みなさまこんにちは!エアークローゼットでCTOをしている辻です。
これまでに、社内の全DBを自然言語で検索できるDB Graph MCPと、17台のMCPサーバー群で社内業務をAIに開放したMCPサーバー群を紹介しました。おかげさまでどちらも多くの反響をいただきました。
今回はMCPの話ではなく、もう少し手前の**「社内の情報基盤」**について、私がまず最初に情報化したいと思っていた「会議」の情報化を実現した話です。
Google Meetの録画・文字起こしを、Slackチャンネルに自動共有し、さらに過去の会議内容を自然言語で検索できるようにした仕組みです。
課題:対面コミュニケーションの価値と、失われるコンテキスト
対面のコミュニケーションは、速いし密度が高い。テキストで30分かかる合意形成が、会議なら5分で済むことも珍しくありません。これが会議の最大のメリットです。
でも問題は、会議が終わった瞬間からコンテキストが失われ始めることです。
- 「あの会議で話したあれ、なんだっけ…」
- 「録画はあるけど1時間の動画を見返す気力がない」
- 「議事録どこに書いたっけ」
- 「結局、同じ話を何度もしている」
議事録を書く習慣をつけるのも1つの解決策ですが、正直、全員がきちんと議事録を書き続けるのは難しい。書いたとしても、会話のニュアンスや「あの場の空気感」は失われてしまいます。
**会議は情報の宝庫なのに、活用されていない。**これが本当にもったいない。
作ったもの
この課題を解決するために、以下の4つを自動化するシステムを構築しました。
- Google Calendarからワンクリックで録画Meet作成——Chrome拡張が自動でMeetを作成し、録画・文字起こし・議事録をすべてデフォルトONに設定する
- 会議終了時にSlackに自動通知——終了と同時に通知。数分後に録画・文字起こしのリンクも届く
- 録画・文字起こしの自動権限付与——Slackチャンネルメンバー、会議参加者、Calendar招待者に自動でアクセス権を付与
- 文字起こし&画面共有内容をRAG検索——「先週の定例で話したリリース日程は?」に、Slack Botが答えてくれる
使い方の流れ
Step 1:会議を作成する(約10秒)
Google Calendarの予定編集画面で、Chrome拡張が追加した「AI Fassy Meet」ボタンをクリックします。
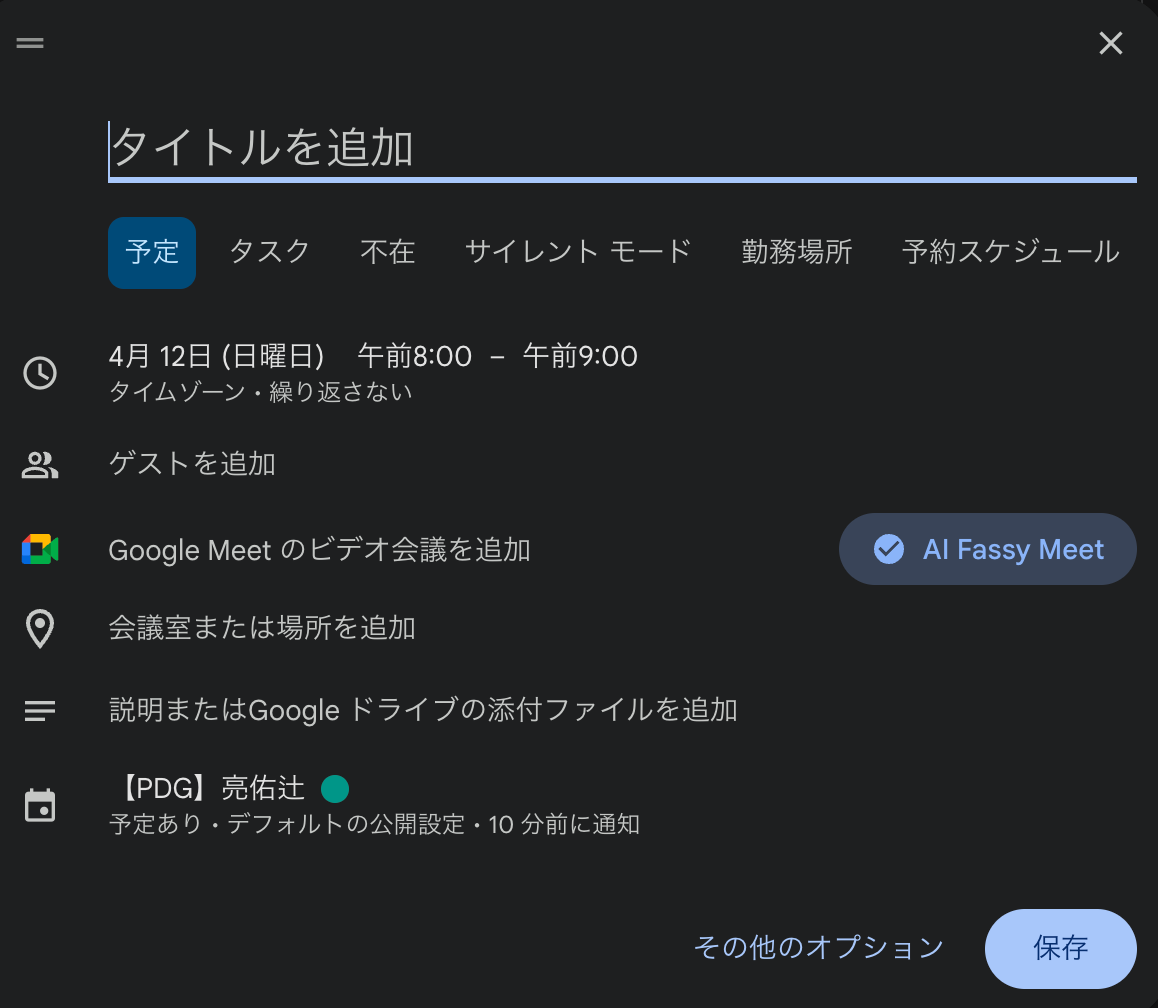 Google Meetのビデオ会議追加の横に、Chrome拡張の「AI Fassy Meet」ボタンが表示される
Google Meetのビデオ会議追加の横に、Chrome拡張の「AI Fassy Meet」ボタンが表示される
通知先のSlackチャンネルを選択します。過去に選択したチャンネルが上位に、よく使うチャンネルがその下に並びます。
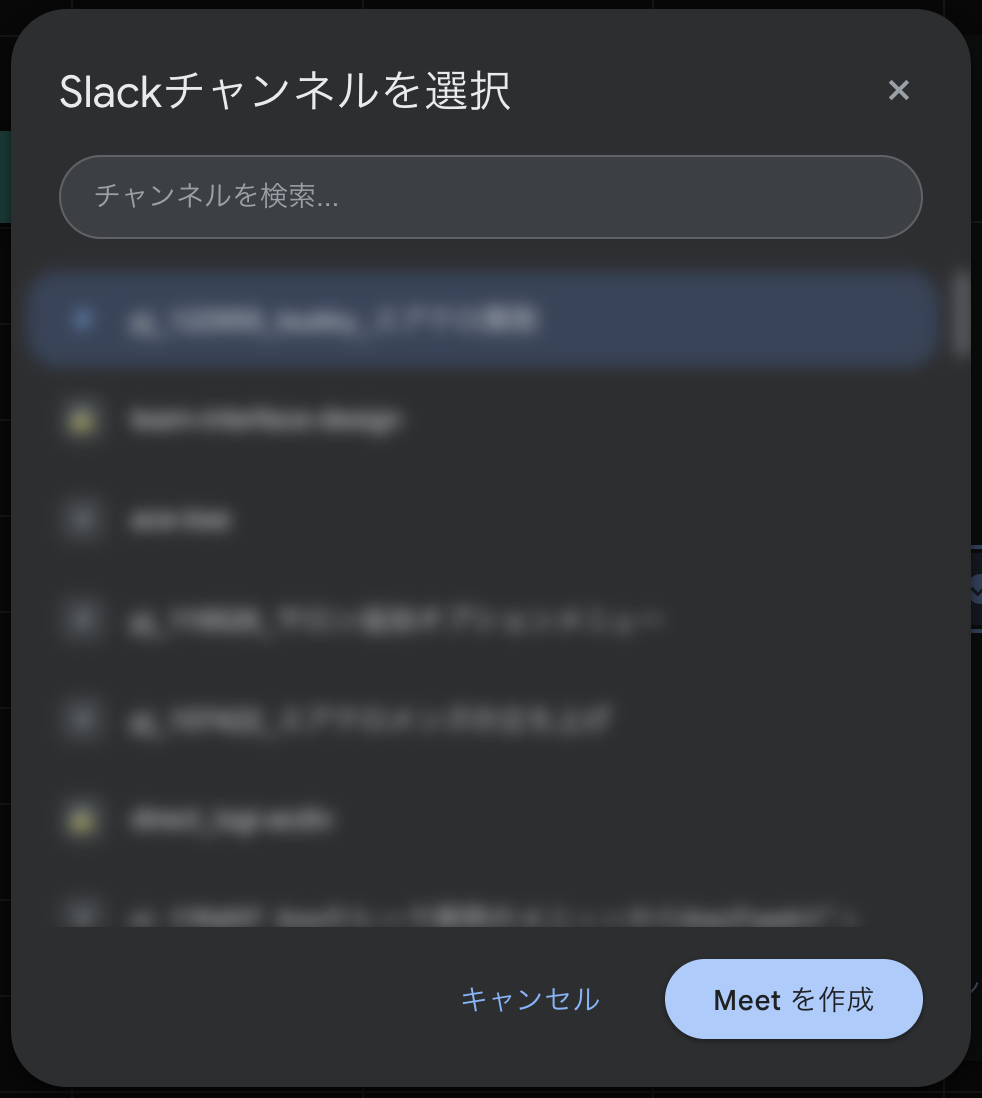 チャンネル検索・選択ダイアログ。選択履歴とアクティビティに基づいてソートされている
チャンネル検索・選択ダイアログ。選択履歴とアクティビティに基づいてソートされている
「Meetを作成」をクリックすると、Meet URLがCalendar予定に自動設定されます。
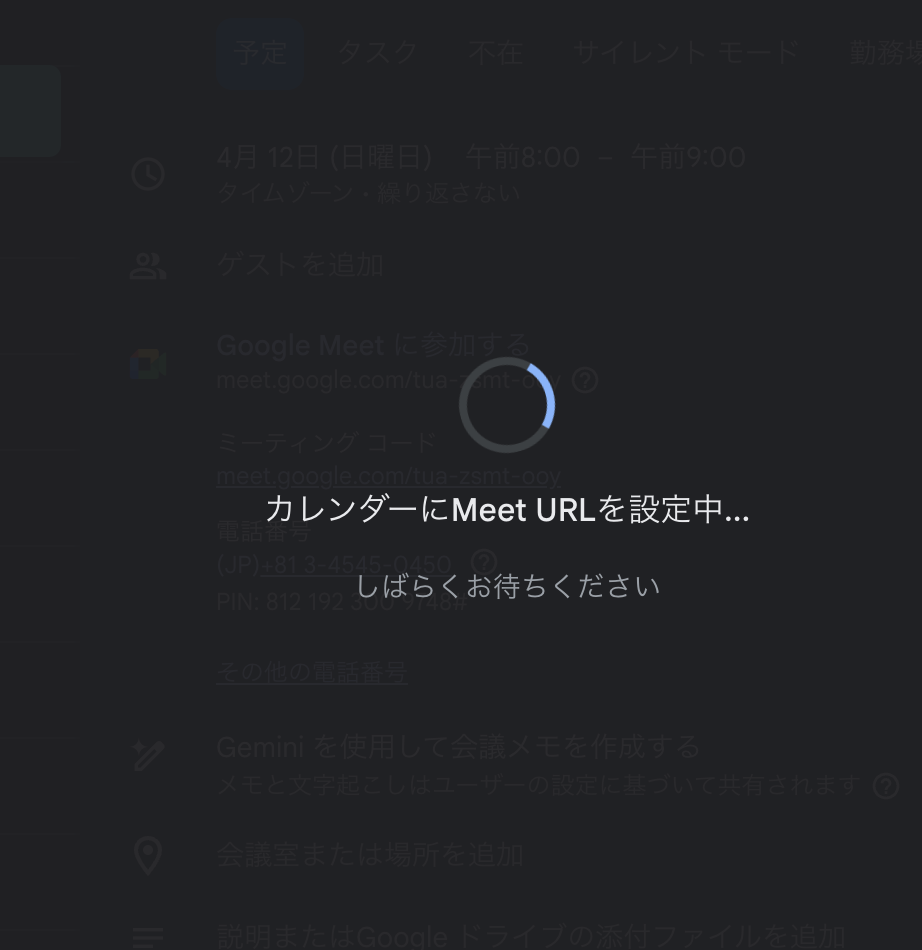 Meet URLが予定に設定され、録画・文字起こし・議事録もすべて自動でONになる。画面に表示されている「Geminiを使用して会議メモを作成する」はGoogle Meet標準の機能で、本システムではこれに加えて独自のGemini 3 Flash連携(文字起こし・画面共有分析)も行っている
Meet URLが予定に設定され、録画・文字起こし・議事録もすべて自動でONになる。画面に表示されている「Geminiを使用して会議メモを作成する」はGoogle Meet標準の機能で、本システムではこれに加えて独自のGemini 3 Flash連携(文字起こし・画面共有分析)も行っている
録画・文字起こし・議事録はすべてデフォルトON。ユーザーが設定を意識する必要は一切ありません。
チャンネル選択のドロップダウンには、過去に指定したことがあるチャンネルが最上位に表示され、次に自分が参加しているチャンネルのうちメッセージのやり取りが多い順で並びます。定例会議なら、前回と同じチャンネルがワンクリックで選べます。
Step 2:会議を実施する
普通にMeetで会議するだけです。裏では自動で録画・文字起こしが走っています。
Step 3:会議が終わると自動で通知が届く
会議が終了すると、指定したSlackチャンネルに「ミーティング終了」の通知が即座に届きます。
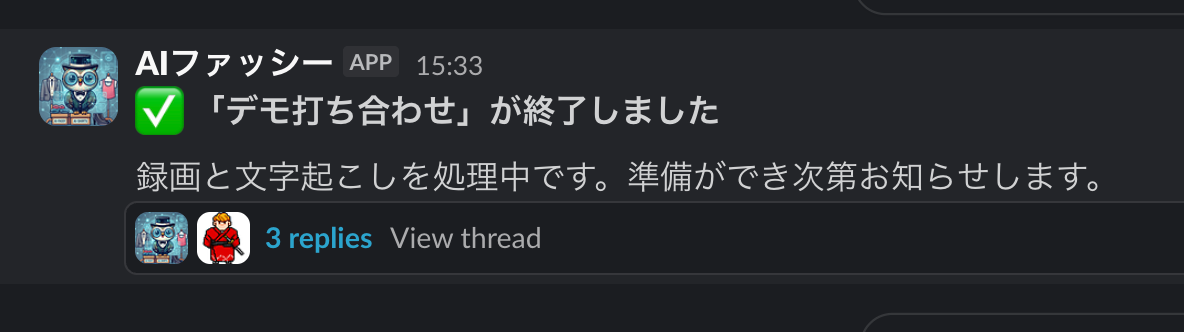 「デモ打ち合わせ」が終了。録画と文字起こしの処理が自動で始まる
「デモ打ち合わせ」が終了。録画と文字起こしの処理が自動で始まる
数分後、録画と文字起こしの準備ができるとスレッドに追加通知が届きます。リンクをクリックすれば、チャンネルメンバーなら誰でもそのまま閲覧できます。
Step 4:過去の会議を自然言語で検索する
同じスレッドで、Botにメンションして会議の内容を質問できます。
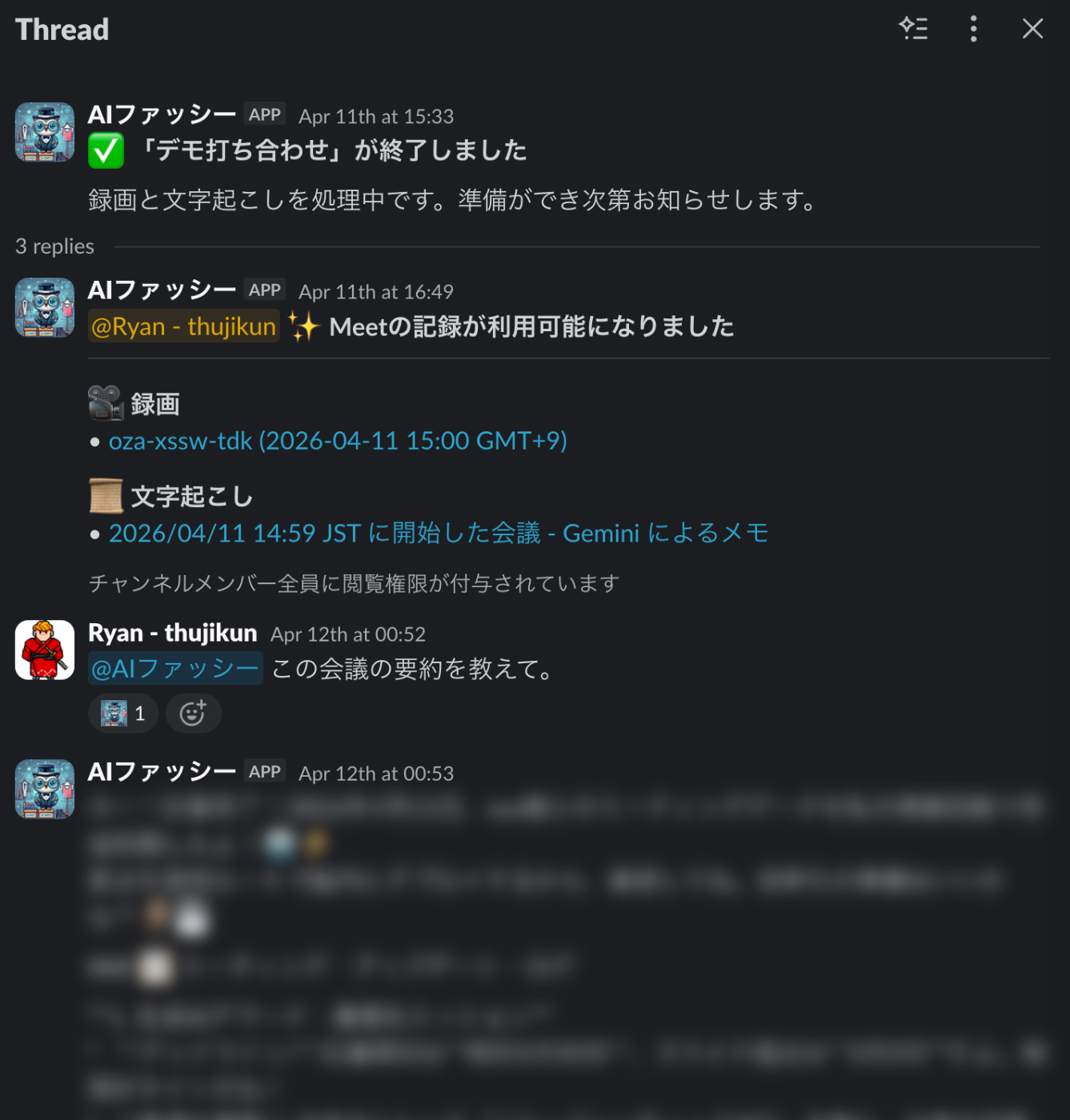 スレッド内の全フロー:①会議終了通知→②録画・文字起こしリンク通知→③ユーザーが「この会議の要約を教えて」と質問→④Botが会議内容を要約して回答
スレッド内の全フロー:①会議終了通知→②録画・文字起こしリンク通知→③ユーザーが「この会議の要約を教えて」と質問→④Botが会議内容を要約して回答
Botが過去の会議の文字起こしを検索して、関連する部分を要約して回答してくれます。出典の会議名とリンクも付きます。画面共有で映していたスライドやコードの内容も検索対象です。
ここからは、「どうやって実現しているのか」を技術的に深掘りします。
アーキテクチャ全体像
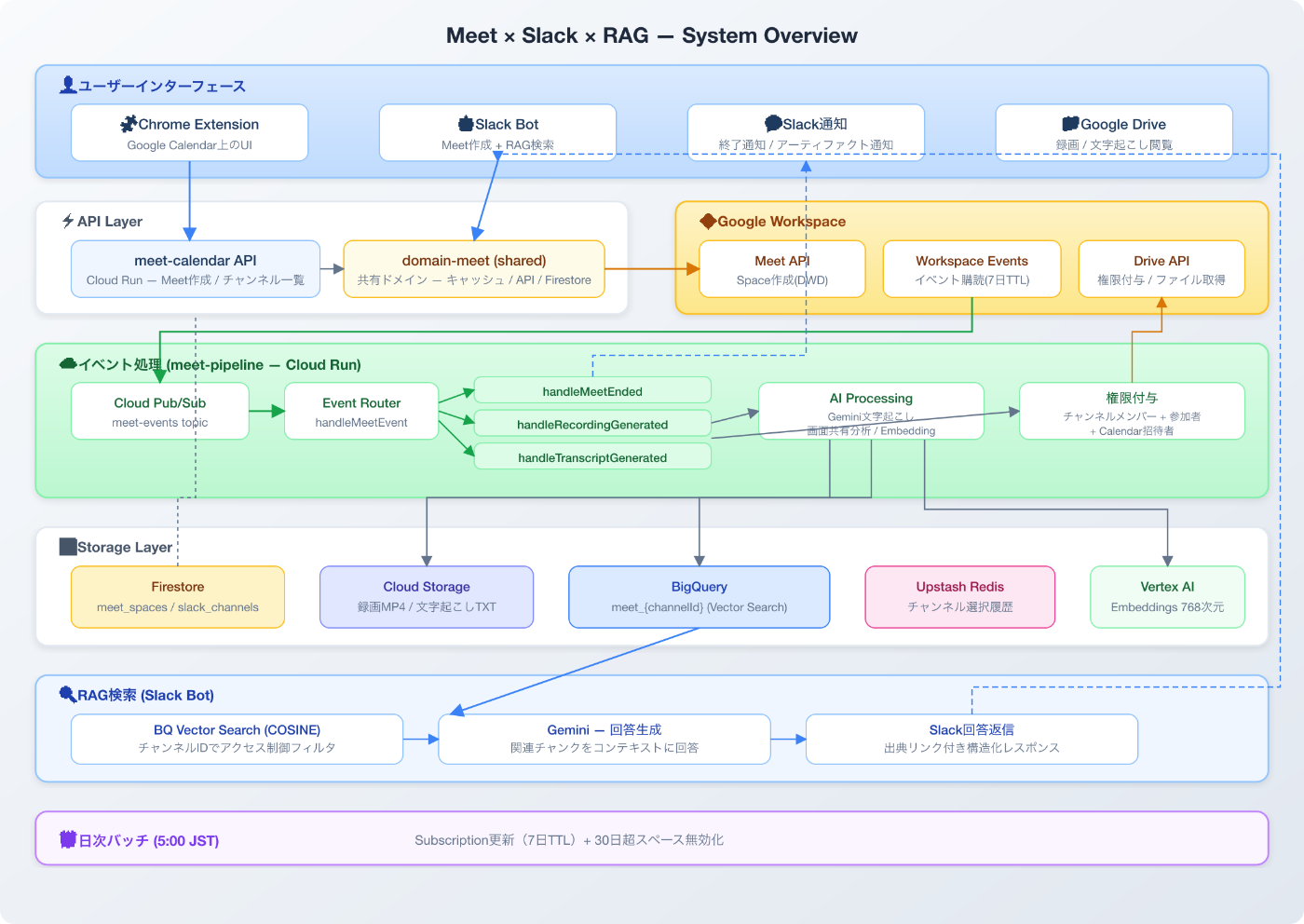
このシステムは4つのコンポーネントで構成されています。
| コンポーネント | 役割 | デプロイ先 |
|---|---|---|
| Chrome Extension+meet-calendar API | Meet作成のUI+バックエンドAPI | Chrome / Cloud Run |
| workspace-pipeline | Workspace Events APIのSubscription管理 | 共有パッケージ |
| meet-pipeline | イベント処理の本体。録画・文字起こしの保存、権限付与、Embedding生成 | Cloud Run |
| Slack Bot | Meet作成+RAG検索 | Cloud Run |
共有ドメインロジック(Space作成、Firestore操作、Driveアクセス、キャッシュ)は共通ドメインパッケージに切り出し、Chrome Extension APIとSlack Botの両方から再利用しています。
技術スタック
| レイヤー | 技術 |
|---|---|
| フロントエンド | Chrome Extension (Manifest V3) |
| API | Cloud Run (Hono) |
| イベント処理 | Cloud Pub/Sub → Cloud Run |
| Workspace連携 | Meet REST API, Drive API, Workspace Events API, Calendar API |
| AI/ML | Vertex AI Embeddings (gemini-embedding-001), Gemini 3 Flash |
| データストア | Firestore, BigQuery, Cloud Storage, Upstash Redis |
| 通知 | Slack Block Kit API |
| インフラ | Pulumi (TypeScript) |
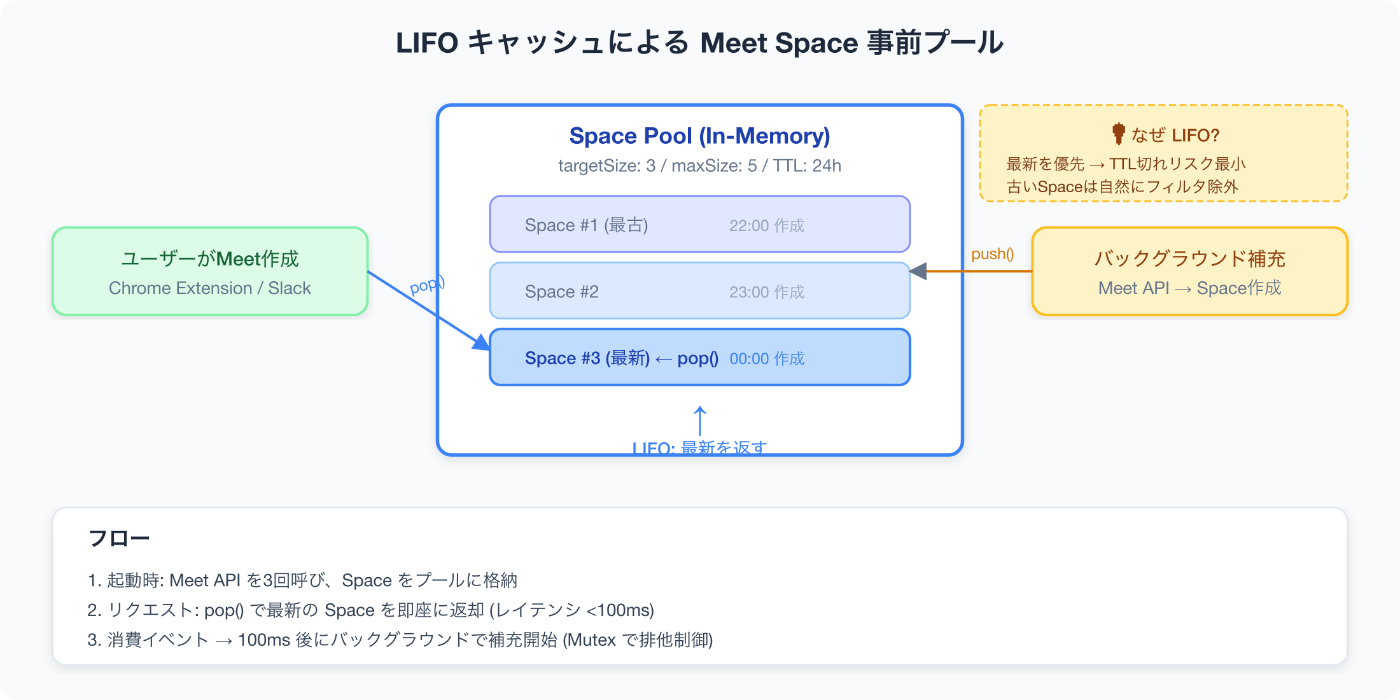
Deep Dive 1:Meet Spaceの事前プール——LIFOキャッシュ
問題:Meet作成が遅い
Google Meet APIで新しいSpaceを作成すると、レスポンスが返ってくるまで1〜2秒かかります。Chrome拡張でボタンを押してから数秒待たされるのは、ユーザー体験として許容できません。
解決:事前に作っておいてプールする
発想はシンプルです。Meet SpaceをAPIで事前に作成しておき、リクエストが来たら即座に返す。消費されたら、バックグラウンドで補充する。
class MeetSpaceCache {
private cachePool: CachedMeetSpace[] = [];
private readonly targetSize = 3;
private readonly maxSize = 5;
private readonly ttlMs = 24 * 60 * 60 * 1000; // 24時間
getMeetSpaceFromCache(): CachedMeetSpace | undefined {
// TTL切れをフィルタしてから、最新をpop
this.cachePool = this.cachePool.filter(s => !this.isExpired(s));
const space = this.cachePool.pop(); // LIFO
if (space) {
this.emitter.emit('spaceConsumed'); // バックグラウンド補充をトリガー
}
return space;
}
}**なぜLIFO(後入れ先出し)なのか?**最新のSpaceを優先的に返すことで、TTL切れのリスクを最小化しています。古いSpaceは自然に放置され、次の pop() 時にTTLフィルタで除去されます。
補充は EventEmitter のイベント駆動です。Spaceが消費されると100msの遅延後にバックグラウンドで replenish() が走ります。Mutex(isReplenishing フラグ)で排他制御し、APIへの同時リクエストを防いでいます。
initializeMeetCache(createSpace) {
this.emitter.on('spaceConsumed', () => {
setTimeout(() => this.replenish(createSpace), 100);
});
// 起動時に初期プールを構築
this.replenish(createSpace);
}これにより、ほとんどのリクエストでレイテンシ100ms以下でMeet URLを返せるようになりました。このキャッシュは共通ドメインパッケージにあり、Chrome Extension APIとSlack Botの両方で共有しています。
Deep Dive 2:「使ってもらえる導線」を作る——Chrome Extensionの設計
最初はSlackコマンドだった
実は、最初に作ったのはSlack上の /meet コマンドでした。Slackでメンションすれば、BotがMeetリンクを返してくれる。技術的には完璧に動きます。
でも、使われなかった。
なぜか。会議の作成フローは「Google Calendarで予定を作る→参加者を招待する→Meet URLを設定する」なのに、Slackコマンドはこのフローの外にあるからです。わざわざSlackに移動して、コマンドを打って、URLをコピーして、Calendarに貼り付ける——これは面倒すぎる。
ユーザーの自然な動線に乗せる
気づいたのは、ユーザーの既存の動線上に機能を配置しなければ使われないということです。
Google Calendarの予定編集画面は、会議を設定するとき全員が必ず通る場所です。ここにボタンを置けば、ワンクリックで完了する。だからChrome Extensionにしました。
Slackコマンドの機能自体は今も残していますし、使う人もいます。でもChrome Extensionにしたことで利用率は劇的に上がりました。
チャンネル選択の最適化
チャンネル選択のUXにもこだわっています。ドロップダウンの表示順は以下のロジックで決まります。
Tier 1:個人の選択履歴(Redis ZSET)
// Redis ZSET に score=timestamp で保存
async saveChannelSelection(userId, channel) {
// 同じチャンネルの重複を除去
await redis.zrem(key, existingMember);
// 最新のタイムスタンプで追加
await redis.zadd(key, { score: Date.now(), member: JSON.stringify(channel) });
// 最大50件に制限
await redis.zremrangebyrank(key, 0, -(MAX_RECENT + 1));
}過去に選択したチャンネルが最上位にきます。定例会議なら、前回と同じチャンネルが常にトップです。RedisのZSETを使い、タイムスタンプをスコアにすることでO(log N)の挿入と自然な時系列ソートを実現しています。
Tier 2:チャンネルの活発度(Firestore sortPriority)
選択履歴がないチャンネルは、Firestoreに事前計算された sortPriority(メッセージ量に基づくスコア)の順で並びます。普段よく使っているチャンネルが上にきます。
2つのソースを並列で取得し、Redisの結果を優先してマージすることで、初回ロードでも実用的なリストを表示できます。
Deep Dive 3:Domain-Wide Delegation——なぜ「裏アカウント」が必要なのか
Google Meetファイルのオーナーシップ問題
Google Meetで録画を有効にすると、録画ファイルと文字起こしファイルは会議の主催者のマイドライブに作成されます。これはGoogle Workspaceの仕様であり、変更できません。
これが大問題です。
主催者ごとにファイルが散らばると、システムから画一的にアクセスできません。録画をGCSにコピーしたり、文字起こしをBQに投入したり、チャンネルメンバーに権限を付与したり——これらの自動処理を行うには、ファイルへの確実なアクセスが必要です。しかし主催者が毎回異なると、誰のDriveにファイルがあるのかを追跡し、その人のOAuthトークンを管理しなければならない。運用として破綻します。
解決:共通サービスアカウントによるImpersonation
Domain-Wide Delegation(DWD)を使って、サービスアカウントがWorkspace管理者として振る舞う仕組みにしています。
const auth = new google.auth.JWT({
email: serviceAccountEmail, // サービスアカウント
key: privateKey,
scopes: [
'https://www.googleapis.com/auth/meetings.space.created',
'https://www.googleapis.com/auth/drive',
],
subject: workspaceAdminEmail, // この管理者として振る舞う
});subject に指定したWorkspace管理者のアカウントでAPIが実行されるため、Meet Spaceの作成もDriveファイルのオーナーシップも、この共通アカウントに集約されます。
Space作成時には artifactConfig で録画と文字起こしをデフォルトONにしています。
body: JSON.stringify({
config: {
accessType: 'TRUSTED',
entryPointAccess: 'ALL',
artifactConfig: {
recordingConfig: {
autoRecordingGeneration: 'ON', // 録画:デフォルトON
},
transcriptionConfig: {
autoTranscriptionGeneration: 'ON', // 文字起こし:デフォルトON
},
},
},
}),ユーザーが会議のたびに「録画をONにし忘れた」ということが起きません。このシステム経由で作ったMeetは、必ず録画・文字起こしされます。
メリット:
- ファイルは常に同じアカウントのDriveに集約→システムから画一的にアクセス可能
- 個人のOAuthトークン管理が一切不要
- 主催者が誰であっても、同じ認証情報でファイル操作できる
- 一度Workspace Admin Consoleで設定すれば、あとはサービスアカウントのキーだけで動く
設定にはWorkspace Admin権限が必要ですが、最初に一度だけの作業です。
DWDを使ったCalendar検索
会議終了時にSlackへ通知するとき、会議のタイトルを取得する必要があります。しかしMeet APIには会議タイトルの情報がありません。タイトルはCalendar側にしかない。
ここでもDWDが活きます。まず会議の主催者のCalendarを検索し、見つからなければ参加者のCalendarを順番に検索します。
async function searchCalendarEventTitle(meetCode, creatorEmail, participants) {
// 1. まず主催者のカレンダーを検索
const creatorEvent = await searchCalendar(creatorEmail, meetCode);
if (creatorEvent) return creatorEvent.summary;
// 2. 見つからなければ参加者を順番に
for (const participant of participants) {
const event = await searchCalendar(participant.email, meetCode);
if (event) return event.summary;
}
// 3. Firestoreキャッシュにフォールバック
return meetInfo.calendarTitle ?? null;
}DWDなら、任意のユーザーのCalendarを subject を差し替えるだけで検索できます。Calendar共有設定をいじる必要もありません。
Deep Dive 4:Workspace Events API——リアルタイムイベント駆動
ポーリングはしない
「Meetが終了したことをどうやって検知するか」——最初に悩んだポイントです。
定期的にAPIを叩いてステータスを確認するポーリングでは、リアルタイム性に欠ける上にAPI呼び出し数が増えます。
Google Workspace Events APIを使えば、MeetのライフサイクルイベントをPub/Sub経由でリアルタイムに受け取れます。
const subscription = await workspaceEvents.subscriptions.create({
requestBody: {
targetResource: `//meet.googleapis.com/${spaceName}`,
eventTypes: [
'google.workspace.meet.conference.v2.ended', // 会議終了
'google.workspace.meet.recording.v2.fileGenerated', // 録画完了
'google.workspace.meet.transcript.v2.fileGenerated', // 文字起こし完了
],
notificationEndpoint: {
pubsubTopic: `projects/${projectId}/topics/meet-events`,
},
payloadOptions: { includeResource: true },
},
});Meet Space作成時にSubscriptionを作成し、3種類のイベントをPub/Subトピック meet-events に配信します。
7日間の有効期限との戦い
ただし、このSubscriptionには7日間の有効期限があります。これはGoogle APIの制約(最大TTL:604,800秒)で変更できません。放っておくと期限切れになり、イベントが届かなくなります。
これが問題になるのは、たとえば以下のようなケースです。
- 定期予定のMeet——毎週月曜の定例会議。先週作ったMeet Spaceを使い回す場合、次の月曜までにSubscriptionが切れてしまう
- 未来の予定——来週の面談用にMeetを先に作成しておく。作成日から7日を超えると、会議当日にはイベントが届かない
つまり、Subscriptionの自動更新がなければ、定期予定や未来の予定で使えないのです。
日次バッチによる自動更新
対策として、Cloud Schedulerで毎朝5
JSTに日次バッチを回しています。2つのフェーズで処理します。async function renewSubscriptions(): Promise<RenewalResult> {
// Phase 1: 古いSpaceの無効化(更新より先に実行)
// → 無効化対象を先に処理することで、Phase 2の更新対象から除外される
const spacesToInvalidate = await getMeetSpacesNeedingInvalidation(thirtyDaysAgo);
for (const space of spacesToInvalidate) {
await invalidateMeetSpace(space.spaceName); // isValid = false
}
// Phase 2: Subscriptionの更新
const spacesToRenew = await getMeetSpacesNeedingRenewal(sixDaysAgo);
for (const space of spacesToRenew) {
// 新しいSubscriptionを作成(古いものは自動的に期限切れになる)
const newSubscriptionName = await createMeetSubscription(
space.spaceName, subscriptionConfig,
);
await updateMeetSpaceSubscription(space.spaceName, newSubscriptionName);
}
}Phase 1:無効化——meetingEndAt が30日以上前のSpaceを isValid: false にします。会議が終了してから30日経てば、録画や文字起こしのイベントが今さら届くことはありません。無効化することでPhase 2の更新対象から除外され、無駄なAPI呼び出しを削減しています。
Phase 2:更新——subscribedAt が6日以上前(=期限切れの1日前)のSpaceに対して、新しいSubscriptionを作成します。古いSubscriptionは放っておけば自動的に期限切れになるので、明示的な削除は不要です。
Subscriptionのライフサイクル
Day 0: Meet作成 → Subscription作成(TTL: 7日)
Day 6: 日次バッチ → Subscription更新(新TTL: 7日)
Day 12: 日次バッチ → Subscription更新(新TTL: 7日)
...繰り返し...
Day 30+: 日次バッチ → isValid=false → 更新停止この仕組みにより、来月の面談用に今日Meetを作っても、毎日Subscriptionが自動更新されるので当日確実にイベントが届きます。定期予定も同様に、同じMeet Spaceを何週にもわたって使い回せます。
Deep Dive 5:イベント処理パイプライン
Meet終了からSlack通知、そしてRAG検索用のベクトルデータ生成まで、すべてはPub/Subメッセージの受信から始まります。
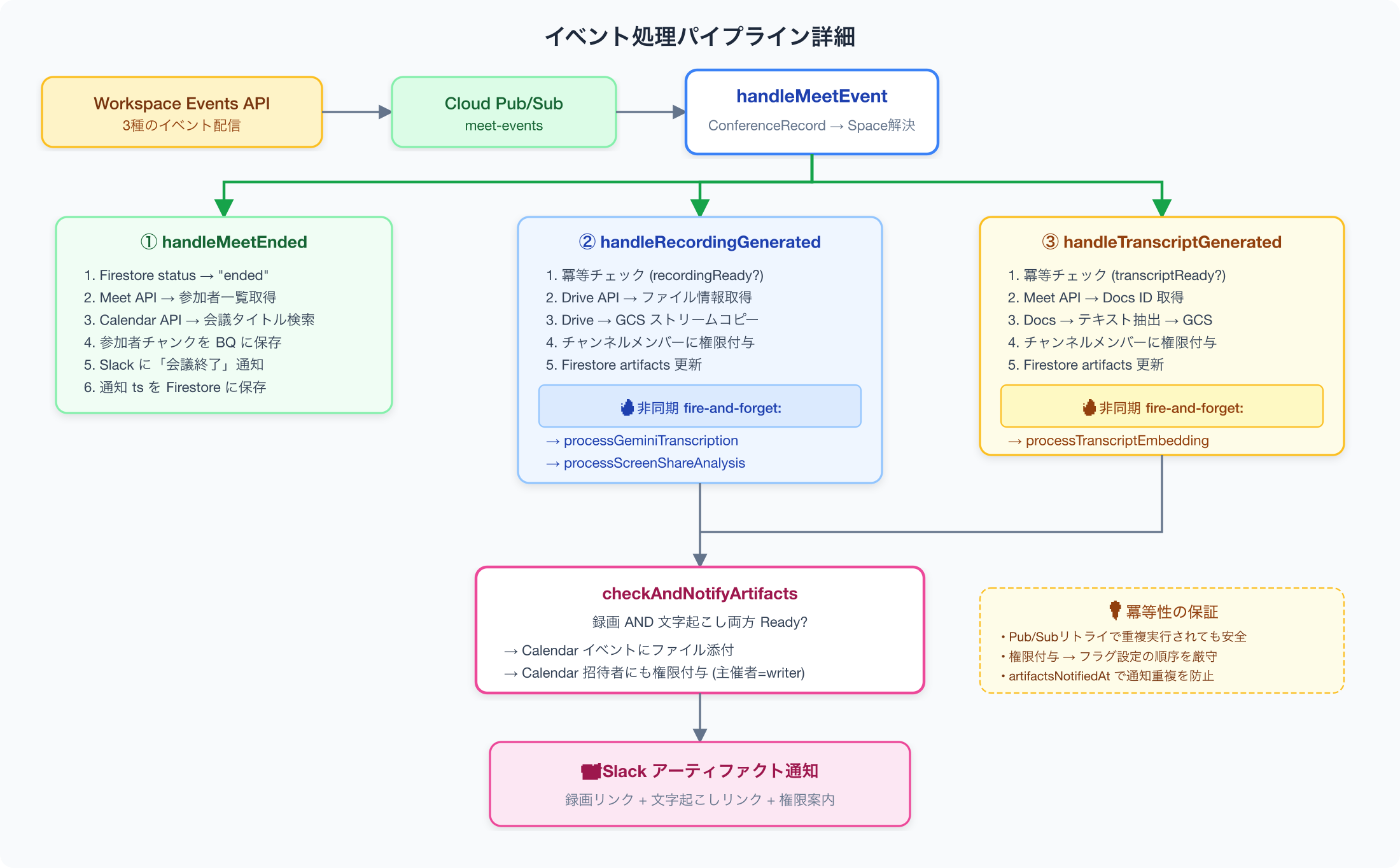
Event Router:3つのハンドラへの振り分け
async function handleMeetEvent(pubsubMessage) {
const eventType = pubsubMessage.attributes?.['ce-type'];
const spaceName = normalizeSpaceName(pubsubMessage.attributes?.['ce-subject']);
// Firestore からスペース情報を取得
const meetInfo = await getMeetSpaceInfo(spaceName);
switch (eventType) {
case 'google.workspace.meet.conference.v2.ended':
return handleMeetEnded(meetInfo, pubsubMessage);
case 'google.workspace.meet.recording.v2.fileGenerated':
return handleRecordingGenerated(meetInfo, pubsubMessage);
case 'google.workspace.meet.transcript.v2.fileGenerated':
return handleTranscriptGenerated(meetInfo, pubsubMessage);
}
}1つ注意点があります。Pub/Subイベントの targetResource には spaceName ではなく conferenceRecordId が含まれることがあります。Google Meetは同じSpaceで複数回会議を開催でき、会議ごとに異なる conferenceRecordId が割り当てられるためです。その場合はMeet APIで conferenceRecordId → spaceName の解決を行っています。
① handleMeetEnded:会議終了時
会議終了時に以下を実行します。
- Firestoreのステータスを
endedに更新 - Meet APIから参加者一覧を取得
- Calendar APIで会議タイトルを検索(DWDで参加者のカレンダーを順番に検索)
- 参加者情報をBQに保存(後のRAG検索で「誰が参加していたか」も検索可能にするため)
- Slackに「会議終了」通知を送信
- 通知メッセージの
ts(タイムスタンプ)をFirestoreに保存→後続の通知がスレッド配下に入る
② handleRecordingGenerated:録画完了時
録画ファイルの処理は最も複雑なハンドラです。
Drive → GCS コピー → 権限付与 → Firestore更新
→ Gemini 文字起こし(非同期)
→ 画面共有分析(非同期)**冪等性が重要です。**Pub/Subは少なくとも1回の配信を保証するため、同じメッセージが重複配信される可能性があります。以下の順序を厳守しています。
async function handleRecordingGenerated(meetInfo, message) {
// 冪等チェック:既に処理済みならスキップ
if (meetInfo.recordingReady && meetInfo.artifacts?.recording?.gcsUri) {
return;
}
// 1. Driveからファイル情報を取得
const fileInfo = await getFileInfo(driveFileId);
// 2. GCSにストリームコピー(存在チェック付き)
if (!(await gcsFileExists(gcsPath))) {
await copyDriveFileToGCS(fileInfo.id, gcsPath);
}
// 3. チャンネルメンバーに権限付与 ← フラグ設定の「前」に実行
await shareFileWithChannelMembers(fileInfo.id, meetInfo.channelId);
// 4. Firestoreにアーティファクト情報を保存
await updateMeetSpaceArtifact(spaceName, 'recording', { driveFileId, gcsUri });
// 5. AI処理は非同期 fire-and-forget
processGeminiTranscription(gcsUri, meetInfo).catch(logError);
processScreenShareAnalysis(gcsUri, meetInfo).catch(logError);
// 6. 両方揃ったか確認 → 揃っていたらSlack通知
await checkAndNotifyArtifacts(spaceName);
}**なぜ権限付与をフラグ設定の前に行うのか?**フラグを先に設定してしまうと、リトライ時に冪等チェックで処理がスキップされ、権限付与が実行されないまま終わってしまうからです。Drive権限付与は冪等(既存権限があればHTTP 400が返るだけ)なので、何度実行しても安全です。
③ handleTranscriptGenerated:文字起こし完了時
構造は録画ハンドラとほぼ同じです。Google Docsの文字起こしをテキストとして抽出し、GCSに保存した後、Embedding生成パイプラインに投入します。
両方揃ったら最終通知+Calendarへの添付
checkAndNotifyArtifacts() は録画・文字起こしの両方がReadyになったタイミングで、以下を実行します。
- Slackにアーティファクト通知を送信
- Calendarイベントに録画・文字起こしファイルを添付
- Calendar招待者への権限付与
2番目がポイントです。通常のGoogle Meetでは、録画・文字起こしが完了するとCalendarの予定に自動的にファイルが添付されます。このシステムではDWDで別アカウントがMeetを作成しているため、その自動添付が機能しません。デフォルトのMeetと同じ体験を損なわないように、明示的にCalendar APIでファイルを添付しています。
async function attachFilesToCalendarEvent(event, artifacts) {
const attachments = [];
if (artifacts.recording) {
attachments.push({ fileUrl: artifacts.recording.webViewLink, title: '録画' });
}
if (artifacts.transcript) {
attachments.push({ fileUrl: artifacts.transcript.webViewLink, title: '文字起こし' });
}
// 既存の添付と重複しないようfileUrlで
const existing = event.attachments ?? [];
const newAttachments = attachments.filter(
a => !existing.some(e => e.fileUrl === a.fileUrl)
);
await calendar.events.patch({
calendarId: organizerEmail,
eventId: event.id,
requestBody: { attachments: [...existing, ...newAttachments] },
supportsAttachments: true,
});
}これにより、Calendarの予定詳細画面からも録画・文字起こしに直接アクセスでき、ユーザーはSlack経由でもCalendar経由でも自然にファイルにたどり着けます。
Deep Dive 6:3層の権限付与モデル
「誰にアクセス権を与えるか」は、このシステムで最も繊細な設計ポイントです。狭すぎると使い物にならず、広すぎるとセキュリティリスクになります。
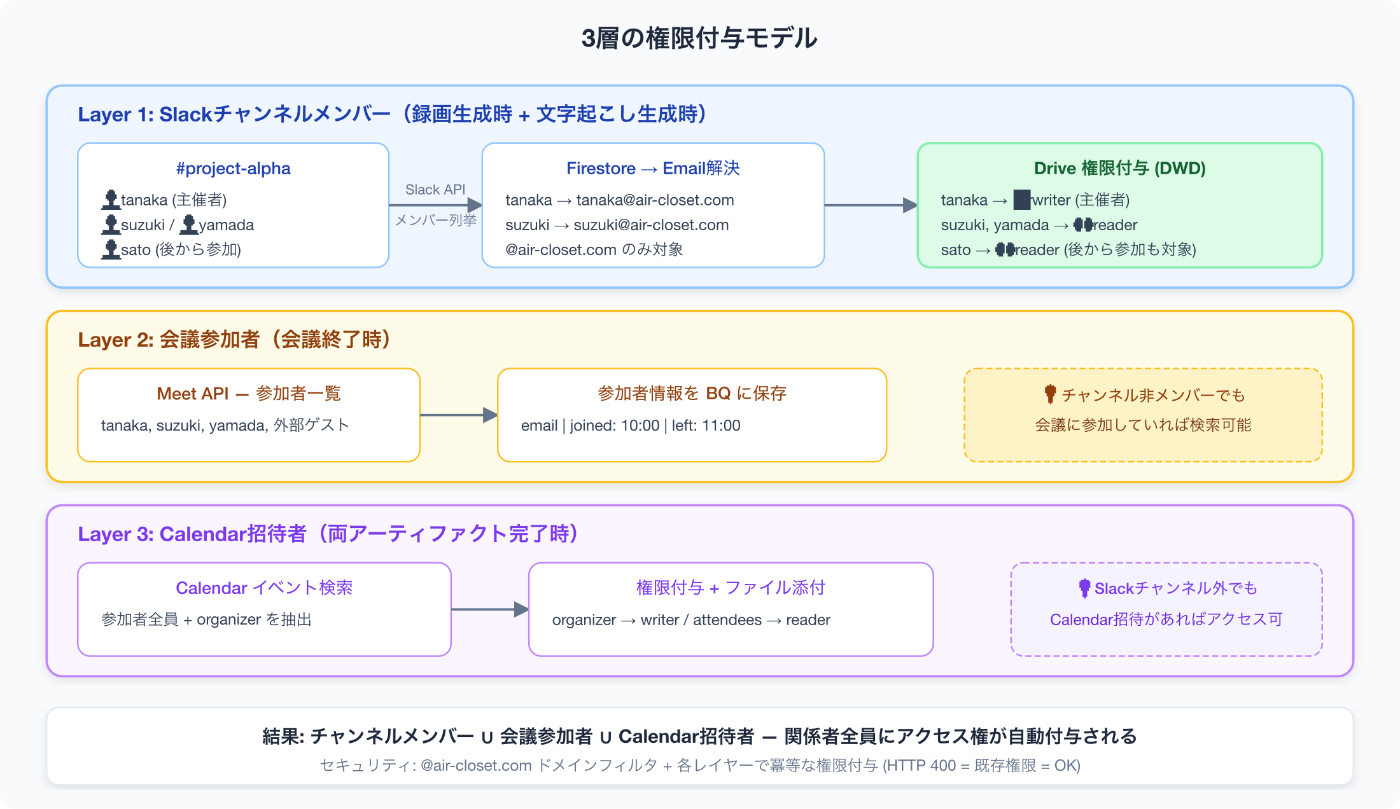
Layer 1:Slackチャンネルメンバー
録画ファイル・文字起こしファイルが生成されるたびに、紐づくSlackチャンネルのメンバー全員にDrive閲覧権限を付与します。
async function shareFileWithChannelMembers(fileId, channelId) {
// Slack APIでチャンネルメンバーを列挙
const members = await getChannelMembers(channelId);
for (const member of members) {
// Slack ID → Firestore → email
const userInfo = await getUserInfo(member);
if (!userInfo.email?.endsWith('@air-closet.com')) continue; // ドメインフィルタ
const role = (member === organizerSlackId) ? 'writer' : 'reader';
await shareFileWithUser(fileId, userInfo.email, role);
}
}重要なのは、後からチャンネルに参加したメンバーにも権限が付与される点です。Pub/Subのリトライで再実行されるたびに最新のメンバーリストで権限付与が走るため、会議中にはいなかったがその後チャンネルに参加した人にも自然とアクセス権がつきます。
主催者だけは writer 権限を付与し、録画ファイルの管理(名前変更、共有設定の変更等)ができるようにしています。
Layer 2:会議参加者
会議終了時に、Meet APIから取得した参加者情報をBQに保存します。参加者はSlackチャンネルに入っていないゲストである可能性もあるため、Layer 1とは別軸での権限管理が必要です。
Layer 3:Calendar招待者
録画と文字起こしの両方が揃ったタイミングで、Calendarイベントの招待者にも権限を付与します。
async function attachToCalendarAndShareWithAttendees(meetInfo, artifacts) {
const event = await getCalendarEventByMeetCode(meetInfo.meetingCode);
if (!event) return;
// Calendarイベントにファイルを添付
await attachFilesToCalendarEvent(event, artifacts);
// 招待者全員に権限付与(organizer = writer、それ以外 = reader)
const emails = event.attendees.map(a => a.email);
await shareFilesWithEmails(artifacts, emails, event.organizer.email);
}Slackチャンネルには入っていないが、Calendarでは招待されている人(例:マネージャーが定例の議事録だけ見たい場合)にもアクセスが届きます。
セキュリティの担保
3層すべてで共通のセキュリティルールが適用されます。
- ドメインフィルタ:
@air-closet.comのメールアドレスのみ対象。外部ユーザーへの共有を防止 - 冪等な権限付与: HTTP 400(既に権限あり)をエラーとして扱わない
- 通知抑制:
sendNotificationEmail: falseで、大量の「◯◯さんがファイルを共有しました」メールを防止
Deep Dive 7:Embedding生成&RAG検索パイプライン
ここが一番やりたかった部分です。
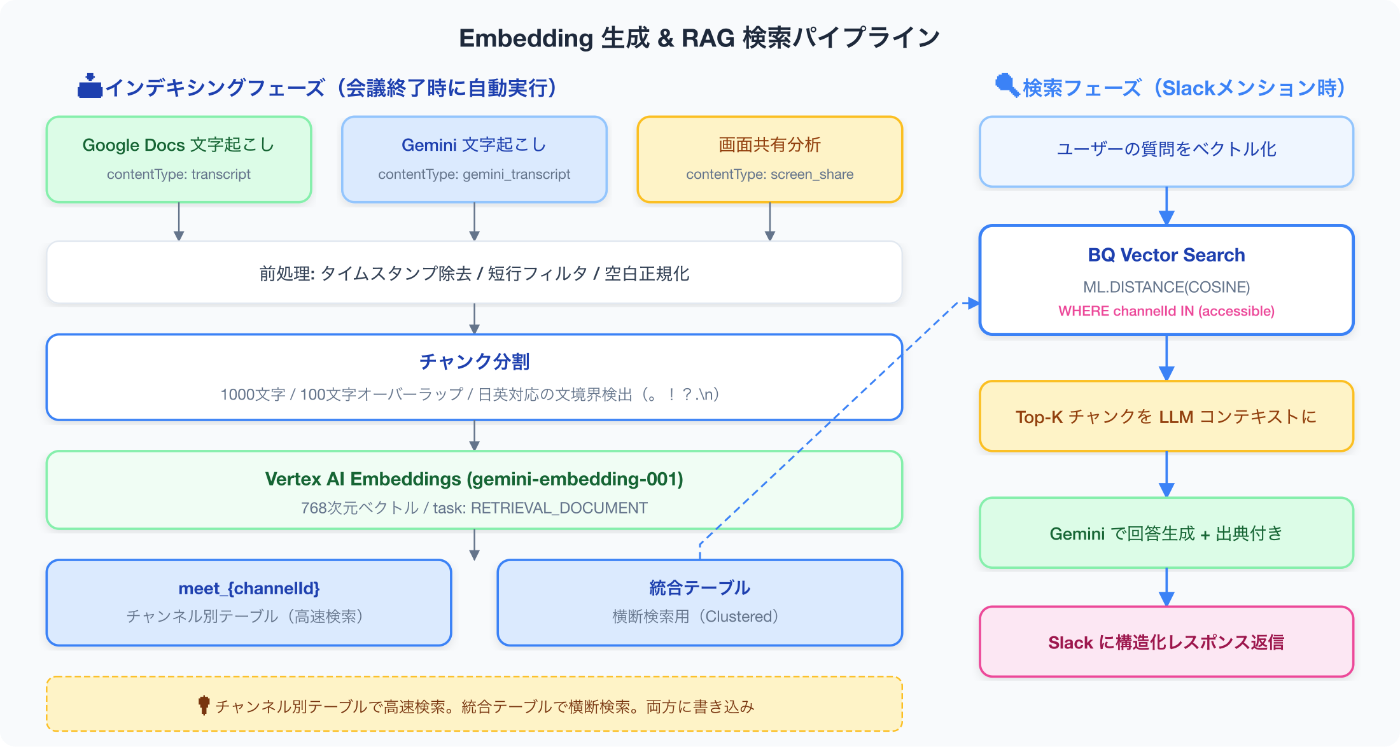
3種類のコンテンツソース
1つの会議から、最大3種類のテキストを抽出し、それぞれベクトル化します。
| コンテンツタイプ | ソース | 用途 |
|---|---|---|
transcript |
Google Meet標準の文字起こし(Google Docs) | 話し言葉のテキスト |
gemini_transcript |
Geminiが録画動画から生成した文字起こし | 標準より高品質な文字起こし |
screen_share |
Gemini Visionが録画から抽出した画面共有内容 | スライド・コード・ドキュメント |
チャンク分割:日本語対応の文境界検出
function chunkText(text: string, chunkSize = 1000, overlap = 100): string[] {
const chunks: string[] = [];
let start = 0;
while (start < text.length) {
let end = Math.min(start + chunkSize, text.length);
if (end < text.length) {
// 文の途中で切れないよう、文末を探す
end = findSentenceBreak(text, end, start + 100);
}
chunks.push(text.slice(start, end));
start = end - overlap; // オーバーラップで文脈をつなぐ
}
return chunks;
}findSentenceBreak() は、チャンク境界から後方に向かって文末を探します。日本語(。、!、?)と英語(. 、! 、? )の両方に対応しており、見つからない場合はスペースや全角スペースでフォールバックします。最低100文字は確保するガードも入っています。
会議の文字起こしは日本語と英語が混在することが多いので、バイリンガルな境界検出は重要です。
Geminiによる画面共有内容の抽出
文字起こしだけでは、画面共有で映していたスライドやコードが検索できません。「あのスライドに書いてあった◯◯」を探したいときに困ります。
Gemini 3 Flash(gemini-3-flash-preview)のマルチモーダル入力で、録画動画から画面共有の内容を直接抽出しています。
async function analyzeScreenShareFromVideo(gcsUri: string): Promise<string> {
const result = await gemini.generateContent({
model: GEMINI_MODEL,
contents: [{
parts: [{
fileData: { mimeType: 'video/mp4', fileUri: gcsUri },
// 文字起こしと違い、映像フレームが必要なので fps を高めに
videoMetadata: { fps: 0.2 },
}, {
text: `この動画で画面共有されている内容を抽出してください。
スライドのテキスト、ドキュメントの内容、
コードなどがあれば書き起こしてください。`,
}],
}],
generationConfig: { temperature: 0.2 },
});
return result.response.text();
}**fpsの使い分けがポイントです。**文字起こしでは音声だけが必要なので fps: 0.1(10秒に1フレーム)にして映像トークンを最小化。画面共有分析では映像内容が重要なので fps: 0.2(5秒に1フレーム)にしています。
長時間の会議で入力トークン上限に引っかかる場合は、自動的に30分ごとのチャンクに分割して処理するフォールバックも入っています。
async function transcribeFromVideo(gcsUri: string): Promise<string> {
try {
// まず全体を一括処理
return await callGemini(gcsUri);
} catch (error) {
if (isTokenLimitError(error)) {
// トークン上限 → 30分チャンクに分割して処理
return await transcribeVideoInChunks(gcsUri, 30 * 60);
}
throw error;
}
}BigQuery Vector Search
ベクトルデータはSlackチャンネルごとのBQテーブル(meet_{channelId})に格納しています。チャンネル単位でテーブルを分けることで、チャンネル内検索時にフィルタ不要で高速にVector Searchが走ります。横断検索用には別途統合テーブルも用意し、channel_id でクラスタリングしています。
async function insertMeetChunks(chunks, meetInfo) {
const channelTableId = `meet_${meetInfo.channelId}`;
// テーブルがなければ自動作成(日パーティション)
await ensureMeetChannelTable(channelTableId);
for (const chunk of chunks) {
await insertRow(channelTableId, chunk);
}
}RAG検索時のアクセス制御
SELECT
chunkText, meetingId, channelId,
ML.DISTANCE(text_embedding, @query_embedding, 'COSINE') AS distance
FROM `meet_chunks`
WHERE channelId IN UNNEST(@accessible_channels) -- アクセス制御
ORDER BY distance
LIMIT 10@accessible_channels は、ユーザーが参加しているSlackチャンネルのID一覧です。自分が参加していないチャンネルの会議内容は、たとえBQに存在していてもヒットしません。
検索結果のコサイン距離は 1 - distance / 2 で0〜1の関連度スコアに変換し、閾値を超えたチャンクだけをGeminiのコンテキストに投入して回答を生成します。
Deep Dive 8:GCS操作の工夫
Drive→GCSのストリームコピー
録画ファイルは数百MBになることがあります。メモリに全部載せるとCloud Runのメモリを圧迫するため、Driveからのダウンロードをそのままストリームでアップロードしています。
async function copyDriveFileToGCS(driveFileId: string, gcsPath: string) {
// Drive APIからストリームで取得
const response = await fetch(
`https://www.googleapis.com/drive/v3/files/${driveFileId}?alt=media`,
{ headers: { Authorization: `Bearer ${token}` } }
);
// GCS JSON APIにストリームで書き込み
await fetch(
`https://storage.googleapis.com/upload/storage/v1/b/${bucket}/o?name=${gcsPath}&uploadType=media`,
{
method: 'POST',
headers: { Authorization: `Bearer ${token}`, 'Content-Type': mimeType },
body: response.body, // ReadableStreamをそのまま渡す
}
);
}GCSファイル構造
gs://bucket/
└── meet/
└── {channelId}/
└── {spaceId}/
├── recording.mp4 # 録画ファイル
├── transcript_original.txt # Google Docs文字起こし原文
├── gemini_transcript.txt # Gemini文字起こし
└── screen_share.txt # 画面共有分析結果チャンネルID→SpaceIDの階層にすることで、チャンネル単位でのデータ管理やライフサイクルポリシーの適用が容易です。GCSのライフサイクルで90日後に自動削除しています(元ファイルはDriveに残っているため)。
Deep Dive 9:Slack通知の設計
2段階通知
ユーザーを待たせないために、通知を2段階に分けています。
第1通知(会議終了直後):
🎬 ミーティング終了
「週次定例会議」が終了しました。
録画と文字起こしの準備ができ次第お知らせします。
作成者: @tanakaこの時点ではまだ録画・文字起こしは準備中です。でもユーザーは「会議が正常に記録されている」ことを確認できます。
第2通知(アーティファクト完了後——スレッド返信):
📹 録画と文字起こしの準備ができました!
🎥 録画
https://drive.google.com/file/d/xxx
📝 文字起こし
https://docs.google.com/document/d/xxx
ℹ️ チャンネルメンバーは閲覧権限があります第2通知は第1通知のスレッド返信として送られます。第1通知の ts(メッセージタイムスタンプ)をFirestoreに保存しておき、第2通知でスレッドの親として指定しています。
運用の可観測性:OpenTelemetry+Grafana+Prometheus
このシステムのすべての処理ログはOpenTelemetryで計装し、Grafanaに集約しています。Meet Space作成、Pub/Subイベント処理、Drive→GCSコピー、Embedding生成、Slack通知——各ステップのレイテンシやエラー率をダッシュボードで一覧できます。
また、以前の記事で紹介したGrafana MCPを通じて、これらのログやメトリクスにMCP経由でもアクセス可能です。「昨日のMeetパイプラインでエラーが出たログを見せて」といった調査がClaude Codeから直接できます。
Gemini APIのコストについては、Prometheusで実際の利用量とコストを追跡しています。文字起こし・画面共有分析のトークン消費量がリアルタイムで可視化されているので、コスト異常にもすぐ気づけます。
その先:会議データがプロジェクトの知識基盤になる
ここまで紹介した仕組みは「会議の録画・文字起こしを共有・検索する」というものですが、実はこのデータはもっと広い文脈で活用され始めています。
プロジェクト単位での会議データ統合
エアークローゼットでは、プロジェクト単位でSlackチャンネルが作成されています。このチャンネルとプロジェクトの紐づきはFirestoreで管理されており、以前の記事で紹介したProject Management MCPからは、プロジェクトに紐づく会議データをMCP経由で横断検索できるようになっています。
たとえば「プロジェクトXの過去の会議で、この仕様について議論した内容を教えて」と聞けば、そのプロジェクトのSlackチャンネルに紐づく全会議の文字起こしから関連部分を検索して回答してくれます。
Slackメッセージとの統合検索
会議の文字起こしだけでなく、Slackのメッセージ自体も同様の仕組みでBigQueryに保存・ベクトル化しています。同じMCPから、会議内容とSlackの議論を横断して検索できます。
会議で決まったことが、その後Slackでどう具体化されたか。逆に、Slackで議論していた内容が、どの会議で最終決定されたか——会議とチャットという2つのコミュニケーション手段を統合的に検索できるのは、実用上かなり強力です。
コードレビューへの活用を検討中
さらに現在検討しているのが、これらの会議・Slackデータに含まれるビジネスコンテキストを、コードレビュー時の仕様チェックに活かせないかという試みです。
PRで変更されたコードに関連する会議での決定事項やSlackでの仕様議論を自動で引き当てて、「この変更は◯月◯日の会議で決まった仕様と整合しているか?」をレビュー時に確認できれば、仕様の認識齟齬によるバグを未然に防げるかもしれません。まだ構想段階ですが、会議データの活用可能性はまだまだ広がると考えています。
まとめ:会議の価値を最大化する
最後に、このシステムで実現したことを整理します。
| 課題 | 解決 |
|---|---|
| 議事録を書く手間 | 自動で文字起こしされ、自動で共有される |
| 録画を見返す手間 | 自然言語で質問すれば要約が返る |
| 権限管理の手間 | チャンネル・参加者・招待者に自動付与 |
| Meet作成の手間 | Chrome拡張からワンクリック |
| 「あの話なんだっけ」 | RAG検索で即座に見つかる |
| 画面共有の内容が残らない | Gemini Visionで自動抽出 |
技術的に面白かったポイントをまとめると:
- LIFOキャッシュでMeet Space作成を100ms以下に高速化
- Chrome Extensionで既存の動線上に機能を配置し、利用率を劇的に向上
- Domain-Wide Delegationでファイルのオーナーシップ問題を解決
- Workspace Events API+日次バッチで7日TTLの制約をカバー
- 冪等なイベント処理でPub/Subのat-least-once配信に対応
- 3層の権限付与モデルで「関係者全員」にアクセス権を自動付与
- デュアルテーブル戦略でチャンネル内検索と横断検索を両立
- Gemini Visionのfps使い分けで文字起こしと画面共有分析のコストを最適化
会議は情報の宝庫です。それを眠らせておくのはもったいない。
Google Workspace×GCP×Slackの連携で、会議の価値を最大化する。同じような課題を抱えている方の参考になれば幸いです。
comments (0)
まだコメントはありません。