みなさまこんにちは!エアークローゼットでCTOをしている辻です。
前回の記事で全社DBを自然言語で横断検索できるMCPサーバーを紹介し、社内MCP群の全体像もお見せしました。今回はその中で「Biz Graph」と一言で紹介していたものを深掘りします。
施策と KPI の関係をグラフ構造で表現し、「あの施策、効果あったの?」に AI が答えられるようにした話です。
なぜ Graph RAG なのか
AI をより活用するために重要なのは、データの羅列ではなくデータの関係性を伝えることです。
データ量がそこまで多くなければ NotebookLM のようなツールで十分に成果が出せます。しかし、ビジネスデータすべてをコンテキストに入れることは不可能です。施策の報告資料、KPI スプレッドシート、マーケの週報、物流の日次実績 — これらを全部まとめてプロンプトに突っ込むことはできない。
そのため、現状とれる一番の選択肢は Graph RAG だと考えています。必要なデータを、関係性とともに、いつでも検索できるようにする。AI が「この施策に関連する指標は?」と聞かれたとき、グラフを辿って必要な情報だけを取り出せる構造を事前に作っておく。
ただし、ここに落とし穴があります。
グラフにならないデータをグラフにする
「ナレッジグラフ」「GraphRAG」という言葉を聞いたことがある方は多いと思います。でも実際に作ろうとしたとき、ほとんどの人がぶつかる壁があります。
ビジネスデータは、そのままではグラフにならない。
DB Graph のときは話が違いました。テーブル間には FK(外部キー)があり、ORM には @JoinColumn や belongsTo があり、データの中にリレーションが既に存在していた。それを解析してグラフに変換すればよかった。
ところが「施策」と「KPI」の関係には、そんなものは存在しません。
- 全社会議のスライドに「SNS広告キャンペーン開始」と書いてある
- スプレッドシートに「今週の新規会員数: 1,234」と記録してある
- この2つの間に FK はない。結合キーもない。
「SNS広告キャンペーンが新規会員数に影響した」という関係は、人間の頭の中にしかない。スプレッドシートのどこにも書いていない。
これが「ビジネスデータはグラフにならない」の意味です。エンティティ間の関係が自明ではなく、グラフの構造そのものを設計する必要がある。
課題:「あの施策、効果あったの?」
うちでは毎週、全社会議や各グループごとの定例会議で施策の進捗が報告されます。
「春のSNS広告キャンペーン始めました」 「レコメンド機能を改善しました」 「CS対応のSLA達成率を引き上げます」
— 毎週、数十件の施策が報告される。年間で数百件。累計5,000件超。
そして別のスプレッドシートには、会員数・新規獲得数・継続率・サービス満足度・獲得CPA… 200以上の指標が日次・週次で記録されています。
問題は、この2つが完全に分断されていること。
「先月やったSNS広告キャンペーン、新規獲得にどのくらい効いた?」
この質問に答えるには:
- まず施策の実施期間を確認する(どのスライドに書いてあったっけ?)
- その期間のKPIデータをスプレッドシートから探す(どのシートのどのタブ?)
- 期間を合わせて数字を見比べる(先週比?先月比?前年比?)
- 同時期に他の施策もやってなかったか確認する(交絡要因は?)
手作業では30分〜1時間かかる分析が、毎週、複数の施策について発生する。現実的には、ほとんどの施策の効果検証は「なんとなく良かったっぽい」で終わっています。
Biz Graph の全体像
この問題を解決するために作ったのが Biz Graph です。
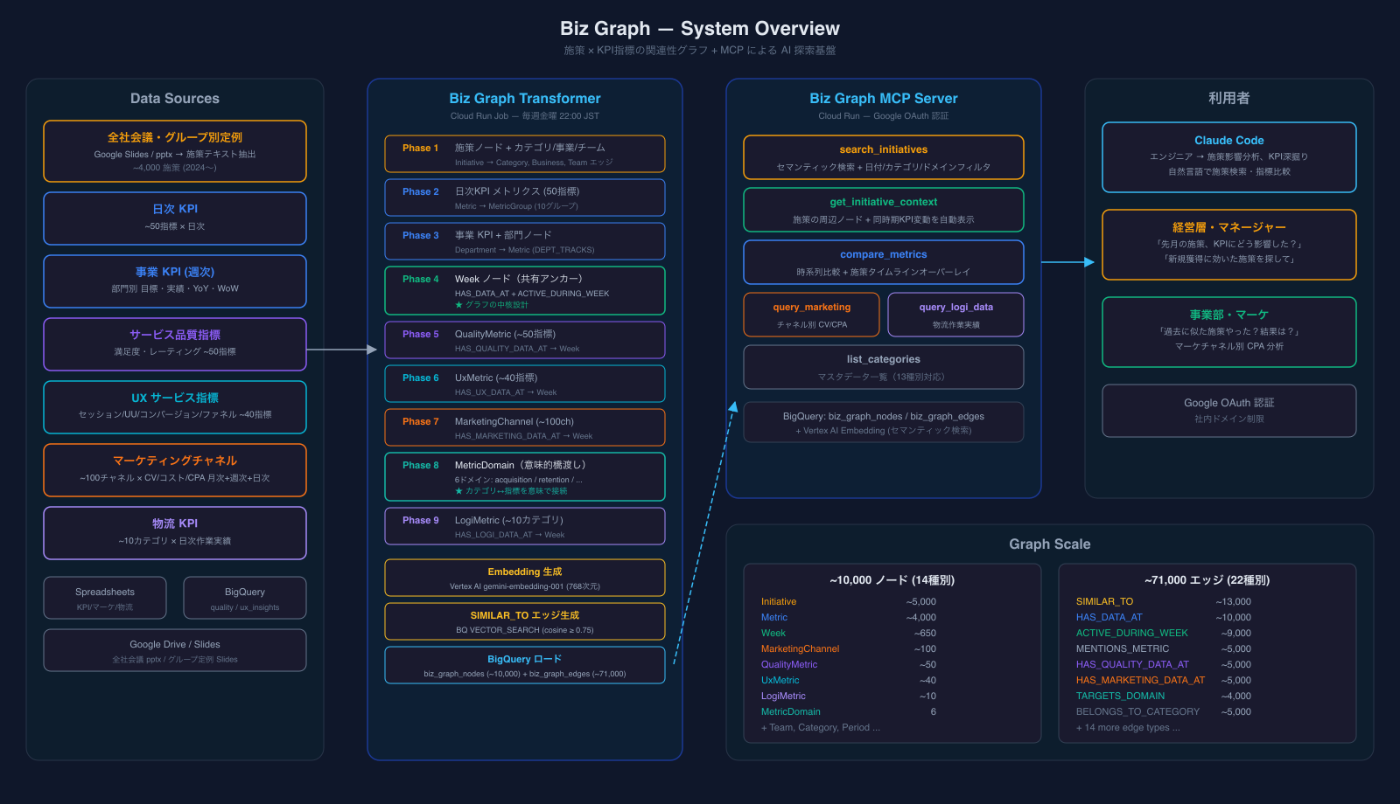
規模
| リソース | 数 |
|---|---|
| ノード数 | ~10,000(14種別) |
| エッジ数 | ~71,000(22種別) |
| 施策データ | ~5,000件 |
| KPI指標 | ~4,000件(会員数/新規/継続率/満足度/UX/マーケ/物流) |
| マーケチャネル | ~100(SEM/LINE/メール/CRM等) |
| データソース | 9テーブル/スプレッドシート |
3つのコンポーネント
- Biz Graph Transformer — 週次で全データソースからグラフ構築(Cloud Run Job、毎週金曜22)
- Biz Graph MCP Server — グラフ検索 + 時系列分析を AI から実行(Cloud Run)
- Biz Data Loader — 日次でマーケ/物流データを自動取込(Cloud Run Job、毎朝6)
設計の核心:Week ノードという工夫
ここからがこの記事の本題です。
「施策」と「指標」をどうグラフで繋ぐか。最初に思いつく設計は、直接エッジを張ることです。
Initiative("SNS広告") ──AFFECTS──→ Metric("新規会員数")この設計は破綻します。 理由は3つ:
- エッジ爆発: 5,000施策 × 4,000指標 = 最大2,000万本のエッジが必要になりうる
- 因果の不確実性: 「SNS広告が新規会員数に影響した」は仮説であって事実ではない。直接エッジを張ると「確定した関係」に見えてしまう
- 時間情報の欠落: いつ影響があったのかが表現できない
そこで考えたのが、Week ノードを共有アンカーにする間接接続です。
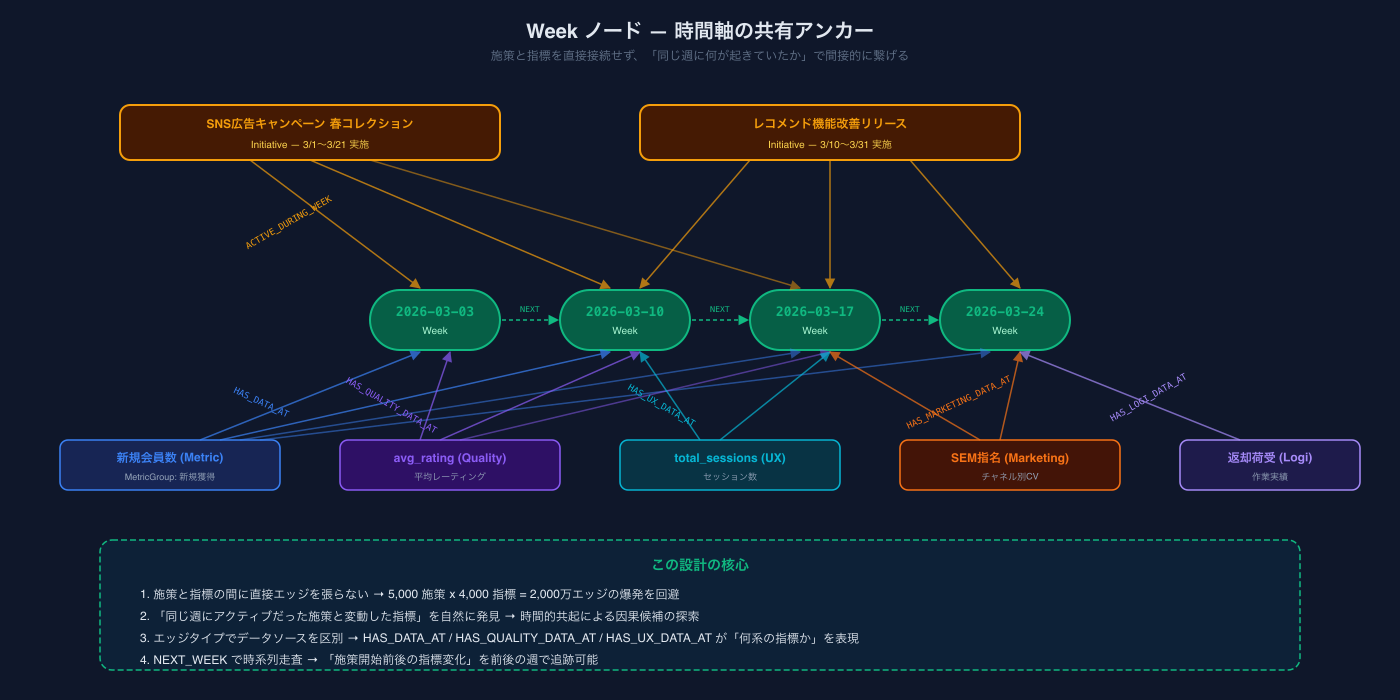
Initiative("SNS広告") ──ACTIVE_DURING_WEEK──→ Week:2026-03-03
Metric("新規会員数") ──HAS_DATA_AT──→ Week:2026-03-03
QualityMetric("avg_rating") ──HAS_QUALITY_DATA_AT──→ Week:2026-03-03
MarketingChannel("SEM指名") ──HAS_MARKETING_DATA_AT──→ Week:2026-03-03施策と指標を直接繋がず、「同じ週」という時間軸で間接的に繋がる設計です。
なぜこれが優れているのか
1. エッジ爆発を防ぐ
施策は「実施していた週」にだけエッジを張る。指標も「データがある週」にだけエッジを張る。直積ではなく、それぞれが独立にWeekに接続するため、エッジ数は線形に増える。
2. 因果ではなく「共起」を表現する
「同じ週にアクティブだった施策と、変動した指標」— これは因果の主張ではなく、因果の候補を発見するための構造。人間や AI が最終判断する余地を残している。
3. エッジタイプでデータソースを区別する
同じ Week ノードへの接続でも、HAS_DATA_AT(経営KPI)、HAS_QUALITY_DATA_AT(サービス品質)、HAS_UX_DATA_AT(UX指標)、HAS_MARKETING_DATA_AT(マーケ)、HAS_LOGI_DATA_AT(物流)が区別される。「何系のデータか」がエッジタイプ自体に埋め込まれている。
4. 時系列走査が自然にできる
Week 同士は NEXT_WEEK エッジで連結。「施策開始の前後3週間で指標がどう動いたか」を、グラフの走査として表現できる。
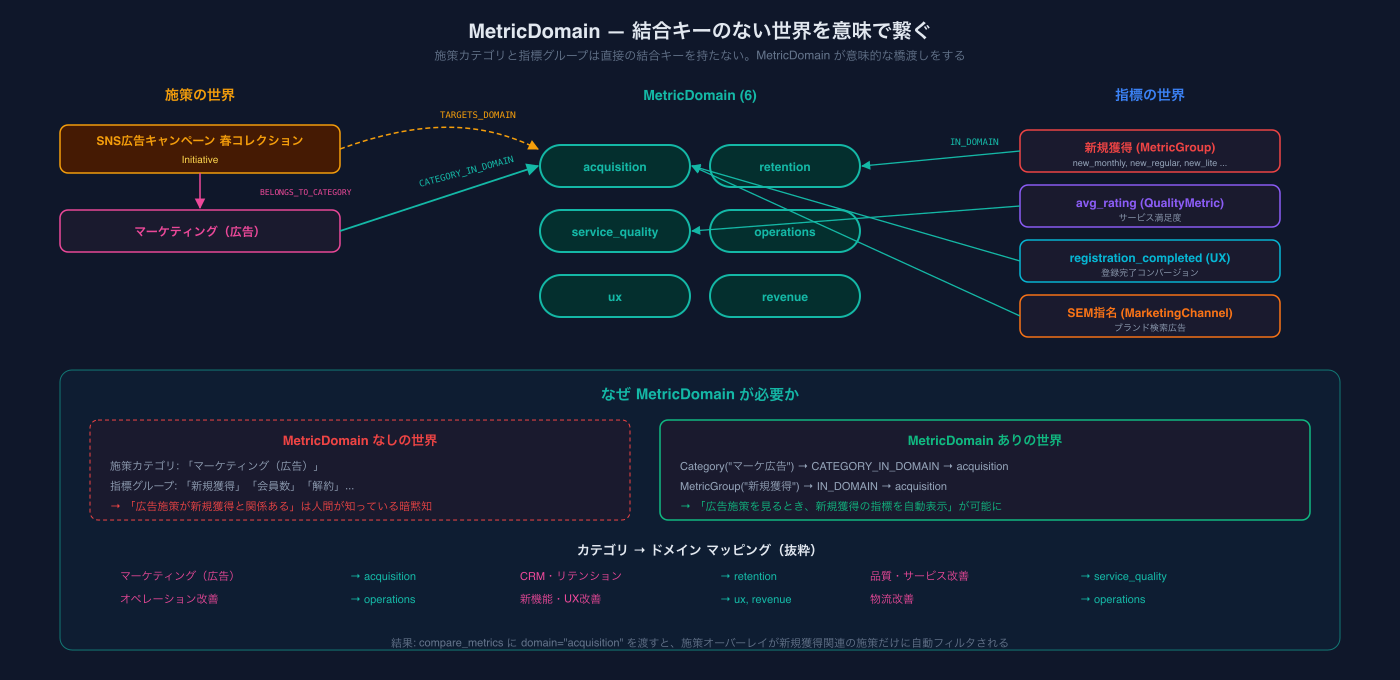
MetricDomain:結合キーのない世界を意味で繋ぐ
Week ノードだけでは「同じ週に何が起きたか」はわかりますが、施策にとって関連性の高い指標はどれかがわかりません。SNS広告キャンペーンの効果を見るのに、物流の返却荷受数を見ても仕方ない。
しかし、施策カテゴリ(「マーケティング(広告)」)と指標グループ(「新規獲得」)の間には 結合キーが存在しない。「広告施策 → 新規獲得と関連がある」は、人間が知っている暗黙知です。
この暗黙知を構造化したのが MetricDomain(6ドメイン)です。
| ドメイン | 意味 | 接続する指標系統 |
|---|---|---|
| acquisition | 新規獲得 | マーケチャネル、新規会員数、登録CV |
| retention | 継続・解約抑止 | 会員数、解約率、プラン変遷 |
| service_quality | サービス品質 | 満足度・レーティング等 |
| operations | オペレーション | 選定・配送・返却・物流KPI |
| ux | UX体験 | セッション数、ファネル |
| revenue | 売上・購入 | 購入CV、アップセル |
現在は6ドメインですが、この数は固定ではありません。事業の成長や組織変化に合わせて自由に追加・分割できます。ドメインの定義はコード上のマッピングテーブルに過ぎないので、拡張コストはほぼゼロです。
施策カテゴリと MetricDomain の対応、指標グループと MetricDomain の対応を人間が定義することで、「マーケ広告施策を見るとき、新規獲得系の指標を自動表示」が可能になります。
Category("マーケ広告") ──CATEGORY_IN_DOMAIN──→ MetricDomain("acquisition")
↑ IN_DOMAIN
MetricGroup("新規獲得")
MarketingChannel("SEM指名")
UxMetric("registration_completed")結果: compare_metrics に domain: "acquisition" を渡すと、施策オーバーレイが新規獲得関連の施策だけに自動フィルタされる。
SIMILAR_TO:AIが「過去に似た施策やった?」に答える
もう1つの独自設計が SIMILAR_TO エッジです。
施策のテキスト(タイトル + 説明文)を Vertex AI の gemini-embedding-001 で768次元ベクトル化し、BQ の VECTOR_SEARCH で cosine similarity ≥ 0.75 の類似ペアを自動検出。
SELECT base.id, query.id, distance
FROM VECTOR_SEARCH(
TABLE cortex.biz_graph_nodes,
'embedding',
(SELECT id, embedding FROM cortex.biz_graph_nodes WHERE node_type = 'Initiative'),
top_k => 6,
distance_type => 'COSINE'
)
WHERE base.id != query.id AND distance <= 0.25 -- 距離0.25以下 = 類似度0.75以上現在 13,202本 の SIMILAR_TO エッジが存在。各施策から最大5件の類似施策が事前計算されています。
「去年の夏にも似たSNS広告やったよね?あのときどのくらい効果あった?」— こういう質問に対して、類似施策をグラフ上で即座に辿り、その施策がアクティブだった週の KPI 変動を比較できる。
実際に使ってみる
MCP ツールを使った探索の実例を紹介します。
「新規獲得に効いたマーケ施策を探して」
search_initiatives({
"query": "新規獲得のSNS広告施策",
"domain": "acquisition",
"dateFrom": "2025-10-01",
"dateTo": "2026-03-31",
"limit": 5
})レスポンス(抜粋):
5件の施策が見つかりました(ベクトル類似度順):
1. SNS広告 春コレクション展開 (2026-03-09)
カテゴリ: マーケティング(広告)
類似度: 892/1000
2. Instagram リール広告テスト (2026-02-23)
カテゴリ: マーケティング(広告)
類似度: 845/1000
...「その施策の効果を見たい」
get_initiative_context({
"initiative_id": "Initiative:2026-03-09:SNS広告 春コレクション展開",
"metric_window_days": 30
})レスポンス(抜粋):
## 施策コンテキスト
タイトル: SNS広告 春コレクション展開
実施期間: 2026-03-01 〜 2026-03-31
カテゴリ: マーケティング(広告)
ターゲットドメイン: acquisition
## 類似施策 (SIMILAR_TO)
- Instagram リール広告テスト (類似度: 0.82)
- ライトプラン1ヶ月無料キャンペーン (類似度: 0.78)
## 同時期のKPI変動(実施前後30日)
| 指標 | 施策前平均 | 施策後平均 | 変化 |
|------|-----------|-----------|------|
| new_regular | 50 | 60 | +20.0% |
| new_lite | 30 | 35 | +16.7% |
| monthly | 1,000 | 1,050 | +5.0% |
## サービス品質指標
| 指標 | 前 | 後 | 変化 |
|------|---|---|------|
| avg_rating | 3.50 | 3.60 | +2.9% |
## UX指標
| 指標 | 前 | 後 | 変化 |
|------|---|---|------|
| total_sessions | 10,000 | 12,000 | +20.0% |
| registration_completed | 100 | 130 | +30.0% |これが Week ノード設計の威力です。 施策がアクティブだった週を特定し、同じ週の全指標(KPI、サービス品質、UX、マーケ、物流)を自動で引っ張ってくる。
「前年比で新規獲得数を可視化して、施策を重ねて」
compare_metrics({
"metrics": ["new_regular", "new_lite", "new_monthly"],
"dateFrom": "2025-10-01",
"dateTo": "2026-03-31",
"granularity": "weekly",
"overlay_initiatives": true,
"domain": "acquisition"
})時系列データの上に、同期間にアクティブだった acquisition ドメインの施策が重ねて表示される。KPI のスパイクが「あの施策の時期だ」と一目でわかる。
グラフ構築パイプライン:9フェーズ
ここからは技術的な中身です。グラフは9フェーズで構築されます。
| Phase | 内容 | 生成物 |
|---|---|---|
| 1 | 施策ノード + カテゴリ/事業/チーム | Initiative, Category, Business, Team |
| 2 | 日次KPI (50指標) | Metric → MetricGroup (10グループ) |
| 3 | 事業KPI + 部門 | Department → Metric (DEPT_TRACKS) |
| 4 | Week ノード(共有アンカー) | HAS_DATA_AT + ACTIVE_DURING_WEEK + NEXT_WEEK |
| 5 | サービス品質指標 (~50指標) | QualityMetric → Week |
| 6 | UX指標 (~40指標) | UxMetric → Week |
| 7 | マーケチャネル (~100ch) | MarketingChannel → Week |
| 8 | MetricDomain(意味的橋渡し) | 6ドメイン + IN_DOMAIN + TARGETS_DOMAIN |
| 9 | 物流KPI (~10カテゴリ) | LogiMetric → Week |
Phase 4 と Phase 8 がこのグラフの設計上のポイント。他のフェーズは「データをノード化する」だけですが、この2つは「存在しない関係を構造化する」フェーズです。
Phase 4:Week ノードの生成
// 施策の実施期間を ISO Week に変換し、ACTIVE_DURING_WEEK エッジ生成
for (const initiative of initiatives) {
const weeks = getISOWeeksBetween(
initiative.executionStartDate,
initiative.executionEndDate
);
// 最大52週に制限(1年以上の長期施策対策)
for (const week of weeks.slice(0, 52)) {
edges.push({
edge_type: 'ACTIVE_DURING_WEEK',
source_id: initiative.id,
target_id: `Week:${week}`,
});
}
}
// 指標データのある週に HAS_DATA_AT エッジ生成
for (const metricWeek of metricWeeks) {
edges.push({
edge_type: 'HAS_DATA_AT',
source_id: `Metric:${metricWeek.metric}`,
target_id: `Week:${metricWeek.week}`,
});
}
// 時系列走査用の NEXT_WEEK エッジ
const sortedWeeks = [...allWeeks].sort();
for (let i = 0; i < sortedWeeks.length - 1; i++) {
edges.push({
edge_type: 'NEXT_WEEK',
source_id: `Week:${sortedWeeks[i]}`,
target_id: `Week:${sortedWeeks[i + 1]}`,
});
}Phase 8:MetricDomain の生成
// カテゴリ → ドメイン(人間が定義した意味的マッピング)
const CATEGORY_TO_DOMAINS: Record<string, string[]> = {
'マーケティング(広告)': ['acquisition'],
'CRM・リテンション': ['retention'],
'品質・サービス改善': ['service_quality'],
'オペレーション改善': ['operations'],
'新機能': ['ux', 'revenue'],
// ...
};
// Initiative → TARGETS_DOMAIN(メイン事業のみ。KPIデータがある事業に限定)
for (const initiative of initiatives) {
if (initiative.business !== MAIN_BUSINESS) continue;
const domains = CATEGORY_TO_DOMAINS[initiative.category] ?? [];
for (const domain of domains) {
edges.push({
edge_type: 'TARGETS_DOMAIN',
source_id: initiative.id,
target_id: `MetricDomain:${domain}`,
});
}
}なぜ専用のグラフDB・OSSライブラリを使わないのか
Neo4j や Amazon Neptune、あるいは Microsoft の GraphRAG ライブラリのような OSS を使わず、BigQuery だけでグラフを実装しています。
専用グラフDB を使わない理由
| 観点 | 専用グラフDB | BigQuery |
|---|---|---|
| グラフ走査 | 高速(ネイティブ) | 十分高速(~10,000ノード規模) |
| ベクトル検索 | 別サービスが必要 | VECTOR_SEARCH 関数で統合 |
| 時系列分析 | 苦手 | ネイティブ(ウィンドウ関数) |
| 運用コスト | インスタンス常時稼働 | サーバーレス(クエリ時のみ課金) |
| 他データとの結合 | ETL必要 | 同一プロジェクトで即JOIN |
Biz Graph の特性上、「深いグラフ走査」よりも「グラフ構造 + 時系列分析 + ベクトル検索の組み合わせ」が重要。この3つを1つのエンジンで完結できるBigQueryが最適解でした。
さらに、BigQuery にはグラフ機能(Graph)が発表されており、GA されればノード/エッジテーブルに対してネイティブなグラフクエリが使えるようになります。現在は SQL の JOIN で走査していますが、将来的にはより高速かつ直感的なクエリに移行できる見込みです。
OSS ライブラリ・SaaS を使わない理由
Microsoft GraphRAG のような OSS や、各種 Graph RAG SaaS は、テキスト文書からエンティティと関係を自動抽出することに主眼を置いています。論文やニュース記事のような自然言語テキストには有効ですが、今回のユースケースには合いません。
理由は単純で、グラフの構造自体を自分で設計する必要があるからです。
- Week ノードという「時間アンカー」の概念は、汎用ツールには存在しない
- MetricDomain による「意味的橋渡し」は、自社のビジネス構造を反映した設計
- 施策→Week→指標という間接接続パターンは、LLM によるエンティティ抽出では生まれない
汎用ツールは「テキストからグラフを自動生成する」もの。今回必要だったのは「グラフのスキーマを自分で設計し、異種データソースを統合する」こと。問題の性質が違います。
実際のクエリ例(get_initiative_context の内部):
-- 施策がアクティブだった週を取得
WITH active_weeks AS (
SELECT target_id AS week_id
FROM cortex.biz_graph_edges
WHERE source_id = @initiative_id
AND edge_type = 'ACTIVE_DURING_WEEK'
),
-- 同じ週にデータがある指標を取得
co_occurring_metrics AS (
SELECT e.source_id AS metric_id, e.edge_type, w.week_id
FROM cortex.biz_graph_edges e
JOIN active_weeks w ON e.target_id = w.week_id
WHERE e.edge_type IN (
'HAS_DATA_AT', 'HAS_QUALITY_DATA_AT',
'HAS_UX_DATA_AT', 'HAS_MARKETING_DATA_AT'
)
)
SELECT * FROM co_occurring_metricsグラフ走査と時系列データ取得が1つのSQLで完結する。専用グラフDBでは、走査結果を別サービスに渡して時系列クエリ…というホップが必要になります。
施策データの取込:会議スライドからの自動抽出
グラフの品質は元データの品質で決まります。施策データは全社会議や各グループごとの定例会議スライドから取り込んでいます。
| ソース | 形式 | 頻度 |
|---|---|---|
| 全社会議 | Drive 内 pptx → Slides 変換 → テキスト抽出 | 週次 |
| グループ別定例 | Google Slides(累積型、末尾に最新週が追加される) | 週次 |
会議スライドからテキストを抽出し、AI で構造化して施策テーブルに格納。
interface InitiativeRow {
meetingDate: string; // 会議開催日
source: string; // 取込元(全社会議 / グループ定例 等)
business: string; // 事業名
category: string; // マーケティング(広告), 新機能, ...
title: string; // 施策タイトル
description: string; // 詳細説明
team: string; // 実施チーム
executionStartDate: string; // 実施開始日
executionEndDate: string; // 実施終了日
metrics: string; // JSON形式の数値指標
status: string; // planned / in_progress / retrospective
}重要なのは executionStartDate / executionEndDate。会議の日(meetingDate)と施策の実施日は異なります。「先週からSNS広告始めました」と3/9の会議で報告された施策の executionStartDate は 3/1。この区別が Week ノードとの正確な接続に必須です。
運用コスト
| リソース | コスト |
|---|---|
| Vertex AI Embedding(週次) | ~$0.05/回 |
| Claude Code(施策抽出) | 月額プランの範囲内 |
| BQ ストレージ | 数GB(無視できる) |
| Cloud Run Job | ほぼ無料(週1回 + 日1回) |
| MCP Server | ほぼ無料(Cloud Run min-instances=0) |
月額数ドルで 10,000ノード・71,000エッジのグラフを維持。
一般的なグラフとの比較
最後に、この設計がどう特異なのかを整理します。
| 観点 | 一般的なナレッジグラフ | Biz Graph |
|---|---|---|
| ノード設計 | エンティティをそのままノード化 | 「Week」という意図的な時間軸アンカーを設計 |
| エッジの意味 | 関係をそのまま記述 | エッジタイプがデータソースの種別を表現 |
| 中間ノード | 分類用タクソノミー | MetricDomain が意味的橋渡し(暗黙知の構造化) |
| グラフ構築 | 既存データから関係を抽出 | 関係が存在しないデータを意図的に設計してグラフ化 |
| 用途 | 検索・ナビゲーションが中心 | 施策効果の因果候補探索まで踏み込む |
| 類似検索 | テキスト検索 | Embedding 事前計算による SIMILAR_TO エッジ |
一言で言えば:
DB Graph は「既にある関係を発見可能にした」。Biz Graph は「存在しない関係を設計して作り出した」。
前者は解析の問題、後者は設計の問題。グラフの構造そのものをゼロから設計し、異なるデータソース(会議スライド・スプレッドシート・BQテーブル)を1つの探索可能な構造に統合する。これが Biz Graph の本質です。
なぜ flat RAG ではなく Graph RAG なのか
ここで改めて、冒頭で述べた「なぜ Graph RAG なのか」に立ち返ります。
施策の効果検証というユースケースにおいて、通常のベクトル検索(flat RAG)では何が起きるかを考えてみましょう。「SNS広告キャンペーンの効果は?」と聞いたとき、flat RAG は施策の説明テキストに似たチャンクを返します。つまり施策自体の情報は取れる。
しかし、同時期の KPI 変動は返ってこない。過去の類似施策の結果も返ってこない。関連ドメインの指標も返ってこない。
これらは「テキストが似ている」のではなく「グラフ上で繋がっている」情報だからです。Week ノードを辿って初めて到達できる。この「関係性を辿る」必要があるユースケースこそ、Graph RAG が flat RAG に対して明確に優位なケースです。
設計の誠実さ:因果を主張しない
この設計で意識したことがあります。因果を主張しないこと。
多くの BI ツールや AI 分析は「この施策がこの KPI に影響した」と断定したがります。でも現実にはそんな確証はありません。同時期に複数の施策が走っていたかもしれないし、季節要因かもしれないし、外部環境の変化かもしれない。
Week ノードによる間接接続は、「同じ時期に起きたこと」を並べるだけです。因果の判断は人間や AI のリーズニングに委ねている。これは統計的にも誠実なアプローチだと考えています。
「因果の候補を発見する構造」であって、「因果を断定する構造」ではない。この区別は重要です。
限界と課題:設計者の暗黙知がボトルネック
一方で、このアプローチの弱点も正直に書いておきます。
MetricDomain のマッピング(「マーケティング広告 → acquisition ドメイン」)は、人間がハードコードしています。この設計が間違っていたら、グラフ全体の探索結果が歪みます。
これは同時に「なぜ自前で設計する必要があるか」の答えでもあります。既製品のグラフツールでは、自社のビジネス構造 — どのカテゴリの施策がどの指標群に関連するか — を反映できません。この暗黙知の構造化は、そのビジネスを知っている人間にしかできない。
今後の方向性としては、このマッピング自体を AI に提案させ、人間がレビューする仕組みを考えています。完全自動化は難しいですが、「AI が候補を出し、人間が承認する」ワークフローなら、ドメイン知識のメンテナンスコストを下げられるはずです。
まとめ
ビジネスデータをグラフにするのは、技術的な困難よりも設計の困難が大きい。
「施策」と「KPI」の間にFKはない。結合キーもない。しかし、時間軸(Week ノード) と 意味的ドメイン(MetricDomain) という2つの構造を意図的に設計することで、探索可能なグラフになりました。
- Week ノード: 施策と指標を直接接続せず、「同じ週」で間接接続。因果の候補を発見する構造
- MetricDomain: 施策カテゴリと指標グループを意味で橋渡し。暗黙知の構造化
- SIMILAR_TO: AI Embedding で類似施策を事前計算。「過去に似たことやった?」に即答
これにより、「あの施策、効果あった?」「新規獲得に効いた施策を探して」「前年比で指標を見せて、施策を重ねて」— こうした質問に、AI が自律的にグラフを探索して答えられるようになりました。
グラフは「あるもの」ではなく「設計するもの」。特にビジネスデータにおいては。
comments (0)
まだコメントはありません。