みなさまこんにちは!エアークローゼットでCTOをしている辻です。
今回は、自分でもかなりの自信作だと思っているDB GraphおよびDB Graph MCPについて詳しくお話しします。
全社に散らばる15スキーマ、991テーブル、11のSQL DB + 6つのMongoDBを、Claude CodeやClaude CoworkなどのAIから自然言語で検索・クエリできるModel Context Protocol (MCP)サーバーです。テーブル名を知らなくても「返却に関するテーブルを教えて」と聞けば答えが返ってくる。しかも本番データも安全に扱えます。
「そんなの本当にできるの?」
って思いますよね。できるんです。この記事では、なにができるのか、なぜそれができるのか、どう設計したのか、そして実際のレスポンスまで、すべてお見せします。
背景: なぜDBを「検索」する必要があるのか
エアークローゼットは2015年のサービス開始から10年が経ちました。その間にシステムは成長を続け、現在は以下の規模になっています。
| リソース | 数 |
|---|---|
| SQLデータベース | 11(MySQL 8 + PostgreSQL 3) |
| MongoDBデータベース | 6(DocumentDB 5 + Atlas 1) |
| スキーマ | 15 |
| テーブル/コレクション | 991 |
| ORM | 4種類(TypeORM, Sequelize, Drizzle, Mongoose) |
| リポジトリ | 28 |
10年分のテーブルが積み重なっています。正直、全テーブルを把握している人は社内に誰もいません。
こういうシーンを想像してみてください。
CSチームから「この会員さん、アプリ上では返却済みになっているんですけど、倉庫側で本当に返却確認できてますか?」という問い合わせが来ました。
これ、調査するのに何が必要かわかりますか?
まず、アプリ側の返却ステータスは aircloset スキーマの配送オーダーテーブルにあります。配送ステータスが「RETURNED」なら「返却済み」。ここまではわかる人もいるかもしれません。
でも、倉庫側の返却確認は bridge スキーマにあります。荷受記録テーブルのステータスが「COMPLETE」であることが「倉庫で実際に荷受処理が完了した」ことを意味します。
問題はこの2つが別のデータベースにあること。直接のFKは存在しません。つなぐには、間に倉庫連携テーブルがあって、そこの倉庫オーダーコード (varchar)と bridge 側の出荷オーダーコードが対応している、という事実を知る必要があります。
aircloset の配送オーダーテーブル (status = RETURNED)
↓ order_id
aircloset の倉庫連携テーブル
↓ warehouse_order_code(varchar)
bridge の出荷オーダーテーブル (code で結合、FK なし!)
↓ shipping_order_id
bridge の荷受記録テーブル (status = COMPLETE が倉庫確認済み)※テーブル名は説明用に一般化しています
4テーブル、2スキーマ、FKのないvarchar結合。**この経路を知っている人が社内に何人いるか?**おそらく片手で数えられます。そしてその人が休みだったら、この調査は止まります。
これが991テーブル × 15スキーマの世界の日常です。「テーブル名がわからない」という単純な話ではなく、スキーマをまたいだデータの繋がり方が、特定の人の頭の中にしかない。これが本当の課題でした。
DB Graph MCP — 全体像
この問題を解決するために作ったのが、DB Graph MCPです。
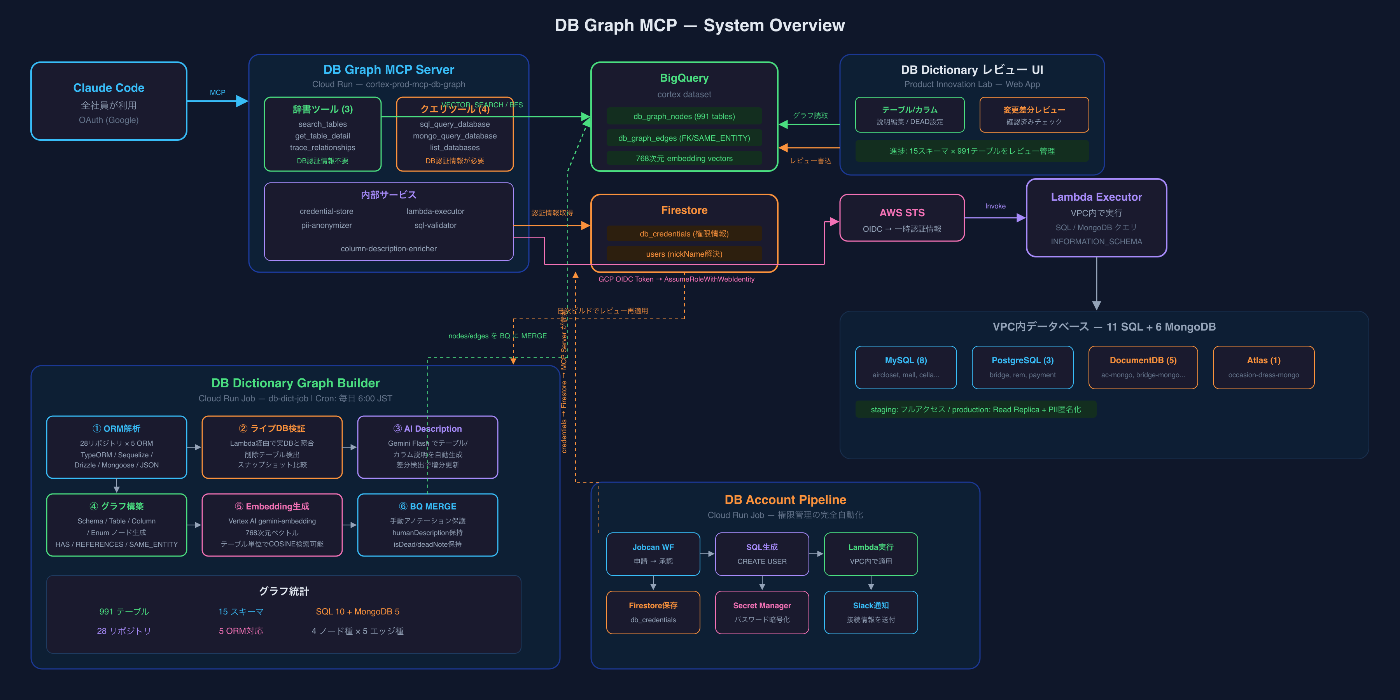
大きく4つのコンポーネントで構成されています。
- DB Dictionary Graph Builder — 28リポジトリのORM定義を解析し、テーブル・カラム・リレーション情報をグラフとしてBigQueryに格納する日次バッチ
- DB DictionaryレビューUI — AI生成の説明文を人間が確認・修正・廃止マーク付けするWebアプリ。レビュー結果は日次ビルドで保護される
- DB Graph MCP Server — グラフ検索 + 実DBクエリを統合したMCPサーバー (Cloud Run)
- DB Account Pipeline — DBアクセス権限の申請 → 承認 → アカウント作成 → 通知を完全自動化するパイプライン
実際に使ってみる
先ほどの返却確認の例を、DB Graph MCPで解いてみましょう。
以降のツール実行例に登場するテーブル名・カラム名は、実際の名称を一般化したものです。レスポンス形式は実物に準拠しています。
Step 1: 自然言語でテーブルを探す
まず、Claude Codeに「返却処理の確認に関するテーブルを探して」と聞きます。内部では search_tables のセマンティック検索が走ります。
> search_tables(query: "返却処理の確認", search_type: "semantic")
5件のテーブルが見つかりました(ベクトル類似度順):
bridge.返送パッケージテーブル (postgresql) (距離: 0.2557)
bridge.荷受記録テーブル (postgresql) (距離: 0.2720)
cella.荷受確認結果テーブル (mysql) (距離: 0.2921)
bridge.荷受記録明細テーブル (postgresql) (距離: 0.2951)
aircloset.返送ステータス変更履歴テーブル (mysql) (距離: 0.3170)「返却処理の確認」で検索しただけで、3つのスキーマ (bridge, cella, aircloset)にまたがるテーブルが一発で出てきます。テーブル名に「返却」と入っていなくても、AI生成の説明文に「荷受処理」「レンタル戻り」といった意味が含まれていれば正確にヒットします。
Step 2: テーブルの詳細を見る
2番目にヒットした bridge の荷受記録テーブルが怪しいので、詳細を見てみます。
> get_table_detail(table_name: "bridge.荷受記録テーブル")
# bridge.荷受記録テーブル
DB: POSTGRESQL / ORM: typeorm / リポジトリ: bridge-api
## カラム (9)
- id: int [PK, AI, NOT NULL]
- code: varchar [NOT NULL]
- 出荷オーダーID: varchar [NOT NULL]
- status: enum [NOT NULL, default=IN_PROGRESS]
- type: enum [NOT NULL]
- 荷受日時: varchar [NOT NULL]
- 操作者ID: varchar [NOT NULL]
- created_at / updated_at: datetime
## 参照先 (2)
- 出荷オーダーID → bridge.出荷オーダーテーブル.id (explicit)
- 操作者ID → bridge.ユーザーテーブル.id (explicit)
## 参照元 (1)
- bridge.荷受記録明細テーブル.record_id → id (explicit)
## Enum/ステータス定義 (2)
- Status: COMPLETE=荷受済, IN_PROGRESS=実行中
- Type: RENTAL_RETURN=レンタル戻り, BUSINESS_RETURN=ビジネス戻り, RENTAL_RETURN_LACK=レンタル戻り欠品, BUSINESS_RETURN_LACK=ビジネス戻り欠品status = COMPLETE が「倉庫で実際に荷受が完了した」ことを意味する — これがまさに知りたかった情報です。しかも type = RENTAL_RETURN でレンタル返却と業務返却を区別できる。Enumの日本語定義まで一目でわかります。
Step 3: クロススキーマの経路を発見する
でも問題は、aircloset の配送オーダーテーブル (アプリ側)と bridge の荷受記録テーブル (倉庫側)をどうつなぐか。trace_relationships で探ります。
> trace_relationships(table_name: "bridge.出荷オーダーテーブル", direction: "both", max_depth: 1)
# リレーション追跡: bridge.出荷オーダーテーブル
ノード数: 23, エッジ数: 22
## リレーション(抜粋)
- 出荷オーダー.店舗ID → 店舗マスタ.id (explicit)
- 出荷オーダー.出荷元倉庫ID → 倉庫マスタ.id (explicit)
- 荷受記録.出荷オーダーID → 出荷オーダー.id (explicit) ← 倉庫確認!
- 返送パッケージ.出荷オーダーID → 出荷オーダー.id (explicit) ← 返送荷物
- 出荷パッケージ.出荷オーダーID → 出荷オーダー.id (explicit) ← 発送荷物
- 出荷検品.出荷オーダーID → 出荷オーダー.id (explicit) ← 検品
...bridge の出荷オーダーテーブルから荷受記録への経路がわかりました。次は、aircloset 側と bridge 側をつなぐ中間テーブルを見つけます。
> search_tables(query: "倉庫連携", search_type: "table", adjacent_depth: 1)
aircloset.倉庫連携テーブル (mysql)
### 関連テーブル
→ aircloset.配送オーダーテーブル (order_id → id)> get_table_detail(table_name: "aircloset.倉庫連携テーブル")
## カラム (4)
- order_id: int [PK, NOT NULL] ← aircloset 配送オーダーID
- warehouse_order_code: varchar [NOT NULL] ← bridge 出荷オーダーコード見つけた。 order_id が aircloset 側の配送オーダーID、warehouse_order_code が bridge 側の出荷コード。FKはないけど、このvarcharが2つのスキーマをつなぐ唯一のキーです。
Step 4: 実データで確認する
経路がわかったので、実データでクロスクエリを組み立てます。まず aircloset 側で対象ユーザーの配送オーダーと倉庫コードを取得します。
> sql_query_database(database: "aircloset", sql: "SELECT ... WHERE user_id = 12345 AND status = 'RETURNED'")
**aircloset** (staging) — 1行
| id | status | returned_date | warehouse_order_code |
|--------|----------|---------------------|----------------------|
| 98765 | RETURNED | 2026-03-20 10:30:00 | SO-2026-00012345 |
> **テーブル**: 配送オーダーの全ライフサイクルを管理。スタイリング→発送→返却の状態遷移を追跡
### カラム説明
- **status**: 配送ステータス (1=発送待ち, 2=発送可能, 3=配達済み, 4=返却済み, 5=キャンセル)
- **returned_date**: お客様からの返却品を倉庫が受領した日時
- **warehouse_order_code**: bridge出荷オーダーとの連携コード
### 関連テーブル
- → **aircloset.会員テーブル** (user_id → id): 会員の基本情報…
- → **aircloset.プランマスタ** (plan_id → id): 月額プランの定義…
- ← **aircloset.スタイリングフィードバック** (delivery_id → id): お客様からの着用感想…
- ← **aircloset.レンタルアイテム** (delivery_id → id): オーダーに紐づくアイテム一覧…注目してほしいのは、クエリ結果の下にカラム説明と関連テーブルが自動付与されていることです。これはBQのグラフデータをRedisにキャッシュしておき、クエリ実行時に高速に付与しています (グラフ更新時にキャッシュクリア)。クエリ結果の意味がコンテキストなしで即座にわかり、AIにとっても次のアクション (「倉庫コードで bridge を引く」)の判断材料になります。
倉庫コードがわかったので、bridge 側の荷受状況を確認します。
> sql_query_database(database: "bridge", sql: "SELECT ... WHERE code = 'SO-2026-00012345'")
**bridge** (staging) — 1行
| code | status | receive_status | type | receive_datetime |
|------------------|---------|---------------|---------------|---------------------|
| SO-2026-00012345 | SHIPPED | COMPLETE | RENTAL_RETURN | 2026-03-21 14:22:00 |
> **テーブル**: 荷受処理の記録。返却品の到着確認と検品ステータスを管理
### カラム説明
- **status**: 出荷オーダーステータス (ORDERED→ALLOCATED→PICKED→INSPECTED→SHIPPED→CANCELED)
- **receive_status**: 荷受ステータス (IN_PROGRESS=実行中, COMPLETE=荷受済)
- **type**: 荷受種別 (RENTAL_RETURN=レンタル戻り, BUSINESS_RETURN=ビジネス戻り)
### 関連テーブル
- → **bridge.倉庫マスタ** (warehouse_id → id): 出荷元倉庫…
- → **bridge.店舗マスタ** (shop_id → id): 出荷元店舗…
- ← **bridge.荷受記録明細** (record_id → id): 荷受アイテムの個別明細…
- ← **bridge.出荷パッケージ** (order_id → id): 出荷時の梱包情報…**receive_status = COMPLETE — 倉庫で荷受確認済みです。**アプリ側の返却ステータスと、倉庫側の実際の荷受、両方が確認できました。
このエンリッチ機能がAI活用の肝です。Claude Codeは返ってきたカラム説明と関連テーブルを読んで、「次にどのテーブルを引くべきか」「このカラムの値はどう解釈すべきか」を自律的に判断できます。人間がいちいち教える必要がない。
応用: クロスサービスの分析クエリ
返却確認のようなオペレーション用途だけでなく、ビジネス分析にもそのまま使えます。
例えばこんな質問をClaude Codeに投げてみます。
スポットレンタルサービスで先週レンタルを行ったお客さまが何人で、そのうちエアークローゼットの月額会員が何%?そしてその方たちは、どれくらいの頻度でエアークローゼットを利用されてるの?
この質問に答えるには、スポットレンタルの注文テーブル (spot_rental スキーマ)とエアークローゼット本体の会員テーブル・利用履歴テーブル (aircloset スキーマ)を横断する必要があります。
Claude CodeはDB Graph MCPを使って、まず search_tables でスポットレンタル側の注文テーブルと aircloset 側の会員テーブルを特定し、trace_relationships で結合キーを探り、最終的に2つのDBに対してクエリを投げて集計結果を返してくれます。別々のデータベースにあるデータを、自然言語の質問ひとつで横断的に分析できる — これがDB Graph MCPの本質的な価値です。
DB Graph MCPがなかったら
これらの調査を、ツールなしでやることを想像してみてください。
返却確認の場合:
airclosetの配送オーダーテーブルの存在を知っている必要がある- スキーマ間をつなぐ倉庫連携テーブルの存在を知っている必要がある
- 倉庫オーダーコード (varchar)が
bridgeの出荷コードに対応していることを知っている必要がある bridgeの荷受記録テーブルが倉庫側の確認テーブルであることを知っている必要がある- ステータスのEnum値 (COMPLETE, RENTAL_RETURN)の意味を知っている必要がある
クロスサービス分析の場合:
- スポットレンタルのDBスキーマ名とテーブル構造を知っている必要がある
- エアークローゼット本体の会員テーブルとの結合キーを知っている必要がある
- 2つの異なるDBに対する接続情報をそれぞれ持っている必要がある
- 会員ステータスや利用回数の定義を正しく理解している必要がある
どちらのケースも、必要な知識が複数のサービス・スキーマにまたがっています。これらすべてを頭の中に入れている人は、おそらく5人もいない。DB Graph MCPなら、自然言語検索 → テーブル詳細 → リレーション追跡 → 実データクエリの流れで、誰でもたどり着けます。
ここからは、「なぜこれができるのか」を技術的に深掘りします。
ツール設計: 7つのツールの思想
DB Graph MCPは7つのツールを3つのカテゴリに分けています。
辞書ツール (DB認証情報不要)
| ツール | 用途 |
|---|---|
search_tables |
テーブル/カラムの名前検索 + ベクトル類似度検索 |
get_table_detail |
テーブルの全情報(カラム、FK、Enum、DEAD注釈) |
trace_relationships |
テーブル間リレーションのBFS追跡 |
辞書ツールはBigQueryに事前格納されたグラフデータを読むだけなので、個別のDB認証情報が不要です。Google OAuthでログインさえすれば、DB権限の申請なしにすぐ使えます。
クエリツール (DB認証情報が必要)
| ツール | 用途 |
|---|---|
list_databases |
アクセス可能なDB一覧 |
sql_query_database |
MySQL/PostgreSQLへSELECTクエリ実行 |
describe_database_table |
実DBのスキーマ取得 |
mongo_query_database |
DocumentDB/Atlasへfind/aggregate実行 |
クエリツールはFirestoreに登録された個人の認証情報を使って実DBに接続します。「自分がアクセス権を持っているDB」だけが見え、権限がないDBは一切見えません。
**この設計が重要なポイントです。**辞書は全員に開放し、データアクセスは権限制御する。「テーブルの存在は全員が知れるべきだが、データそのものは権限が必要」という思想です。
なぜBigQueryなのか — 技術選定の話
DB Graph MCPのグラフストアにはBigQueryを採用しています。「グラフDBならNeo4jとかじゃないの?」と思うかもしれません。
BigQueryを選んだ理由は、1つのストアでグラフ + ベクトル検索 + 分析クエリをすべて賄えるからです。
- VECTOR_SEARCH: embeddingカラムに768次元ベクトルを格納し、
VECTOR_SEARCH関数でコサイン類似度検索。これが自然言語検索の基盤。専用のベクトルDBを別途立てる必要がない - グラフ走査: ノードテーブル + エッジテーブルの構成でBFS走査を実現。
trace_relationshipsの裏側はシンプルなJOINの再帰クエリ - JSON型:
propertiesカラムにJSON型を使い、JSON_SETでレビューデータを柔軟に追記。スキーマ変更なしに属性を拡張できる - サーバーレス: インスタンス管理不要。日次バッチで数GBのデータを書いても、クエリ時しか課金されない
- Vertex AI連携: 同じGCP内でGemini 3 FlashによるAI説明文生成とEmbeddingモデルの呼び出しがシームレスにつながる
- Google Workspace連携: OAuth認証がGoogle Accountそのまま。社員のメールアドレスでドメイン制限・ニックネーム解決・権限管理が一気通貫で回る。別途IDプロバイダーを立てる必要がない
Neo4jのような専用グラフDBは走査性能では優れますが、991テーブル規模ならBigQueryで十分です。むしろ「ベクトル検索もJSONも分析もグラフも全部1つで完結する」利便性のほうが、運用コストの面で圧倒的に効いています。
自然言語検索の仕組み
「返却処理の確認」という自然言語から、なぜ荷受記録テーブルが見つかるのか。
ステップ1: テーブル説明の生成
DB Dictionary Graph Builderが毎日6
JSTに実行され、各テーブルに対してGemini 3 FlashでAI説明を生成します。例: bridge.荷受記録テーブル
→ "倉庫での荷受処理を記録するテーブル。レンタル戻りや
ビジネス戻りの種別を持ち、荷受完了/実行中のステータスで
処理進捗を管理する。出荷オーダーとの紐付けで、
どの注文の返却かを追跡できる。"この説明文がテーブルの「意味」を表現しています。
ステップ2: ベクトル埋め込みの生成
生成した説明文を、Vertex AIのEmbeddingモデルで768次元のベクトルに変換し、BigQueryに格納します。
ステップ3: VECTOR_SEARCH
ユーザーのクエリ「返却処理の確認」も同じモデルで768次元ベクトルに変換し、BigQueryの VECTOR_SEARCH でコサイン距離の類似度検索を行います。
SELECT base.qualifiedName, distance
FROM VECTOR_SEARCH(
TABLE `<project>.db_graph_nodes`,
'embedding',
(SELECT @query_embedding AS embedding),
top_k => 20,
distance_type => 'COSINE'
)
WHERE base.nodeType = 'Table'
ORDER BY distance ASC「返却」という単語はテーブル名に含まれていなくても、AI説明文に「レンタル戻り」「荷受処理」という意味的に近い記述があれば、ベクトル空間上で近い位置にマッピングされます。これが自然言語検索の核心です。
グラフの構築
6段階パイプライン
DB Dictionary Graph Builderは、毎日6つのフェーズでグラフを構築します。
(図のBuilder部分を参照)
① ORM解析 — 28リポジトリから4種類のORM (TypeORM, Sequelize, Drizzle, Mongoose)を解析し、テーブル定義を抽出。
② ライブDB検証 — Lambda経由で実際のstaging DBに INFORMATION_SCHEMA クエリを投げ、コード上の定義と実DBの差分を検出。「コードにはあるが実DBには存在しないテーブル」を自動で除外。
③ AI Description — Gemini Flashでテーブル/カラムの説明を自動生成。差分検出 (incremental detection)により、変更があったテーブルのみ再生成することでAIコストを最小化。
④ グラフ構築 — 4種類のノード (Schema / Table / Column / Enum)と5種類のエッジ (HAS_TABLE / HAS_COLUMN / REFERENCES / USES_ENUM / SAME_ENTITY)を生成。
⑤ Embedding生成 — Vertex AIでテーブル単位の768次元ベクトルを生成。
⑥ BQ MERGE — BigQueryにMERGEでロード。このとき、人間が手動で書いた説明文やDEADフラグを保護する。自動生成データで上書きしない。
リレーションの信頼度レベル
外部キー情報は、検出方法によって信頼度が異なります。
| 信頼度 | 検出方法 | 説明 |
|---|---|---|
explicit |
ORMの @JoinColumn() や belongsTo() から直接検出 |
確実 |
inferred |
xxx_id → xxx テーブルという命名規則で推定 |
高確率 |
manual |
人間がレビューで追加 | 確実 |
これにより、AIが生成するJOIN条件の信頼性を事前に判断できます。
SAME_ENTITYエッジ
同じ論理エンティティがSQLとMongoDBの両方に存在することがあります。例えば aircloset の会員テーブル (MySQL)と aircloset のユーザー統計コレクション (MongoDB)は同じユーザーを指している。このクロスDB / クロスエンジンの対応関係を SAME_ENTITY エッジで表現し、横断的な検索を可能にしています。
人間によるレビュー: AIだけでは完結しない
ここまで読んで、「AI生成の説明文って本当に正確なの?」と思った方もいるでしょう。正直に言うと、AI生成だけでは不十分です。
Gemini 3 Flashは大枠の説明はうまいですが、10年分のビジネス文脈 — 「このカラムは3年前に移行済みだけどスキーマからは消えていない」「このEnumの値5は実は使われていない」 — こういった暗黙知はAIだけでは埋められません。
だからこそ、人間がレビューする仕組みを最初から組み込んでいます。
レビューWeb UI
社内向けにDB Dictionaryのレビュー専用Webアプリを用意しています。
スキーマ一覧画面では、各スキーマのレビュー進捗がプログレスバーで表示されます。テーブル一覧画面では「未確認」「確認済み」「廃止あり」でフィルタリングできます。
テーブル詳細画面では、カラムごとの型・FK先・Enum定義が一覧表示され、その場で説明文の編集や廃止マークの設定ができます。
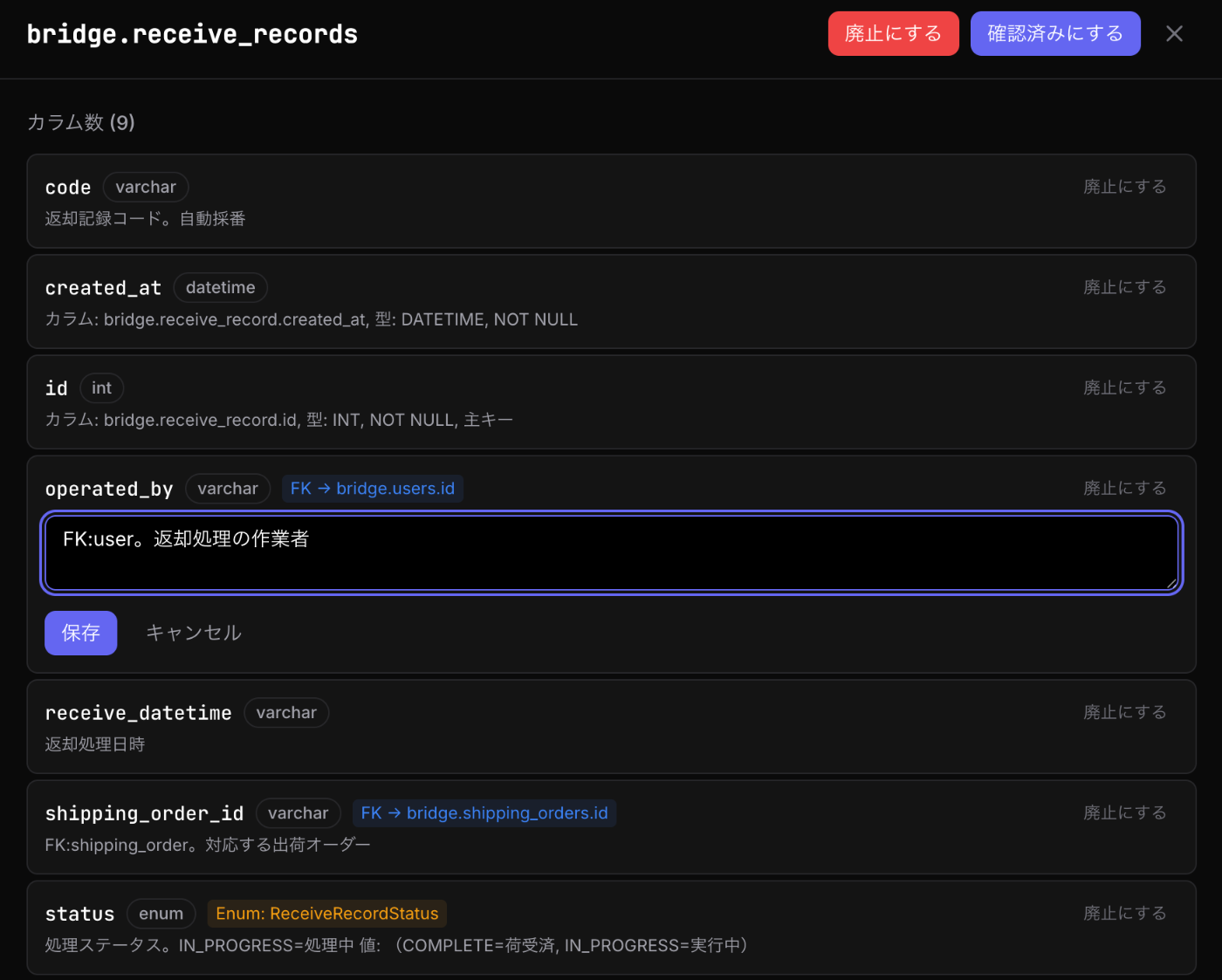 レビューUI: カラムごとにFK先やEnum定義がバッジ表示され、説明文をインライン編集できる
レビューUI: カラムごとにFK先やEnum定義がバッジ表示され、説明文をインライン編集できる
テーブル詳細画面では、以下の操作が可能です。
| 操作 | 内容 |
|---|---|
| テーブル説明の編集 | AI生成の説明に補足を加える、または完全に書き直す |
| カラム説明の編集 | カラムごとの注釈(「非推奨」「このカラムではなくXXを使え」など) |
| 廃止マーク(DEAD) | テーブルまたはカラム単位で廃止フラグ + 理由 + 空率を記録 |
| 確認済みチェック | レビュー完了時にチェック。チェック者と日時が記録される |
| 一括廃止マーク | 複数テーブル/カラムを一度にDEAD設定(最大500件) |
DEADフラグ: 10年分の暗黙知を可視化する
10年運用していると、使われなくなったカラムがテーブルに残り続けます。かつて会員種別を表していたフラグがあるが、数年前に別カラムに移行済みで、旧カラムはほぼ全行NULL、というケースです。
レビューで人間が廃止フラグを付けると、MCP経由のテーブル詳細にこう表示されます。
- 旧会員フラグ: int [NOT NULL, default=0, DEAD] ⚠ 非推奨。会員ステータスカラムが正
- キャンセル日時: datetime [DEAD] ⚠ 全行NULL
- 旧連携ID: varchar [DEAD] ⚠ レガシーCSVインポート用。現在未使用これがなぜ重要かというと、AIがこのカラムを参照して間違ったコードを書くことを防ぐからです。Claude Codeがテーブル詳細をコンテキストに読み込んだとき、DEADフラグがあれば「このカラムは使うべきでない」と判断できます。
変更検知と差分レビュー
日次ビルドでテーブル構造やAI説明文に変更が検出されると、「ペンディング変更」として記録されます。レビュアーはWeb UIで変更内容のbefore/after差分を確認し、「確認済み」をクリックします。
change_type: columns_changed
識別名: aircloset.会員テーブル
Before: "会員の基本情報を管理するテーブル。メールアドレス、氏名..."
After: "会員の基本情報を管理するテーブル。メールアドレス、氏名、新しく追加された..."
^^^^^^^^^^^^^^^^ NEW
→ [Mark as Reviewed] ボタン → reviewedBy / reviewedAt が記録これにより、「昨日のビルドで何が変わったか」を見落とさない仕組みになっています。
レビューデータの永続化
レビューデータはFirestoreに保存され、日次ビルドで上書きされません。
Firestore db_dictionary_reviews:
qualifiedName: "aircloset.会員テーブル.旧会員フラグ"
humanDescription: "非推奨。membership_statusカラムが正しい値を持つ"
isDead: true
deadNote: "3年前に移行済み。全行0"
checkedAt: "2026-03-25T10:00:00Z"
checkedBy: "ryan@air-closet.com"日次ビルドでは以下の順序で処理されます。
- ORM解析 → グラフ構築 — 最新のコードからテーブル定義を再抽出
- BQ MERGE — 既存の
textForEmbedding(人間が書いた説明文)やembeddingを保護しながらMERGE - Firestoreからレビュー再適用 —
humanDescription,isDead,deadNote,checkedAtなどをBQのpropertiesに再書き込み
つまり、レビューした内容は毎日の自動ビルドを何度繰り返しても消えない。Firestoreが正 (source of truth)で、BQはその反映先です。
VPCの壁を越えるクロスクラウドアーキテクチャ
ここからがセキュリティ的なこだわりポイントです。
問題: MCPサーバーはGoogle Cloud (Cloud Run)で動いている。でもデータベースはAWSのVPC内にある。Cloud RunからVPC内のRDS / DocumentDBには直接アクセスできない。
解決: GCP OIDC → AWS STS → VPC内Lambdaという3段階の認証チェーンで、セキュアにクロスクラウド接続を実現しています。
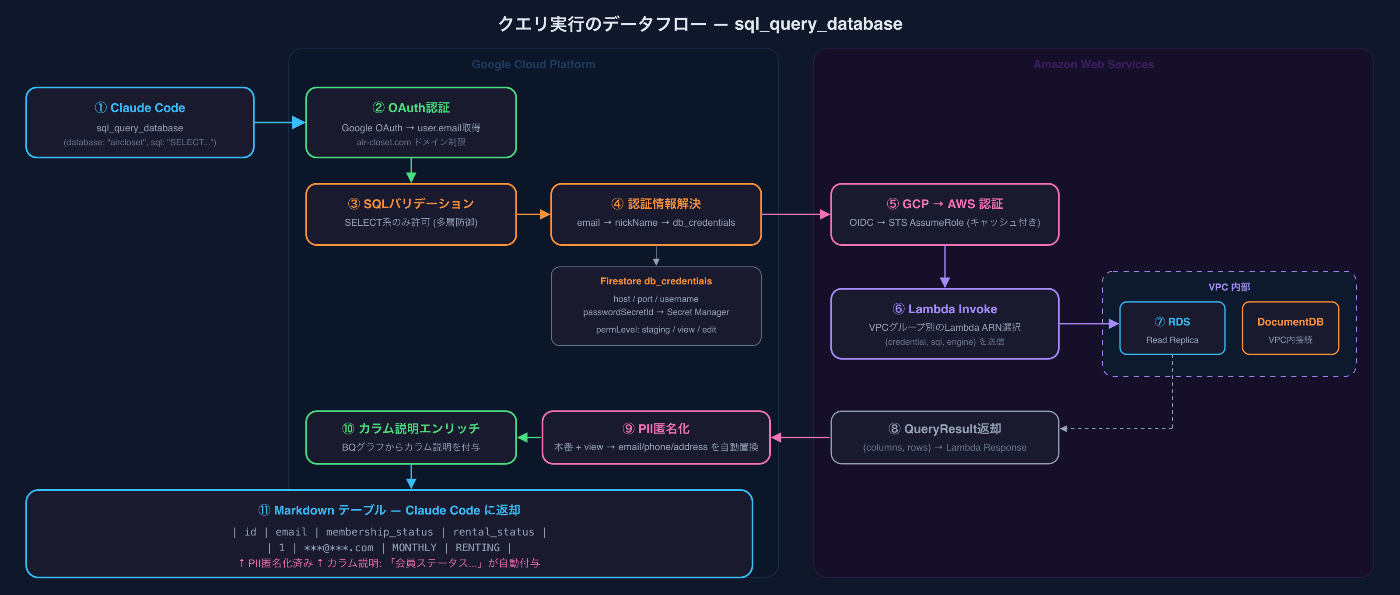
認証の流れ
1. Cloud Run (GCP) → GCPメタデータサーバーからOIDCトークン取得
2. OIDCトークン → AWS STS AssumeRoleWithWebIdentity
3. STS → 一時的なAWS認証情報を返却(1時間有効)
4. 一時認証情報 → VPC内Lambda を Invoke
5. Lambda → VPC内のRDS/DocumentDBにクエリ実行ポイント:
- 静的なAWS認証情報は一切持たない。 GCPのサービスアカウントから動的に取得。
- **一時認証情報を5分間キャッシュ。**毎回STSを呼ぶオーバーヘッドを回避。
- LambdaはVPC内で実行。 DB接続はVPC内で完結し、インターネットに出ない。
- **本番SQLはRead Replica経由。**マスターDBには絶対に接続しない。
SQLバリデーション (多層防御)
クエリの安全性は2層で検証しています。
MCP側 (1層目):
許可: SELECT, SHOW, DESCRIBE, DESC, EXPLAIN, WITH...SELECT
拒否: INSERT, UPDATE, DELETE, DROP, CREATE, ALTER, TRUNCATE, セミコロンによる複数クエリの実行Lambda側 (2層目): 同じバリデーションをLambda内でも実行。MCP側が万が一突破されても、Lambda側でブロックします。
本番データの安全な取り扱い — PII匿名化
本番データをクエリできるのは便利ですが、個人情報 (PII)の取り扱いは最も神経を使う部分です。
自動匿名化ルール
本番環境 + viewクエリの結果に対して、PIIカラムの値を自動的に匿名化します。
| カラムパターン | 置換値 |
|---|---|
| メールアドレス系 | ***@***.com |
| 氏名系 | *** |
| 電話番号系 | ***-****-**** |
| 郵便番号系 | ***-**** |
| 住所系 | *** |
| パスワード系 | [REDACTED] |
| 生年月日系 | ****-**-** |
| カード番号系 | [REDACTED] |
さらに、テーブル固有のルールも定義しています。例えば name というカラム名はグローバルには汎用的すぎてPII扱いできませんが、会員テーブルや注文テーブルの name は明らかにPIIです。こういったケースはテーブル単位で個別ルールを設定しています。
staging vs production
| 環境 | PII匿名化 | 接続先 |
|---|---|---|
| staging | なし | マスターDB |
| production (view) | 自動適用 | Read Replica |
| production (edit) | なし | Read Replica |
staging環境はテストデータなので匿名化不要。本番のview権限にだけ匿名化が自動適用されます。
権限管理の完全自動化 — DB Account Pipeline
「このDBにアクセスしたいんですけど、誰に聞けばいいですか?」
この質問が来なくなりました。DB Account Pipelineがすべてを自動化しているからです。
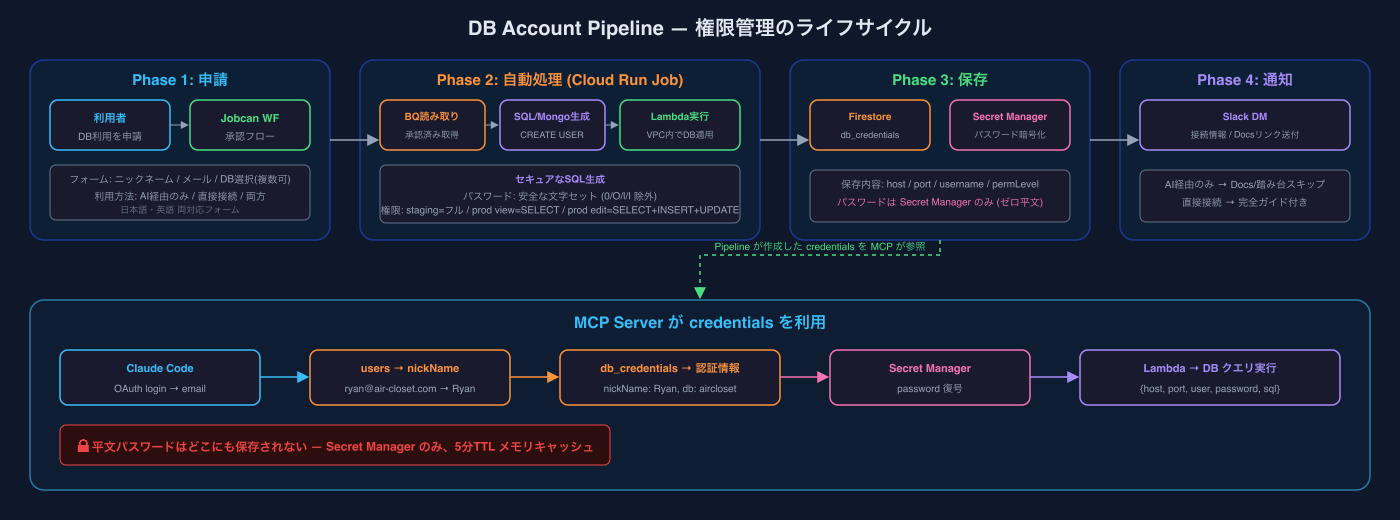
フロー
- 利用者がワークフローで申請 — ニックネーム、メールアドレス、利用したいDB (複数選択可)を入力
- マネージャーが承認
- Cloud Run Jobが自動処理 — 承認済み申請を読み取り、DB別にCREATE USERを生成し、Lambda経由で実行
- 認証情報をFirestore + Secret Managerに保存 — パスワードは平文で保存しない
- Slack DMで接続情報を通知 — 踏み台サーバーの接続ガイド付き
セキュアなパスワード生成
// 混同しやすい文字を除外した文字セット
PASSWORD_CHARSET = 'abcdefghijkmnpqrstuvwxyzABCDEFGHJKLMNPQRSTUVWXYZ23456789'
// 除外: 0/O(混同)、l/1/I(混同)、$/;/'(SQL問題)ユーザー名は {ニックネーム}_{環境}_{権限}_user の形式で、一目で誰のどの権限のアカウントかわかるようにしています。
ゼロ平文パスワード
パスワードの保存先はSecret Managerのみです。
Firestore db_credentials:
host: "xxx.rds.amazonaws.com"
port: 3306
username: "ryan_view_user"
passwordSecretId: "db-cred-xxxxx" ← Secret Managerへの参照のみ
permLevel: "view"MCP Serverがクエリを実行するとき、passwordSecretId からSecret Manager経由でパスワードを復号し、5分間のメモリキャッシュに載せます。Cloud Runが再起動すればキャッシュはクリアされます。
どこにも平文パスワードが保存されないという設計は、かなりこだわったポイントです。
運用
日次cron
毎日6
JSTにcronが起動し、Cloud Run Jobを実行します。6:00 JST — cron起動
├── ORM解析(28リポ × 5 ORM)
├── ライブDB検証(11 staging DB)
├── Gemini説明文生成(差分のみ)
├── グラフ構築 + Embedding
├── BQ MERGE(アノテーション保護)
└── Slack通知コスト
| リソース | コスト |
|---|---|
| Gemini 3 Flash(日次) | ~$0.1-0.2/日 |
| Vertex AI Embedding | ~$0.01/日 |
| Cloud Run Job | ほぼ無料(1日1回) |
| BQストレージ | 数GB |
| Lambda | DB Account Pipelineと共用 |
月額10$以下で991テーブルのAI辞書を維持しています。
インクリメンタル検出
全テーブルの説明を毎日再生成するとGeminiのコストが跳ね上がります。そこで、差分検出を導入しました。
1. 前回のプロパティハッシュと比較
2. カラム構造の変化を検出(追加/削除/型変更)
3. Enum依存グラフから影響テーブルを特定
→ 変更があったテーブルのみ再生成例えば、あるステータスEnumが変更されたら、そのenumを使っている全テーブルが再生成対象になります。変更がなければスキップ。これでAIコストを約90%削減しています。
セキュリティまとめ
最後に、セキュリティ設計を一覧にまとめます。
| 層 | 保護内容 |
|---|---|
| OAuth | Google Account + 社内ドメイン制限 |
| 認証情報解決 | メール → ニックネーム → 個人別DB認証情報 |
| 権限フィルタ | 個人ごとのDB × 環境 × 権限レベル |
| SQLバリデーション(MCP) | SELECT系のみ許可 |
| SQLバリデーション(Lambda) | 同等の検証(多層防御) |
| PII匿名化 | 本番 + viewのクエリ結果のみ |
| 本番接続先 | Read Replicaのみ |
| パスワード | Secret Managerのみ保存、5分TTLキャッシュ |
| クロスクラウド認証 | GCP OIDC → AWS STS(静的認証情報なし) |
| ログ | パスワード・クエリ結果はログ出力しない |
まとめ
DB Graph MCPは、「テーブルの存在を知らないと使えない」というDBの根本的な課題の解決どころか、「SQLをまったく知らなくても実データの検索を可能にする」ツールです。
- 辞書として — 991テーブルの構造・リレーション・Enum定義を、自然言語で検索可能
- クエリツールとして — staging / productionの実データをセキュアに参照可能
- ナレッジベースとして — DEADフラグやカラム注釈で、10年分の暗黙知を可視化
作ってみて実感したのは、**MCPの本質的な価値は「AIにコンテキストを与えること」**だということです。テーブル構造、リレーション、Enum定義、カラムの注意書き — これらがAIのコンテキストに入ることで、Claude Codeが書くSQLやコードの精度が格段に上がります。
そしてそれを実現するためには、グラフの構築、クロスクラウドのセキュアなアクセス、権限管理の自動化、PII保護 — 地味だけど重要な基盤を丁寧に作り込む必要がありました。
この記事が、社内DBの管理に悩んでいる方の参考になれば嬉しいです。
comments (0)
まだコメントはありません。