みなさまこんにちは!エアークローゼットでCTOをしている辻です。
これまでに DB Graph MCP、社内MCP群の全体像、Biz Graph、Sandbox MCP と、社内向けに作っているMCPサーバーを順に紹介してきました。
DB GraphはORM解析からのスキーマグラフ、Biz Graphは会議スライドからの施策抽出とWeekノード設計、Sandbox MCPはそもそもアプリ公開基盤 ── 目的も実装も全部違うのですが、自分でも書きながら気づいたのは、設計の根っこにある考え方は同じだということです。
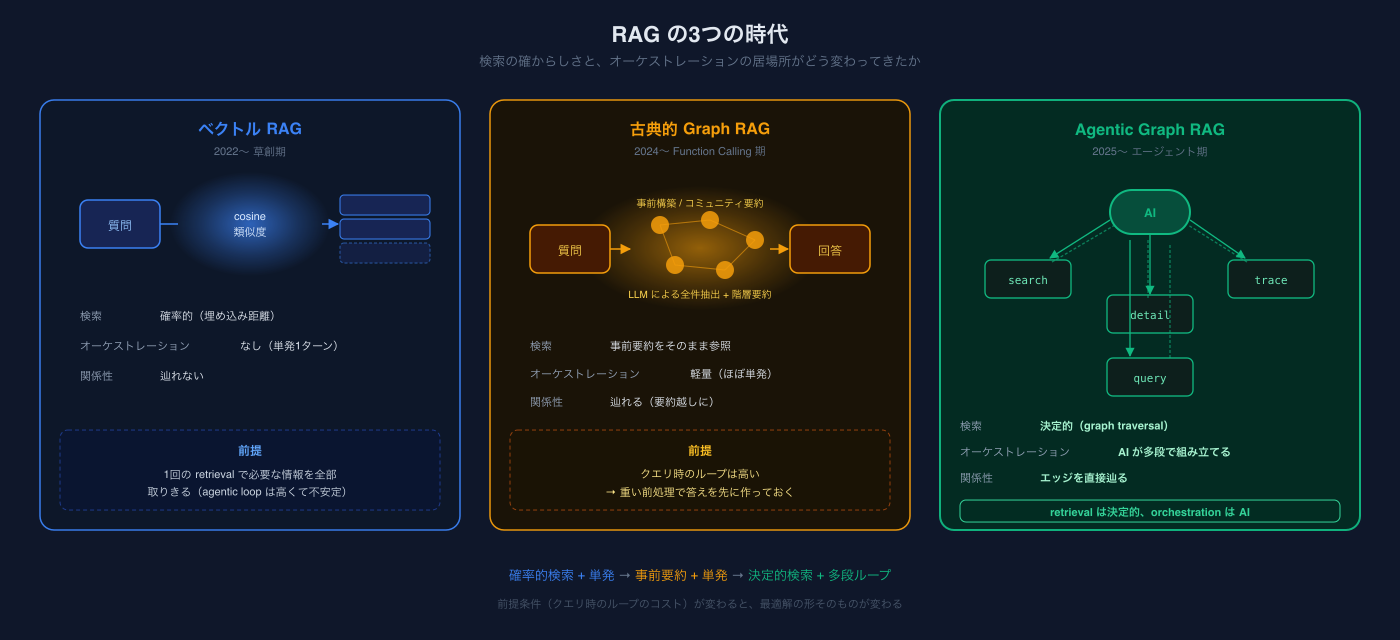
今回はその根っこの話をします。Agentic Graph RAG ── 私たちが社内のいろんな領域でグラフを作るときに、繰り返し採用している設計フレームの話です。
「Graph RAGなら聞いたことある」「MicrosoftのOSSでしょ?」と思った方、ちょっと待ってください。同じ「Graph RAG」という言葉でも、単発検索前提の時代とAIエージェント前提の時代では、最適解がまったく違います。この記事は、後者 ── Claude CodeやCodexのようなエージェントが当たり前になった時代の、新しいGraph RAG設計論です。
そもそもRAGとは
最初に、用語を整理します。すでにご存じの方は読み飛ばしてください。
**RAG (Retrieval Augmented Generation)とは、LLMに回答させる前に外部データから関連情報を検索 (Retrieval)**してプロンプトに混ぜ込む手法の総称です。
なぜこれが必要だったか。生成AIの草創期 ── 2022年末〜2023年頃 ── に、私たちが直面した課題は3つありました。
- コンテキスト窓が狭い: GPT-3.5は4Kトークン、初期のGPT-4でも8Kトークン。社内ドキュメントを丸ごと入れることは不可能だった
- モデルの知識が古い: 学習データのカットオフ以降の情報は知らない。社内データは当然知らない
- ハルシネーション: 知らないことも自信満々に答える。「それっぽい嘘」が混入する
これらに対して、「毎回外部データから関連箇所だけ取り出してプロンプトに足してから推論させればいいじゃん」というのがRAGの発想です。
ベクトルRAG ── 「とりあえず検索」の最適解
最初に普及したRAGの実装がベクトルRAGです。
仕組みはシンプル。
- ドキュメントを小さなチャンク(例: 500トークンごと)に分割
- 各チャンクをEmbeddingモデルでベクトル化(例: 1536次元)
- ベクトルDB(Pinecone、Weaviate、pgvector等)に格納
- ユーザーの質問もベクトル化し、cosine類似度でtop-k件を取り出す
- 取り出したチャンクをプロンプトに混ぜてLLMに投げる
これが当時の文脈ではよくできた発明でした。なぜなら、
- 検索が速い: ベクトル検索は数十〜数百msで終わる
- 教師データ不要: ドキュメントを与えれば即座に検索可能(インデックス構築のみ)
- ドメイン非依存: 法律文書でも医療カルテでも社内Wikiでも、同じ仕組みが動く
- モデル進化に乗れる: Embeddingモデルが良くなれば検索精度も上がる
そして当時のAIエージェント技術はまだ未熟でした。OpenAIのFunction Callingは2023年6月にようやく登場、しかも初期は不安定で、エージェントが何度もツールを呼び出す「agentic loop」を回すのは時間もコストもかかる。だから「1回のretrievalで答えに必要な情報を全部取ってくる」という前提でRAGは設計されていました。ベクトルRAGはこの前提に最適化されている。
ベクトルRAGの限界
ただ、運用しているとすぐに気付きます。ベクトルRAGは「関係性」を辿れない。
例えば、こんな質問を考えてみてください。
「先月のSNS広告キャンペーンが、新規会員数にどう影響したか?」
ベクトル検索は、この質問文にテキストとして似ているチャンクを返します。たぶん「SNS広告キャンペーン」の説明資料は引っかかる。でも、
- そのキャンペーンがいつ実施されたか
- その同じ期間の新規会員数はいくつだったか
- 過去に類似のキャンペーンでどんな結果だったか
これらは、テキストの類似度ではなくデータの構造的な繋がりを辿らないと取れません。Embeddingは「春のSNS広告」と「春のキャンペーン施策」を近い位置にマッピングしますが、「3月1日〜3月31日に実施された」という事実から「同じ期間のKPI値」を引っ張ってくることはできない。これは類似度の問題ではなく、結合の問題だからです。
加えて、
- チャンク分割で文脈が途切れる: ページ境界で関係情報が分断される
- top-kのcliff: 11位に重要な情報があっても見えない
- 粒度のミスマッチ: 「全体像を要約して」のような質問はチャンクを集めても答えられない
ベクトルRAGは「質問にテキストとして近い情報を1ステップで持ってくる」ことには最適でしたが、「情報と情報の関係を辿る」ことには弱い。これが次世代のRAG ── Graph RAG ── が生まれた背景です。
Graph RAG ── 関係性を辿る検索
Graph RAGの基本アイデアは、ドキュメントからエンティティ(人、組織、概念)と関係(所属する、影響する、参照する)を抽出し、グラフとして保存することです。検索時には、関連エンティティをグラフ上で辿りながら情報を集める。
これにより、「先月のSNS広告キャンペーンと新規会員数の関係」のような複数ホップが必要な質問に答えられるようになります。
古典的Graph RAG ── 単発検索時代の制約
現在もっとも有名な実装は、Microsoftが2024年に出した GraphRAG です。論文も含めてよく書かれていて、私もリスペクトしています。ただ、設計思想は完全に「単発検索前提の時代」のものです。
Microsoft GraphRAGが何をするか、ざっくり言うと:
- エンティティ抽出: コーパスの全テキストをLLMに食わせ、エンティティと関係を抽出
- コミュニティ検出: グラフ上のクラスタ(コミュニティ)を Leiden法(コミュニティ検出のアルゴリズム)で検出
- 階層的要約: 各コミュニティについてLLMで要約を生成。さらにコミュニティ同士をまとめて上位の要約も作る
- クエリ時: ユーザーの質問に該当するコミュニティを選び、その要約をプロンプトに突っ込んで一発で答える
これがなぜこんなに重い前処理になっているか。「クエリ時に何度もツールを呼び出すのは現実的じゃない」という当時の前提があるからです。Function Callingのループは遅くて高くて不安定。だから事前にコーパス全体をLLMで舐めて、コミュニティ単位の要約を作り込んでおく。クエリ時に1〜2回の検索で完結させるためにここまでやる。
これは技術的な怠慢ではなく、当時の合理的な設計判断です。LangChainのRetrievalQAも、LlamaIndexのクエリエンジンも、根っこは同じ思想 ── 「retrievalは単発、生成は1ターン」を前提に組まれていました。
古典的Graph RAGが解いたこと、解けなかったこと
解いたこと:
- 関係性を辿る検索(コミュニティ要約のおかげで「全体像」も取れる)
- 「Sam AltmanとOpenAIとMicrosoftの関係」のような多ホップ質問
解けなかったこと:
- 構築コストが高い: 大規模コーパスの全エンティティ抽出はLLM料金がガッツリかかる
- スキーマがLLM任せ: 抽出されるエンティティ・関係はLLMの判断次第。公知の知識(論文・ニュース等)には適合しやすい一方、自社固有の暗黙知に依存するドメインではビジネスにとって意味のある単位と一致しないことがある
- 更新が重い: 新規ドキュメントが入るたびにコミュニティ再計算
- 的外れも起こる: コミュニティ要約が抽象化されすぎて、本当に必要な具体情報が落ちてしまう
正直に書くと、私自身は古典的Graph RAGをプロダクションで真剣に試したことはありません。社内でグラフ系のMCPを作り始めた時点ですでにClaude Codeが手元で動いていて、エージェントが多段でツールを呼ぶことが当たり前の世界から出発したからです。結果として「単発検索で全部終わらせる」前提に基づくコミュニティ要約のような重い前処理を組む必要がそもそも無かった。事前に圧縮した答えを準備しなくても、AIが必要に応じて何度でも引きに行けるなら、グラフは事実だけを正確に保持していればいい。
裏を返すと、もし2023年頃に同じことをやろうとしていたら、私たちもおそらくコミュニティ要約のような道に進んでいたと思います。古典的Graph RAGの設計者たちが解こうとしていた問題は本物で、ただ前提条件のほうが先に変わったというだけのことです。
時代が変わった ── Agentic前提の世界
2024年後半から2025年にかけて、状況が変わりました。
- Claude Code、OpenAI Codexなどのエージェントが実用レベルに: 長いタスクを自分でツールを呼びながら進められる
- MCP (Model Context Protocol) の登場: ツールの記述がモデルから読みやすい形で標準化された
- Sonnet / Opusクラスのツール選択精度: 「20個のツールから最適なものを選ぶ」が安定して回る
- 長コンテキスト + プロンプトキャッシュ: 1セッションで何回もツール呼び出しを重ねても、コストとレイテンシが現実的
stop_reason: tool_useの自然なループ: モデル自身が「もう情報足りた」「もう一回検索したい」を判断する
これらが揃った結果、「retrievalは単発で全部取らないと割が合わない」という前提が崩れた。1回のセッションで5回でも10回でもツールを呼び出すのが当たり前になった。
つまり、Microsoft GraphRAGが前提にしていた制約 ── 「クエリ時のループは高い」── が消えたわけです。
これはMicrosoft GraphRAGが「古い」という話ではありません。当時の制約に対する正しい答えだった。今は制約が変わったので、最適解も変わるというだけのことです。
Agentic Graph RAG ── 検索は決定的、判断はAI
なお、Agentic Graph RAGという呼び方は私が独自に作った言葉ではありません。Neo4jの NODES AI 2026 では「Agentic GraphRAG」のセッションが組まれていますし、O'ReillyからはAnthony Alcaraz / Sam Julien共著の書籍 Agentic GraphRAG が2026年11月に刊行予定です。業界全体が「単発のGraph RAG」から「エージェント前提のGraph RAG」へ舵を切っている流れの中で、私たちが社内で独自に積み上げてきた設計を改めて言語化したのがこの記事です。
ただし、公の文脈で「Agentic GraphRAG」と呼ばれるとき、その主流はエージェントがグラフ構築自体を自動化する方向で語られます(Neo4jのtalkもその系譜です)。本記事が取り込んでいるのは、その中でも**「クエリ側をエージェント化する」概念のほうに限った話です。グラフ構築の側は、私たちが対象にしているドメイン(社内DBスキーマ、施策 × KPI、コードベース等)が社内の暗黙知に強く依存**するため、現時点では人間が設計したほうが結果が良い ── という実利的な理由で自分たちでやっているだけで、構築の自動化を原理的に否定しているわけではありません。
ここから本題です。Agentic Graph RAGの核心は、ひとことで言うとこうです。
検索の各ステップは決定的、オーケストレーションだけがAI
ベクトルRAGは「検索そのもの」が確率的でした。Embeddingのcosine類似度はあくまで近似で、たまたま外す。だからretrieval層がハルシネーションの種を含んでいた。
古典的Graph RAGは、検索を一回きりで全部終わらせる前提だった。事前に重い処理をして「答えそのもの」を準備しておいて、クエリ時はそれを引くだけ。
Agentic Graph RAGの発想は、その間にある。
- グラフは人間が設計する。私たちが扱うのは社内の暗黙知に依存するドメインなので、スキーマも、ノードも、エッジも、人間が「この粒度でデータを切り取りたい」と決めるほうが結果が良い
- 各ツール呼び出しは決定的に動く。IDを渡せば、それに紐づくノードやエッジを必ず取得する。ベクトル類似度のような揺らぎはない
- ただし「次にどのツールを呼ぶか」「どのIDをパラメータに入れるか」「いつ止めるか」はAIが判断する
これにより、間違いの場所が局所化される。retrieval自体は決定的なので、間違うとしたら「AIが入口を間違えた」「AIが早く打ち切った」のどちらかだけ。出力されたデータは事実そのもの。
ツール返却値がrunbookになる
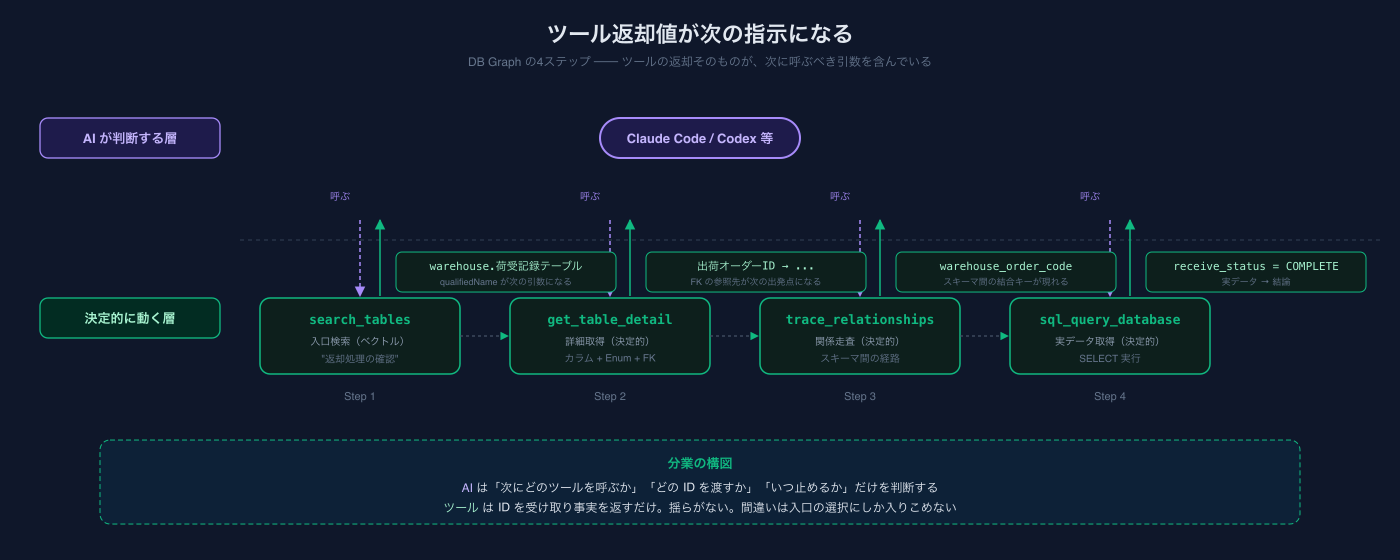
Agentic Graph RAGの設計でいちばん大事なのは、ツールの返却値が「次に何をすべきか」をAIに伝えることです。
これは普通のAPIの感覚とは違います。普通のAPIは「呼ばれた質問に答えればいい」。でもMCPのツールは、AIと会話しているわけです。会話相手から欲しいのは「答え」だけじゃなく、「次の手の候補」でもある。
具体例で説明します。
DB Graph MCPの search_tables ツールを呼ぶと、こう返ってきます。
5件のテーブルが見つかりました(ベクトル類似度順):
warehouse.返送パッケージテーブル (postgresql) (距離: 0.2557)
warehouse.荷受記録テーブル (postgresql) (距離: 0.2720)
inventory.荷受確認結果テーブル (mysql) (距離: 0.2921)
warehouse.荷受記録明細テーブル (postgresql) (距離: 0.2951)
app.返送ステータス変更履歴テーブル (mysql) (距離: 0.3170)※ 説明用にスキーマ名・テーブル名は一般化しています。実際は社内のシステム由来の名前です。
注目してほしいのは、返却の中に「次に呼ぶべきツールの引数」が既に入っていることです。warehouse.荷受記録テーブル というqualified nameは、そのまま get_table_detail(table_name: "warehouse.荷受記録テーブル") の引数として使える。AIは「次は詳細を見るか」と判断したら、そのままコピペすればいい。
get_table_detail の返却はもっと露骨です。
# warehouse.荷受記録テーブル
DB: POSTGRESQL / ORM: typeorm / リポジトリ: warehouse-api
## カラム (9)
- id: int [PK, AI, NOT NULL]
- 出荷オーダーID: varchar [NOT NULL]
- status: enum [NOT NULL, default=IN_PROGRESS]
- ...
## 参照先 (2)
- 出荷オーダーID → warehouse.出荷オーダーテーブル.id (explicit)
- 操作者ID → warehouse.ユーザーテーブル.id (explicit)
## Enum/ステータス定義 (2)
- Status: COMPLETE=荷受済, IN_PROGRESS=実行中
- Type: RENTAL_RETURN=レンタル戻り, ...この返却はAIに対して、暗黙的に次のことを伝えています。
- 「statusカラムの意味はEnum定義に書いてある」 → AIは意味を勝手に推測しない
- 「参照先がある」 → 必要なら
trace_relationshipsで辿れる - 「app側との直接FKはない」 → 別経路を探す必要がある
つまり、ツール返却値が「AI向けのrunbook」になっている。AIはこれを読んで自律的に次の手を組み立てられる。
さらに、sql_query_database で実データを取ってきたときの返却を見てください。
**app** (staging) — 1行
| id | status | warehouse_order_code |
|--------|----------|----------------------|
| 98765 | RETURNED | SO-2026-00012345 |
> **テーブル**: 配送オーダーの全ライフサイクルを管理...
### カラム説明
- **status**: 配送ステータス (1=発送待ち, 2=発送可能, 3=配達済み, 4=返却済み, ...)
- **warehouse_order_code**: warehouse 側の出荷オーダーとの連携コード
### 関連テーブル
- → **app.会員テーブル** (user_id → id)
- → **app.プランマスタ** (plan_id → id)
- ← **app.注文履歴テーブル** (delivery_id → id)クエリ結果の下にカラム説明と関連テーブルが自動付与される。これは事前にBQに格納したグラフから動的に組み立てています。AIは「warehouse_order_code はwarehouseとの連携用」と書いてあるのを読んで、次に「warehouse側のテーブルをこのコードで引く」と即座に判断できます。
人間がいちいち「次はwarehouseを見て」と教える必要がない。返却値そのものが指示書。
DB Graphでの実演 ── 4ステップで本番調査が完結する
実際の流れをもう一度通しで見ます(DB Graph MCPの記事から再掲)。
CSから「この会員さん、アプリでは返却済みになってるけど、倉庫側で本当に確認できてますか?」と聞かれた、というシナリオです。
Step 1: 自然言語でテーブルを探す(ベクトル類似度の入口検索)
search_tables(query: "返却処理の確認", search_type: "semantic")
→ warehouse.荷受記録テーブル, warehouse.返送パッケージテーブル, ...Step 2: 中身を見る(決定的な詳細取得)
get_table_detail(table_name: "warehouse.荷受記録テーブル")
→ status=COMPLETE が「倉庫で荷受完了」
→ 出荷オーダーIDで warehouse.出荷オーダーテーブル と繋がるStep 3: 別スキーマとの結合経路を探す(決定的なグラフ走査)
trace_relationships(table_name: "warehouse.出荷オーダーテーブル", direction: "both")
→ app 側からは中間テーブル経由で繋がる
search_tables(query: "倉庫連携")
→ app.倉庫連携テーブル (warehouse_order_code が warehouse.出荷オーダー.code に対応)Step 4: 実データで確認(決定的なクエリ実行)
sql_query_database(database: "app", sql: "SELECT ... WHERE user_id=12345 AND status='RETURNED'")
→ warehouse_order_code = "SO-2026-00012345" を取得
sql_query_database(database: "warehouse", sql: "SELECT ... WHERE code='SO-2026-00012345'")
→ receive_status = COMPLETE → 倉庫で荷受確認済みここで重要なのは、この4ステップをAIが自律的に組み立てていることです。人間が指示したのは最初の質問だけ。各ステップの返却に「次はこっちを見ろ」という情報が入っているから、AIが次のツール呼び出しを正しく組める。
そして各ステップのretrievalは決定的です。warehouse.荷受記録テーブル のstatusカラムのenum定義は、グラフから引いた事実そのもの。AIが想像で書いた値ではない。warehouse_order_code = SO-2026-00012345 は実データそのもの。AIが捏造したIDではない。
これがベクトルRAGとも古典的Graph RAGとも違う体験になります。ベクトルRAGは「全部1回でテキストを返す」が、ハルシネーションが混じる。古典的Graph RAGは「全部1回でコミュニティ要約を返す」が、要約のせいで具体情報が落ちる。Agentic Graph RAGは「5回でも10回でも引きに行く、ただし1回1回は事実だけ」。
同じパターンを社内のあちこちに
このパターン ── 私たちが採用している「人間設計のグラフ + 決定的なretrievalツール + AI向けrunbookな返却値」 ── は、DB GraphとBiz Graphだけのものじゃありません。社内のMCPサーバー群で何度も繰り返し使っています。
社内MCP群の全体像 で名前だけ紹介していたものも含めて並べると、こんなラインナップになります。
| グラフ | 対象 |
|---|---|
| DB Graph | 社内 991 テーブル × 15 スキーマ |
| Biz Graph | 5,000+ 施策 × 4,000+ KPI |
| Code Graph | 全社リポジトリのコード関数・API・イベント |
| Cortex Product Graph | cortex リポジトリ内のコード + DB + docs + infra 統合 |
| Service Product Graph | 各サービスの API → DB の依存 |
どれも構造が違います。DB GraphはORM解析、Biz Graphは会議スライドからの抽出 + 人間設計のMetricDomain、Code Graphは静的解析、Product Graph系はJSDocアノテーションを起点にした統合グラフ。データソースも作り方もバラバラです。
ですが、MCPツールから見た形は揃っています。
- 入口検索: ベクトルあるいは部分一致で「だいたいこの辺」を見つける(揺らぎが許される唯一の場所)
- 詳細取得: IDを指定すれば事実が返る(決定的)
- 関係走査: IDからIDへエッジを辿る(決定的)
- 返却値に次の手の候補を含める: 関連ID、enum定義、注釈、リンク
この3 + 1の形が、Agentic Graph RAGの汎用テンプレートになっています。グラフが違っても、ツールの形が同じだから、AI側からは同じ感覚で使える。Claude CodeはDB Graphを使うときも、Code GraphやProduct Graphを使うときも、同じ「探索→深堀り→走査」のリズムで動きます。
ここで挙げたグラフのうち、深掘りした記事を書けているのはまだDB GraphとBiz Graphだけです。Code Graph、Product Graph系については、それぞれの設計や運用の話を別の記事で書く予定なので、今回は「同じパターンの応用例」として名前だけ並べておくに留めます。
設計のチェックリスト
Agentic Graph RAGを作るときに気にしているポイントを書き出しておきます。
1. ドメインの性質でグラフ構築方法を選ぶ
対象ドメインが社内の暗黙知に強く依存するなら、ノード/エッジの単位は人間が設計するほうが結果が良い。Biz Graphの「Weekノード」「MetricDomain」のように、自然には存在しない構造を意図的に設計することもある。設計が品質を決める。
逆に対象が公知の知識(論文・ニュース・公開ドキュメント等)であれば、構築側もエージェントに自動化させる選択肢が有力です(Neo4jのtalkの系譜)。本記事は前者を前提にした話です。
2. retrievalを決定的にする
入口の探索だけはベクトル類似度で揺らがせていい(自然言語クエリを受けるため)。それ以降の「IDで詳細を取る」「IDから関係を辿る」は、必ずgraph traversalで確定値を返す。ここで類似度を使うとハルシネーションがretrieval層に混入する。
3. ツール粒度は「探索→詳細→走査」で分ける
1つの巨大なツールに全部詰めず、AIが状況に応じて使い分けられるよう分解する。search_* は入口、get_*_detail は深堀り、trace_* / query_* は走査と実データ。AIはこの段階の差を理解して呼び分ける。
4. ツールdescriptionはAI向けのrunbook
ツールのdescriptionは人間ドキュメントではなくAI向けの実行手順書として書く。「この返却を見たら次はこのツールを呼べ」「この場合はこのフォーマットで引数を作れ」まで書き込む。冒頭で紹介した Sandbox MCPの記事でも触れた通り、これがエージェントの賢さを左右します。
5. 返却値に「次の手の候補」を埋め込む
データだけ返すのではなく、
- 関連ID: 次に走査できる先(参照先テーブル、関連施策、上位コミット)
- enum / 列挙: 値の意味をAIが自力で解釈できる定義
- 注釈・警告: DEADフラグ、非推奨マーク、PII(個人情報)マスク
を一緒に返す。AIが「ここからどう進めばいいか」を読み取れる粒度で。
6. 集計・要約はAIに委ねる
サーバ側で「コミュニティ要約」みたいな前処理を頑張りすぎない。AIが複数の事実を組み立てる方が、ケースごとに適切な粒度で要約できる。事実だけ返して、解釈はAIに。
限界と注意点
Agentic Graph RAGが万能というわけではありません。正直に書きます。
- グラフ設計の品質に全てが依存する: スキーマが対象ドメインを正しく切り取れていないと、何回ツールを呼んでも欲しいものに辿り着けない。そして暗黙知に依存するドメインでは、どのノード・エッジを置くかという判断は、結局そのドメインを深く理解している人間にしかできない
- エージェントが入口で迷うと深い穴に落ちる: 最初の
search_*で外すと、その先のグラフ走査も的外れになる。入口検索の質は重要 - コストはツール呼び出し回数 × コンテキスト長: 1セッションで10〜20回ツールを呼ぶと、トークン消費は素直に積み上がる。プロンプトキャッシュとMCPの
progressで可視化していく必要がある - ハルシネーションは消えるわけではなく場所が変わる: retrieval層から「入口の選択」「ストップ判定」に移る。ただし以前より遥かに局所化されているので、デバッグや評価がしやすい
設計者が最も注意すべきは1番目です。特に暗黙知ドメインにおいては、グラフは作るものではなく設計するもの。これはBiz Graphの記事で書いた通りで、こういうドメインに限れば、まったく強調しすぎることはないと思います。
まとめ
時代ごとのRAGをひとことでまとめると、こうなります。
| 時代 | 代表 | 検索 | オーケストレーション |
|---|---|---|---|
| 草創期 | ベクトルRAG | 確率的(cosine類似度) | なし(単発1ターン) |
| Function Calling期 | 古典的Graph RAG | 事前に要約済み | 軽量、ほぼ単発 |
| エージェント期 | Agentic Graph RAG | 決定的(graph traversal) | AIが多段で組み立てる |
ベクトルRAGは「適当に検索して文脈に混ぜる」を実現した。古典的Graph RAGは「関係を辿る検索」を単発で完結できる形にまとめ上げた。Agentic Graph RAGは、「事実だけを正確に返すツール群」と「AIエージェントによる多段オーケストレーション」を分業した。
私たちが社内で作っているDB Graph、Biz Graph、Code Graph、Product Graph系 ── これらはどれも同じ系譜の産物です。グラフの中身も作り方も違うけど、私たちのドメインでは「人間が設計したグラフを、決定的なツールでClaude Codeに渡す」という形に揃っている。だからAIから見ると、どれも同じリズムで使える。
これからAIエージェントを前提にした社内基盤を作る方には、ぜひこの視点を試してみてほしいです。AIに答えを渡すのではなく、AIに地図を渡す。すると、AIはあなたが思っているよりずっと先まで一人で歩いていきます。
そしてその地図の品質は、あなたがそのドメインをどれだけ深く理解しているかで決まる ── 少なくとも、ドメイン知識が暗黙知として人の頭の中にある領域では。こういう領域に関しては、優れたAIシステムは、その領域を最も深く理解している人間が作るんです。AIの時代だからこそ、ドメイン知識の価値はむしろ上がっている。これは私が過去2年、社内のあちこちにグラフを作りながら強く感じていることです。
comments (0)
まだコメントはありません。