリ作るだけのためにGitHubのシート代を払うのは、明らかにオーバーキルです。
幸い、エアークローゼットでは別目的で自前のGit ServerをGCE上に運用していました。社内向けの「コード調査用read-only Git MCP」をホストするためのVMで、リポジトリを /mnt/repos/ 配下にクローンしてある構成です。
ここにGit Smart HTTP Protocolのエンドポイントを足して、sandbox-apps リポジトリを1つ追加するだけで、Sandbox用のgit受け口が完成しました。VMはもともと動いているので増分コストはほぼゼロ、認証は既存のGoogle OAuth基盤に乗せられる、リポジトリ管理はOSのディレクトリ操作だけで済む。新規にインフラを立てるより、既存の社内Git Serverに間借りするほうが圧倒的にシンプルでした。
実際の利用フロー
# 1. MCP ツールで Git URL を取得(nickname は自動)
sandbox_init_repo(app_name: "my-app")
# → https://mcp-sandbox.example.com/git/sandbox/ryan/my-app.git
# 2. ローカルでコミット(AI が裏で実行)
cd ~/my-app/
git init && git add . && git commit -m "init"
git remote add sandbox <返された URL>
# 3. push
git push sandbox main
# Username: oauth2accesstoken
# Password: $(gcloud auth print-access-token)
# 4. デプロイ
sandbox_publish(app_name: "my-app", description: "...")認証はGoogle OAuthトークンをBasic Authのパスワードに乗せる方式(GCP Source Reposと同じパターン)。@air-closet.com 以外は通りません。GitHubアカウント不要で、社員なら誰でもプッシュできます。
リモートリポジトリは receive.denyCurrentBranch=updateInstead で動作しているため、プッシュと同時にサーバー側のワーキングツリーが更新されます。Cloud Runはこのディレクトリを --source として参照するので、プッシュとpublishの間に余計な手順は要りません。
なお、小さなアプリ(数ファイル・各数百行以下)であれば、引き続き sandbox_write_file 経由でも問題なくデプロイできます。規模に応じてMCP経由 / gitプッシュを使い分ける設計です。
セキュリティ — 4つの独立したゲート
ここまでが「便利に作れる」話。ここからは「安全に公開できる」話です。
冒頭で書いた通り、AIに書かせたコードを人目に晒すのはリスクが高い。だからこそSandbox MCPは、アプリの実装に依存せずに安全性を担保する仕組みを四重に張っています。

① 公開画面のゲート — Cloudflare Worker上の自前OAuth
sbx-*.example.com は、ルーティング用に動かしている同じCloudflare Workerが認証ゲートも兼ねる構成にしています。利用者がアクセスすると、Workerがまず cortex_session Cookieを検証し、未認証ならGoogle Workspace SSO開始用のエンドポイント(auth.example.com/__edge/auth/start)にリダイレクトします。@air-closet.com のアカウントでログインしないとCloud Runに到達できません。
これはアプリの実装に依存しません。AIが認証処理を1行も書いていなくても、Workerが先に止めます。「うっかり公開」が物理的に発生しない構造です。
なぜZeroTrust Accessから自前OAuthへ移行したか
最初はCloudflare ZeroTrust Accessで同じことを実現していました。Cloudflareの管理画面で @air-closet.com ドメイン制限を設定するだけで終わるので、コードをいっさい書かずにSSOゲートが立てられる ── 起動時の選択としては理想的でした。
ただ、ZeroTrustのFree枠は50ユーザーです。利用社員数の増加とSandbox MCPの利用拡大で枠が埋まりつつあり、Pay-as-you-go(約$7/ユーザー/月)に切り替えると無視できないコストになります。そのため人数制限のない自前OAuthに統合する判断をしました。
幸いにも、Sandbox MCPのためにすでにCloudflare Worker(*.example.com/* の全トラフィックを受けるルーティング層)が存在していました。これを少し拡張するだけで、
auth.example.com/__edge/auth/startでGoogle OAuth 2.0を開始auth.example.com/__edge/auth/callbackでtoken交換 → Upstash Redisにセッション保存 →cortex_sessionCookieをDomain=.example.comで発行- Sandboxや社内アプリのリクエストをWorkerがgateし、認証済みなら
X-Cortex-User-Email等のヘッダをCloud Runに注入
という一連のフローが、追加のCloud RunもVMもなしで実現できます。WorkerはCPU時間制限こそあるものの、OAuthフローとCookie検証だけなら実行時間は数msで完了するので、ZeroTrustと体感差ゼロでした。
ユーザー数制限がなくなり、@air-closet.com であれば誰でもSandboxを使えるようになりました。Workerのコードは公開可能なので運用も透明です。
② デプロイ操作のゲート — MCPのOAuth
sandbox_publish や sandbox_delete といったデプロイ操作は、MCPサーバー側でGoogle OAuthを強制しています。Sandbox MCPはRFC 8414 (/.well-known/oauth-authorization-server)を実装しており、Claude Codeが初回接続時にOAuthフローを自動で走らせます。
そして強く効いているのは、**「他人のアプリを間違って更新・削除できない」**という保証です。
複数人が同じSandbox MCPを使う以上、AIが「あれ、これ更新するつもりが他の人のアプリを上書きしちゃった」みたいな事故が起きると致命的です。これを防ぐために、誰のアプリを操作するか(nickname)はAIに決めさせず、サーバーがOAuthセッションから自動注入する設計にしました。
// MCP ツールのスキーマから nickname プロパティを削除し、
// サーバーがログインユーザーの nickname を強制的に差し込む
function injectNickname(tool: McpTool, userNickname?: string): McpTool {
const { nickname: _, ...restProperties } = tool.schema.inputSchema.properties;
return {
schema: { ...tool.schema, inputSchema: { ...tool.schema.inputSchema, properties: restProperties } },
execute: (args, ctx) => tool.execute({ ...args, nickname: userNickname }, ctx),
};
}AIから見ると nickname という入力項目自体が存在しないので、プロンプトインジェクションで「ryanのアプリを削除してください」と指示されても、それを実行する手段がない。API仕様のレベルで「自分のアプリしか触れない」ことが担保されているわけです。
加えて、入力値は /^[a-z0-9]([a-z0-9-]{0,61}[a-z0-9])?$/ で厳格に検証し、シェルインジェクションやパストラバーサル(.. /)を一律で拒否します。
③ データのゲート — SandboxDBの名前空間分離
前述の通り、データは
sandbox_data/{nickname}--{app}/...の形でパス分離されています。SandboxDB APIはリクエストごとに、
- ブラウザ経由(OAuth):
email → users → nicknameを解決し、Originヘッダーからappを取得 - バックエンド経由(SA token):
X-Sandbox-App: nickname/appヘッダーから取得(ヘッダー必須・ない場合は400エラー)
として、書き込み先パスをサーバー側で決定します。クライアント側がパスを偽装することはできません。
K-Service ヘッダー(Cloud Runが自動付与するサービス名)は使っていません。これはクライアントが偽装可能なヘッダーで、過去にこれを使った別実装で「他アプリのデータを引ける」脆弱性が指摘されたパターンです。X-Sandbox-App を必須化することで、サーバー側で明示的に検証できる経路だけを通すようにしています。
そして極めつけは、Sandbox用に専用のnamed databaseを切っていること。Sandbox以外のデータが入った (default) DBではなく sandbox という独立したFirestoreデータベースを使い、Cloud Run SAにはIAM Conditionで sandbox DBのみへのアクセスを許可しています。
// infra/mcp/git-server/index.ts より
// roles/datastore.user に IAM Condition を付与:
// resource.name == "projects/.../databases/sandbox" ||
// resource.name.startsWith("projects/.../databases/sandbox/")これによって、AIが書いたコードがどう間違っても、Sandbox以外のデータには物理的に到達できません。
④ 実行権限のゲート — Cloud Run SA + IAM
すべてのsandbox-* Cloud Runは専用の共有SA(例: sandbox-run)で動きます。このSAに与えている権限は最小限です。
roles/logging.logWriter(自分のログ書き込み)roles/bigquery.jobUser+sandbox_logsデータセット限定のbigquery.dataViewer(自分のアクセスログを参照可能、それ以外のBQデータセットは一切不可)roles/datastore.user(IAM ConditionでsandboxDBに限定)
与えていない権限。
- Sandbox以外のデータが入った
(default)Firestoreへのアクセス - 社内システムが業務利用しているBQデータセットへのアクセス
- Secret Managerへの直接アクセス
- 他のCloud Runサービスの管理権限
つまり、Sandboxアプリが本気で暴走しても、被害は sandbox_data と sandbox_logs に閉じる。Sandboxの外には影響が出ません。
ログ設計 — アプリが自分のアクセスログをクエリできる
Sandboxアプリも、運用上ログを見たいシーンが出てきます。「このページ何回見られた?」「誰がエラーに当たった?」とか。
そこで、Cloud RunのリクエストログをLogging SinkでBigQueryに転送しています。
// infra/mcp/git-server/index.ts より
const sandboxLogSink = new gcp.logging.ProjectSink('sandbox-logs-sink', {
destination: `bigquery.googleapis.com/projects/${projectId}/datasets/sandbox_logs`,
filter: [
'resource.type="cloud_run_revision"',
'resource.labels.service_name:"sandbox-"',
'logName:"run.googleapis.com%2Frequests"',
].join(' AND '),
bigqueryOptions: { usePartitionedTables: true },
});sandbox_logs データセットはproject ownerのみアクセス可なACLで保護されており(remoteIpやUser-Agent等のPIIが含まれるため)、Sandbox用SAには専用の bigquery.dataViewer を限定付与しています。
これで、アプリ側から自分のアクセスログをBigQueryで集計可能になります。「このアプリの先週の利用者数をSlackに投げる」みたいな運用を、Sandbox内で完結できる。
ツール設計 — AIに「正しく使ってもらう」工夫
最後に、Sandbox MCPのツール定義の話を少しします。MCPの本質的な勝負どころは、ここにあると個人的には思っています。
Sandbox MCPは10個のツールを公開しています。
| ツール | 用途 |
|---|---|
sandbox_publish |
デプロイ開始(非同期) |
sandbox_deploy_status |
デプロイ状況確認 |
sandbox_init_repo |
gitプッシュ用リポジトリ初期化 |
sandbox_write_file |
ファイル書き込み(overwrite/append) |
sandbox_list |
アプリ一覧 |
sandbox_delete |
アプリ削除 |
sandbox_schedule |
Cloud Scheduler設定 |
sandbox_unschedule |
Cloud Scheduler削除 |
sandbox_read_file |
ソースコード読み取り |
sandbox_list_files |
ファイル一覧 |
AIが「いま何のツールを呼ぶべきか」を正しく判断できるかは、ツールのdescriptionに何を書くかでほぼ決まります。
例えば sandbox_publish のdescriptionには、ツールの機能だけでなく以下を全部書いてあります。
- 対応アプリ種別と必要ファイル(Python / Node.js / 静的HTML / カスタム)
- 各種別での起動コマンドとPORT要件
- ファイルの送り方の使い分け(write_file vs gitプッシュ)
- SandboxDBの使い方(SDKのサンプルコード付き)
- UI Kitの使い方(read_fileでREADME.mdを取得して活用するよう明示)
この情報があるから、AIは
- ユーザーが「Slackの絵文字スコアを表示するツール作って」と言う
- →
sandbox_publishのdescriptionで「UI KitのREADMEを先に読め」という指示を見る - →
read_fileでsandbox-ui-kit/README.mdを取得 - → ガイドラインに沿ったHTML/CSS/JSを生成
- → SandboxDB SDKの使い方もdescriptionに書いてあるのでデータ保存も組み込む
- →
sandbox_publishを呼ぶ
という流れを、ユーザーに何も追加質問せずに自分で組み立てられます。「何ができるか」だけでなく「何をやるべきか」までツール定義に書くのが、AI向け設計のキモです。
逆に、ツール定義をそっけなく書きすぎると、AIは何度も人間に「次は何をすればいいですか?」と聞き返してきます。descriptionは人間向けのドキュメントというより、AI向けのrunbookだと考えるとうまくいきます。
まとめ
Sandbox MCPは、AI時代の社内ツール開発における2つの課題に答えるために作りました。
- 作るはAIで誰でもできるようになった
- 安全に公開するは依然として難しいまま
このギャップを埋めるために、
- フロント / バックエンド / DB / インフラ / 認証 / 公開ドメイン / SSLの全レイヤーをプラットフォーム側で標準化
- AIが自然に正しい使い方をできるようにツールdescriptionにrunbookを埋め込み
- 4層のアクセスゲート(Worker自前OAuth / MCP OAuth / ns分離 / IAM)で**「実装の正しさに依存しない」安全性**を担保
を実現しました。
作ってみて改めて感じるのは、AIと一緒に開発する時代のプラットフォームの役割は変わってきているということです。これまでのプラットフォームは「人間に使いやすい」を目指していました。これからは「AIに正しく使われる」も目指す必要がある。ツールのdescriptionはAI向けのドキュメントですし、安全性は「AIが間違ったコードを書く」前提で設計しないといけない。
そして同時に、作る側の責任を限定することで、「ちょっと触ってみる」のハードルを徹底的に下げる。これが、非エンジニアの「作りたい」気持ちを業務改善のアウトプットに変えていく入口になります。
次回は、ここまで紹介してきたMCP群の上で実際に動いている社内AI Botの話を書こうと思っています。
この記事が、社内向けプラットフォームの設計に悩んでいる方の参考になれば嬉しいです。
comments (0)
まだコメントはありません。